Microsoft's PolyBase mashes up SQL Server and Hadoop

I've said it before: Massively Parallel Processing (MPP) data warehouse appliances are Big Data databases. And, as if to prove that point, Microsoft last week announced "PolyBase," a new technology that will integrate its MPP product, SQL Server Parallel Data Warehouse (PDW), with Hadoop.
The announcement was made at the PASS Summit, which is the de facto Microsoft-endorsed SQL Server conference, and one where database administrators (DBAs) dominate the audience. In presenting PolyBase to that audience, Microsoft made it clear that it sees technology and skill sets for Big Data and conventional databases as correlated, rather than mutually exclusive.
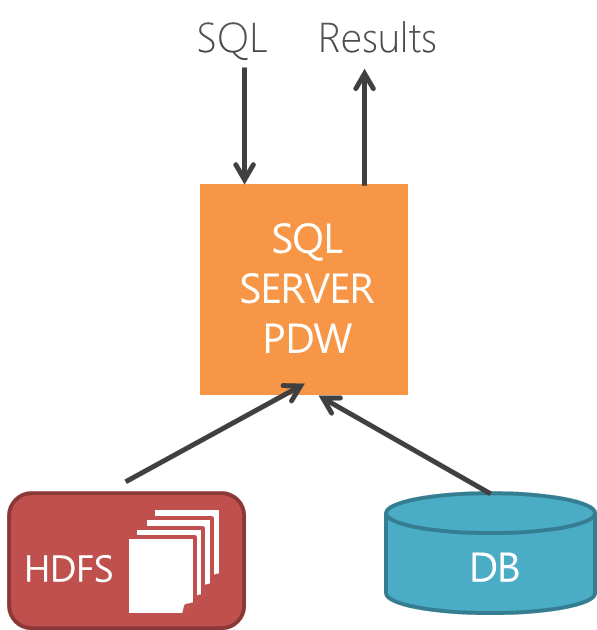
PolyBase will be released in the first half of 2013, as part of the next version of SQL Server PDW and will integrate data in Hadoop's Distributed File System (HDFS) with the relational database engine. Polybase will allow data stored in Hadoop to be queried with SQL (Structured Query Language) and will even allow that data to be joined to native relational tables so that Hadoop and SQL PDW can be queried in tandem, with result sets that integrate data from each source.
You got SQL in my MapReduce…but you're not the first
The PDW/PolyBase combo is not the first product to integrate SQL with Hadoop and/or MapReduce; far from it. Hadapt, Rainstor, Teradata Aster, ParAccel and, most recently, Cloudera have each released products that offer some flavor of this integration. And the Hive component found in virtually all Hadoop distributions provides a SQL-like interface to Hadoop too. But Microsoft's approach is especially interesting, for two reasons:
- While "phase 1" of the PolyBase will implement SQL Query over HDFS, phase 2 will introduce a cost-based optimizer that will also, selectively, utilize MapReduce on the Hadoop cluster instead of SQL, when and where appropriate.
- Although PolyBase will initially appear only in SQL Server PDW, it seems likely that the technology will migrate down to the conventional SQL Server Enterprise product as well.
How it compares
PolyBase has a lot in common with its competitors, but in a mix and match fashion. Like ParAccel's on-demand integration (ODI), PolyBase brings schema/metadata of an HDFS file into the the relational database's own metadata store and allows the Hadoop data to be treated as if it were a local table. Polybase does this in a parallelized fashion, such that PDW's own distributed Data Movement Service (DMS) uses an "HDFS Bridge" to query multiple data nodes in the Hadoop cluster concurrently.
With SQL PDW and PolyBase, the schema is determined and the guest table created using the same SQL command used to create a physical table, but with the addition of "EXTERNAL" before the "TABLE" keyword. From there, whenever the HDFS data is queried, the local SQL query engine fetches the data directly from the data nodes in the Hadoop cluster, which is rather similar to the way Cloudera's Impala works.
- Also read: Cloudera's Impala brings Hadoop to SQL and BI
- Also read: Cloudera aims to bring real-time queries to Hadoop, big data
And while PolyBase can talk to any Hadoop cluster, like Hadapt and Rainstor it can also work such that the relational and Hadoop nodes are co-located on the same equipment (though that would ostensibly require use of Microsoft's own HDInsight Windows-based Hadoop distribution).
MapReduce vs. direct HDFS access
The "phase 1" release of PolyBase and the three competing products just described each bypass Hadoop's MapReduce distributed computing engine and fetch data directly from HDFS. Hadoop distribution components like Hive and Sqoop instead use MapReduce code to extract data from the Hadoop cluster. In general, the translation to, and use of, MapReduce is easier to implement, and the direct HDFS access is considered more efficient and better performing.
But the key word there is "general," because for certain queries it might be much more efficient to offload some work to Hadoop's MapReduce engine, bring the job output back to the relational product and perform join and further query tasks using the latter. Teradata Aster's SQL-H works this way and still allows the kind of heterogeneous joins that PolyBase makes possible (Teradata Aster also allows the relational data to be queried with MapReduce-style code). This approach is especially valuable if the input data set is relatively large, as that would add a huge data movement burden to the query if all work has to happen on the MPP cluster.
That's exactly why, in its phase 2 release, PolyBase will be able to employ both techniques, and will employ an enhanced PDW cost-based optimizer to determine which technique will perform best. To my knowledge, almost none of the relational/Hadoop, SQL/MapReduce hybrids that I have come across combine the HDFS-direct and Hadoop MapReduce techniques; instead they stick to one or the other. The one exception here is Hadapt, but its relational nodes are based on PostgreSQL, and some enterprises might prefer the SQL Server technology used in numerous corporate applications.
Beyond MPP
If Microsoft can pull PolyBase off – such that it runs reliably for production Big Data workloads – it will be impressive. What would also be impressive is the integration of this technology into non-PDW editions of SQL Server, the relational database that is #1 in unit sales and #2 in revenue, industry-wide, according to Microsoft. Granted, all of PDW's competitors are also high-end, appliance-based MPP data warehouse products; anything less and they wouldn't be legitimate Big Data technologies.
But the mash-up of transactional databases and Hadoop is a valid one in certain reporting and other scenarios, and the implementation of PolyBase into non-PDW editions of SQL Server would accommodate it. In his well-attended PASS Summit session on PolyBase, Microsoft Technical Fellow, Dr. Dave DeWitt, who heads the PolyBase team, said this may indeed happen, though he stopped short of promising it.
Promised or not, one thing is certain: when an enterprise- and consumer-oriented company like Microsoft embraces Hadoop, you know Big Data has arrived.
Disclosure: the author of this post was a speaker at this year's PASS Summit and runs a user group in New York City that is a local chapter of PASS.