Four new Google patent apps reflect major search rank methodology changes

This morning, several Google patent applications were published that if enacted, would significantly alter the way that Google figures search rankings.
The four patent applications are:
1 20070094255 DOCUMENT SCORING BASED ON LINK-BASED CRITERIA
2 20070094254 DOCUMENT SCORING BASED ON DOCUMENT INCEPTION DATE
3 20070088693 DOCUMENT SCORING BASED ON TRAFFIC ASSOCIATED WITH A DOCUMENT
4 20070088692 DOCUMENT SCORING BASED ON QUERY ANALYSIS
While I'll leave detailed analysis of these to the Google experts, I would like to dig into #2- DOCUMENT SCORING BASED ON DOCUMENT INCEPTION DATE.
The Abstract reads:
A system may determine a document inception date associated with a document, generate a score for the document based, at least in part, on the document inception date, and rank the document with regard to at least one other document based, at least in part, on the score.
In plain English, that infers an enhancement of Google's ability to rank documents by when they were published- presumably the most recent, first.
That would be welcome, not the least in part because at the present time, Google's ranked search results can integrate documents published a few years ago with those published last week. I've often felt that published date should have more prominence in determining these writings.
GMTA because Google apparently is of like mind.
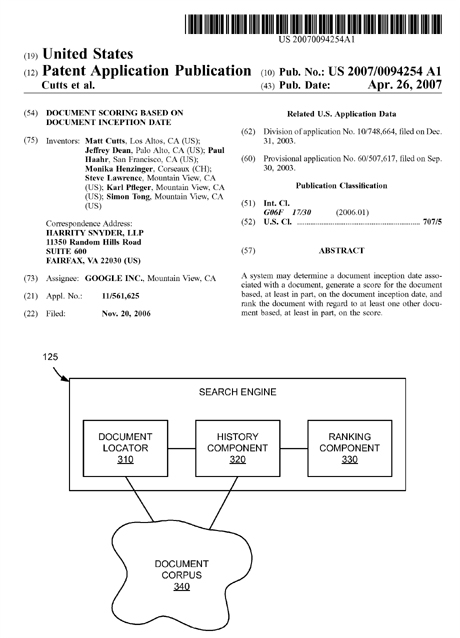
While the Patent application document goes into quite thorough detail about how this standard will be achieved, Figure 3 from the Patent app, as well as its accompanying literature, shows how this will be done. So let's go there now.
FIG. 3 is an exemplary functional block diagram of search engine 125 according to an implementation consistent with the principles of the invention. Search engine 125 may include document locator 310, history component 320, and ranking component 330. As shown in FIG. 3, one or more of document locator 310 and history component 320 may connect to a document corpus 340. Document corpus 340 may include information associated with documents that were previously crawled, indexed, and stored, for example, in a database accessible by search engine 125. History data, as will be described in more detail below, may be associated with each of the documents in document corpus 340. The history data may be stored in document corpus 340 or elsewhere.
Document locator 310 may identify a set of documents whose contents match a user search query. Document locator 310 may initially locate documents from document corpus 340 by comparing the terms in the user's search query to the documents in the corpus. In general, processes for indexing documents and searching the indexed collection to return a set of documents containing the searched terms are well known in the art. Accordingly, this functionality of document locator 310 will not be described further herein.History component 320 may gather history data associated with the documents in document corpus 340. In implementations consistent with the principles of the invention, the history data may include data relating to: document inception dates; document content updates/changes; query analysis; link-based criteria; anchor text (e.g., the text in which a hyperlink is embedded, typically underlined or otherwise highlighted in a document); traffic; user behavior; domain-related information; ranking history; user maintained/generated data (e.g., bookmarks); unique words, bigrams, and phrases in anchor text; linkage of independent peers; and/or document topics. These different types of history data are described in additional detail below. In other implementations, the history data may include additional or different kinds of data.
Ranking component 330 may assign a ranking score (also called simply a "score" herein) to one or more documents in document corpus 340. Ranking component 330 may assign the ranking scores prior to, independent of, or in connection with a search query. When the documents are associated with a search query (e.g., identified as relevant to the search query), search engine 125 may sort the documents based on the ranking score and return the sorted set of documents to the client that submitted the search query. Consistent with aspects of the invention, the ranking score is a value that attempts to quantify the quality of the documents.
In implementations consistent with the principles of the invention, the score is based, at least in part, on the history data from history component 320.
This seems pretty major to me.