Big Data, Crystal Balls and Looking Glasses: Reviewing 2016, predicting 2017

How do big data people go about making end-of-year reviews and predictions? Using data is the obvious answer, but there's a few issues with that approach: there is no synthesis in data alone -- you have to find the story behind data, pick an angle and seek meaning. In addition, that approach does not account for subtle hints, industry knowledge, and big ideas.
To paraphrase Carl Sagan, "we wish to find the truth, no matter where it lies. But to find the truth we need imagination and skepticism data both. We will not be afraid to speculate, but we will be careful to distinguish speculation from fact." In this spirit, let's keep things equally opinionated and objective in 2017.
Hadoop is dead, long live Hadoop. Spark and streaming are here to stay. Image: AtScale
It's the end of Hadoop as we know it, and I feel fine
Hadoop turned 10 in 2016. It's come a long way from a pet project named after a toy elephant to the (metaphorical) stampeding beast now in most every CXO's name-dropping list. The latest Big Data maturity survey showed that 73 percent of respondents are now in production with Hadoop (vs. 65 percent last year). And yet we're here to tell you Hadoop as we know it is dead. And that's not even news.
Hadoop has been constantly evolving, expanding, and re-inventing itself throughout its lifetime. A massive ecosystem has been developing around the initial bare-bones offering, and today Hadoop is more of a platform than "just" a storage and compute framework. The introduction of YARN was a game changer, enabling Hadoop to become a Big Data OS and to break away from its batch-oriented MapReduce origins.
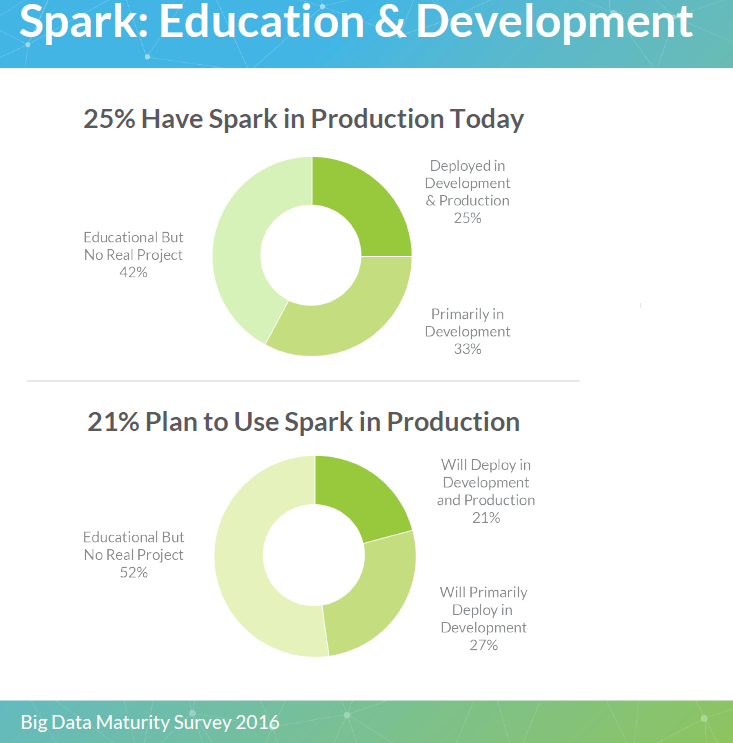
In 2016, data and stories from the trenches all pointed to the same direction: batch, MapReduce Hadoop is dead, long live real-time, Spark Hadoop. 25 percent of organizations are using Spark in production today with an additional 33 percent using it in development, and all major Hadoop vendors are involved in it. Adding up suggests that by the end of 2017 up to 50 percent of organizations could be using Spark in production.
But it's not necessarily a Spark or bust future: neither is Spark the only streaming game in town, nor is Hadoop the only Big Data platform. Alternatives do exist, and users may migrate or leapfrog to them skipping Spark or Hadoop altogether, the same way they are now migrating from or skipping MapReduce.
The Big Data landscape is host to a multitude of different approaches. But more and more it looks like everyone is adding everyone else's features. Convergence or me-too? Image: Martin Kleppmann
Becoming all things to all men to save some
Spark can do both streaming and batch processing. And it can also do SQL, and graphs. And of course on Hadoop you can also do SQL and/or NoSQL in a number of other ways, utilizing a wide choice of tools. That's what being an ecosystem is all about, right? But then again, everyone seems to be at it these days.
NoSQL databases like Cassandra / DataStax Enterprise can now also do graph, in addition to key-value, tabular and document. What about the iconic NoSQL document store - MongoDB? Well, besides document, you can now also do SQL . Microsoft's SQL Server? Your average SQL server no more: it can run on Linux, it supports R, in-memory processing and column store. MariaDB, the poor man's SQL server, also has its column store now.
Neo4J, the iconic graph store? It's going ACID. Google's BigQuery now supports standard SQL , joining Amazon Redshift that has had it for a while as it's based on Postgres. Of course, analytics-oriented column stores have long supported SQL. And traditional relational DBs like Oracle and IBM have been adding features like in-memory processing and column store for a while as well. Key-stores do it, document-stores do it, graph-stores do it, even SQL incumbents do it.
The boundaries are blurring, as more and more data platforms try to be more things to more people. Doing most everything on the same platform is good for vendors that want to increase their retention and good for users who don't want to have to mix and match disparate platforms to get things done. But it's not a sheer land-ho of opportunity - threats lie ahead too. Most notably, vendor lock-in, half-baked features, and half-hearted users.
Some are trying to get the basics right, while some are after up in the sky goals. Yet, there's a place for everyone under Big Data. Image: Martin Kleppmann
Big data hierarchy of needs
So many features, so little time. The cambrian explosion of features is a demand-driven circle: as the infrastructure is proliferating, data generation is booming, early adopters are seeing tangible benefits and use cases are diversifying, which leads to increased demand for features like graph processing or columnar storage that were once the playground of highly sophisticated and/or affluent organizations.
Despite media darling success stories, for most organizations this is probably a bit too much to wrap their heads around at this point. This is understandable, as the pace of change outperforms their ability to digest and keep up with it. As for developers, on either side of the fence (vendor or application developers), both the challenges they are faced with and the stakes are higher.
Of course, none of this is all that new. IDC has called this the 3rd platform, but names aside, we've seen it all before: many riding the wave and few actually getting it, the .com boom and bust, initial resistance giving way to unquestioning convert, more or less successful unification of disparate frameworks in application server environments for enterprises, skill shortage and rock star developers, the long tail for people and organizations alike.
What's different now? The pace of change, catalyzed and accelerated at large by data itself, in a self-fulfilling prophecy of sorts: data-driven product -> more data -> better insights -> more profit -> more investment -> better product -> more data. So while some are still struggling to deal with basic issues related to data collection and storage, governance, security, organizational culture and skillset, others are more concerned with the higher end of the big data hierarchy of needs, like semantics and metadata or new forms of data distribution.
The AI lock-in loop: great investment begets greater results begetting greater investment. Image: Azeem Azhar / Schibsted
Machine Learning gimmicks and Artificial Intelligence for the masses
What could possibly be higher end than Artificial Intelligence (AI)? The connection between seemingly mundane concerns like data integration and data quality and AI may not be obvious at first sight. Upon closer inspection though the link becomes obvious, as there is a progression leading from Big Data to AI. Even though 2016 may be noted as the year in which the end of an AI winter came in sight, the future is certainly not evenly distributed.
The masses are still trying to come to terms with Machine Learning (ML), and everything that comes as part and parcel of being as overhyped as ML has been. Lest we forget - being hyped does not mean not having value, and ML has by and large delivered value. Examples abound - from recommendations to assisting data integration and from detecting fraud to auto-correcting queries. Being hyped however does mean overloading terms with meanings they are not intended or suitable for.
When recently discussing with a number of vendors asked to comment as to whether they see themselves as being, or positioning to become, substrates on which AI applications can be developed, responses varied. Some were clear to state their modest backgrounds and aspirations, some were not dismissive of the idea but were also clear to explain that at this point we are not there yet, while others jumped at the opportunity to reply something along the lines of "sure we do AI - we have this ML stuff".
And what about the next big thing - Deep Learning? That was another overhyped AI-esque data-driven technique in 2016, and again, for good reasons. Is this fundamentally different than ML, in what way, is this something organizations could and should be using today, and if so how and what can they achieve with it? These are all valid questions to which very few people at this point have equally valid answers.
Great, let's all move all our data to the cloud..or maybe, not so fast? Image: AtScale
Data and metadata, in and of the cloud
The tide in attitude towards the cloud for Big Data has turned dramatically, to the point where to question the validity of using it would be to defy conventional wisdom. Alas, the cloud is not always the right answer to the "what should i do with my big data" question. It's not the cure-all for big data issues, and it can even cause a few issues in its own right.
Again, stories from the field and data are in sync: 53 percent of the Big Data maturity survey respondents have at least some data in the cloud today, and 72 percent plan on doing this in the immediate future. But the key here is "some". It does not always make sense to move everything to the cloud - not in a mere "lift and shift" approach anyway.
For applications that need to ingest and act upon streaming data, the cloud is the place. But as data cools down, if it's going to be kept around, it may make more sense to move it to an enterprise data lake, as in the end it comes down to a lease versus buy, opex versus capex argument. There are good reasons for keeping data in the cloud as well: if compute takes place there, as is increasingly the case, spinning clusters and moving data around each time can be a drag. As more Hadoop users are taking their clusters to the cloud, a few gotchas have emerged.
The idea behind the MapReduce paradigm was to have storage and compute co-located to speed up processing. Splitting compute and storage across cloud nodes sort of defeats the whole purpose. In addition, setting up your own Hadoop cluster has never been exactly a joyride, and permanent HDFS cloud storage comes at a cost. And what about fragmentation? HDFS was supposed to unify storage, now going cloud dictates shifting away to proprietary storage like S3.
Cloud-based Hadoop deployments like Amazon EMR or Microsoft HDInsight have their place, and yet vendors like Hortonworks are striking coopetition deals with cloud providers to host managed versions of their distributions. So things are getting meta: it's not only data in the cloud that is of interest, but also data about data in the cloud to help organizations determine how to run their operations.