Information Commons: A bright star for the future of information

In the eyes of its creators, the World Wide Web was never designed to take on the role as the be-all end-all architecture for a truly distributed global information system. But while large vendors, standards groups and technologists have grown dependent on the Web and treat it that way, some researchers are taking a revolutionary approach to the problem and addressing it at the very core of information design. A newly published white paper from Harbor Research (a firm specializing in pervasive computing), entitled Designing the Future of Information, The Internet beyond the Web looks at two initiatives—the "Information Commons” of Maya Design, and "Internet Zero" from MIT’s Center for Bits and Atoms.
The Information Commons is a universal database to which anyone can contribute, and which liberates information by abandoning relational databasing and the client-server computing model, according to the white paper. It has been under development at Maya Design for over 15 years as the result of a $50 million research contract from several federal agencies, including DARPA, to pursue "information liquidity," or the flow of information in distributed computing environments. Their goal is to build a scalable information space that can support trillions of devices.
I spoke today with Josh Knauer, director of advanced development at MAYA Design about the Information Commons and how it is progressing. According to Knauer, Maya (which stands for Most Advanced Yet Acceptable) is using P2P technology—in the sense of information sharing and not file sharing—to link together repositories of public and private datasets in the public information space created by Maya. These data and data relationships are stored in universal data containers called "u-forms," which are then coded with a UUID, or universally unique identifiers. These are the basic building blocks of the company's Visage Information Architecture (VIA), which allows data repositories to effortlessly link or fuse together to achieve "liquidity" (the paper has more details).
After explaining the technology Knauer gave examples of implementations. The U.S. military’s "Command Post of the Future" (CPoF), a system for real-time situational awareness and collaborative decision-making in use in Iraq, is based on Maya’s architectural and visualization innovations. When hurricanes Katrina and Rita devastated the Gulf Coast recently, the system made its first bridging to the Information Commons as military officials needed to incorporate publicity available EPA data on toxic hazards in affected communities, said Knauer.
(Command Post of the Future screenshot (Credit: Maya Viz)
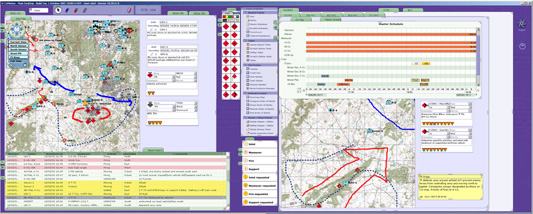
In the public sector, among the several non-profit and goverment agency deployments, Knauer spoke about how Maya combined data from hundreds of government and private-sector sources into the Information Commons to create a location-aware directory of services with always current transit information for the Allegheny County Department of Human Services.
"The biggest area of concern for us now is pushing the debate into the user interface," said Knauer. The more mixing and mashing of information the greater the challenge will be to comprehend it.
Below are some comparisons of the Information Commons to other approaches, according to the white paper:
Google:
But though it is a remarkable achievement, Google remains a blunt instrument, not a precision tool, for dealing with the world’s information. No matter how clever its indexing schemes and searching algorithms, Google cannot get around the fact that the Web does not store information in a fashion conducive to sophisticated retrieval and display. The Web can’t genuinely fuse data from multiple sources, and so Google can’t build an information model that visualizes the answer to a complex, multi-dimensional question.
Semantic Web:
The Semantic Web does recognize the dilemma presented by the Web’s limitations, and it has many passionate proponents—perhaps precisely because it does not propose any particularly radical or disruptive steps. However, the Semantic Web has had very few real-world deployments. Besides being forbiddingly arcane and captive to existing Web technologies, RDF metadata often grows significantly larger than the data it is trying to describe.