IBM DataWorks, a holistic approach to leveraging data

First off, the DataWorks moniker is not new. It has been around for a while, initially used to describe IBM BlueMix Data Integration capabilities. But now DataWorks has been re-purposed as an all-inclusive headline for what IBM touts as the first cognitive data platform.
It's more than just a technological platform, however, so let's take a look at what DataWorks is comprised of.
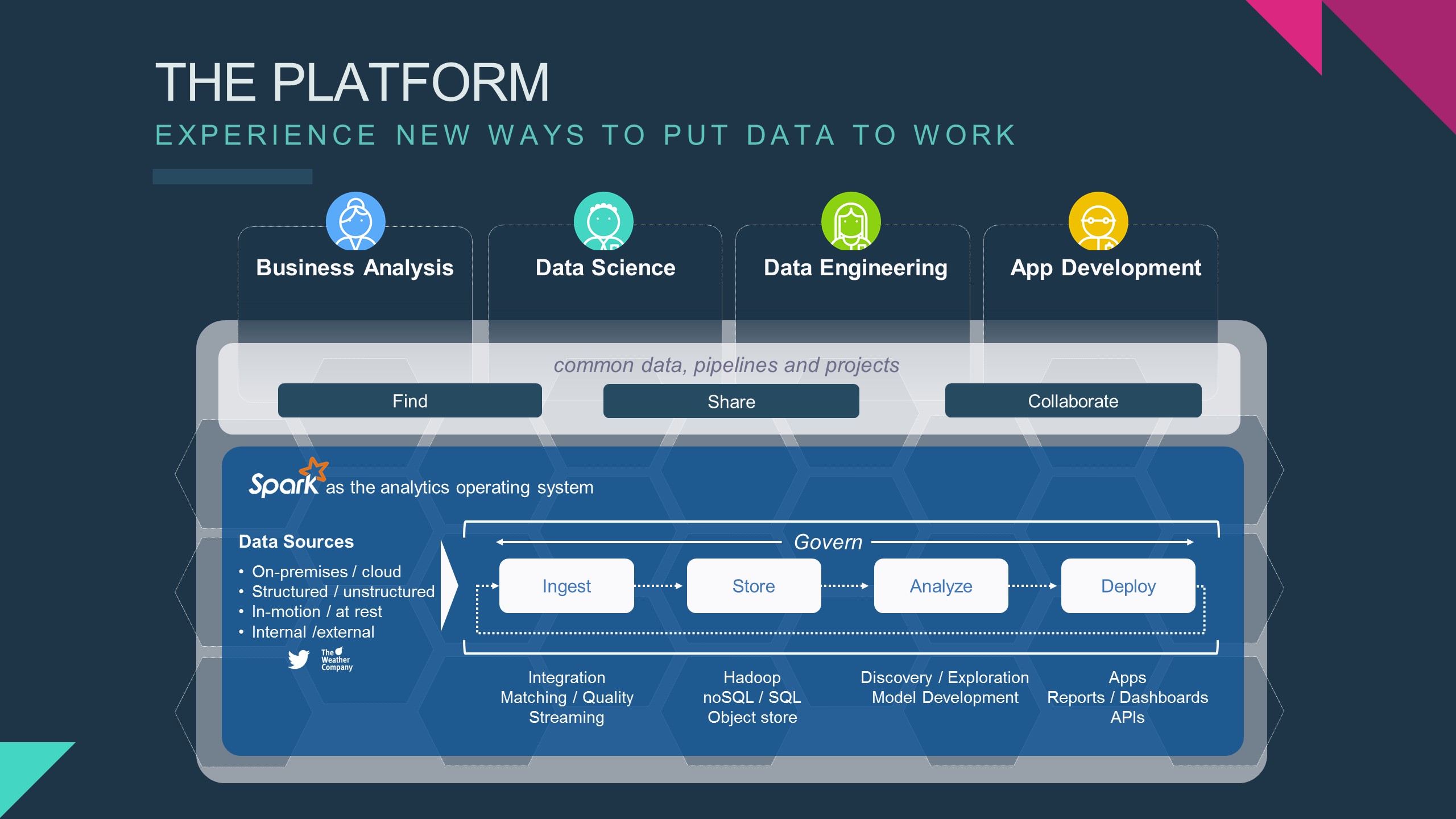
IBM DataWorks platform. (Image: IBM)
The platform
DataWorks leverages two of IBM's greatest strengths, plus an industry darling it has adopted: the BlueMix PaaS cloud, offering advanced services for application development; Watson, IBM's spearhead in advanced analytics and AI capabilities; and Apache Spark, the dominant platform for Big Data analytics. IBM takes pride in being the #1 committer to Spark, while both BlueMix and Watson have been around for a while.
So there's not much new here, except maybe for the way IBM promotes integration of analytics and AI capabilities in everyday applications. This is a trend that has been unfolding for a while, and IBM does not want to be left behind.
IBM says the norm for applications will soon be to incorporate 10-15 external data sources and to use them to offer embedded insights and functionality. So the claim is that by using the DataWorks stack, insights developed for example via an R model can be infused into an application developed on BlueMix, at the click of a button.
In order to do this, massive amounts of data have to be ingested. And this is where IBM makes another claim, that of being the fastest around: "from 50 to hundreds of Gbps". IBM says this stems from IBM Research work that surfaces in their streams technologies.
There are no benchmarks released, (Big Data benchmarks exist, but are not overly popular) so one can speculate that this may be attributed to IBM's cloud alleged superiority over the competition, plus an array of advanced metadata and machine learning techniques applied at ingestion time, such as automated classification of data types and relationships and deep learning to assist in ML model recommendation, iteration, evaluation, and deployment.
Thus IBM promises to assist in cases where clients may not even know what kind of data they have or what their relationships are, empowering citizen data scientists and facilitating collaboration between application developers and data scientists.
But there's also something aimed purely at data scientists under the DataWorks umbrella, namely the Data Science Experience (DSX). This can be described as a combination of a data science networking and discovery tool with a platform that facilitates tasks such as setting up Spark instances and Docker containers.
See also
A method to the madness
IBM sees this not just as a technological journey, but one that entails broader organizational transformation including culture and processes. As such, it has also released a methodology on how to approach this journey, called DataFirst and based on four pillars: Efficiency, Modernization, Democratization, and Monetization. It focuses on helping organizations gain efficiency in data management and modernize their reporting environment.
IBM says DataFirst is centered on time to value and risk mitigation, and they recognize clients have existing architecture and approach this by leveraging proven patterns of deployment, structured workshops and models. DataFirst is comprised of four tracks: Data Management, Data Lake, Data Science, and Data in Action, and is the crystallization of experience accumulated via IBM's service branch.
Even though IBM's own offering in terms of products and services is massive, the latter having in fact contributed to productization, it still can't reach everyone. So this is where partnerships come into play. IBM chooses partners based on criteria that include an ability to embrace open standards and community accepted projects that complement their mission of making data simple. They have announced a series of partnerships including the likes of Continuum Analytics, Galvanize, Alation, NumFOCUS, and RStudio.
Where do we go from here?
So what to make of all this? IBM seems to making strides in the data landscape competition. When looking at the technology itself it may seem like there's not much new there, except maybe for DSX coming out of private beta and a number of under-the-hood automations and integrations on which there are not many details at this point. But that does not mean there's no value in there, even taken in isolation.
By having all of that under the same roof, pre-integrated and with a focus on deriving business value it seems like IBM really means it when it says that the value in data is shifting: it's not about storage, but more about how data can be used with trust and efficiency. With IBM's traditional foothold, it should be well positioned to make a compelling offer for enterprises.
The goal for DataWork is to allow organizations of all sizes - even individual professionals - who work with data to have a frictionless way to start creating value through a collaborative platform. It remains to be seen whether an ecosystem of partners, DataWorks' technological underpinnings and different service plans (self-service & enterprise) can help execute on an a-la-carte strategy to lure clients who are not keen on buying on the entire stack.
This article was initially compiled from publicly available information, including statements from IBM executives Armand Ruiz Gabernet, Rob Thomas, and Ritika Gunnar, and has been updated to include fragments of an email interview with Ritika Gunnar.