Three risk categories that explain IT failure

A new white paper from Alpha Software describes three broad categories of risk that explain why software projects fail:
Process failures arise when a project is "bumped off track," relative to the expected plan.
If the goal of a process is to produce a specific outcome, then anything that either delays or prevents the achievement of that specific outcome is a form of process failure. Consider an obvious example of process failure, requirements that are never really (or accurately) determined.
This form of failure usually leads to finger pointing between development groups and users, with each claiming the other did not understand.
[Other examples of process failure involve:]
- Communications (including communications latency)
- Implementing out of date requirements
- Feature creep (or additional features) and its cousin, poorly defined scope
- Bugs (defects)
- Waiting for someone or something
- Partial work
- Context switching
- Unnecessary processes
- Paper shuffling
- Unrealistic schedule
- Unrealistic budget
- Careless, sloppy, or missing software development processes
[T]he presence of one or more of these process failures contribute to business failure if the organization is not able to respond to changing business or market conditions. They also make it difficult to respond to customer-perceived incidents that disrupt service delivery.
Platform failures reflect specific problems with the technology used to develop or deliver software solutions.
The generic term platform applies both to hardware and software individually, and in combination. Some platform failures are also obvious, such as hard disk crashes or network component failure with a corresponding interruption of network traffic. Other examples of platform failure are less obvious, such as when the application does not scale or meet expected levels of performance.Of all the different types of failures, some hardware failures are both the easiest to spot and probably the easiest to anticipate, typically by having spare parts either on-hand or available for just-in-time delivery.
Failures in software platforms (software tools) are more problematic, though they occur frequently enough that they have a name: bugs. It is usually impossible to substitute one software tool for another without a great deal of effort. This becomes particularly onerous if the bug is in a critical tool, and the vendor (or in-house developer) cannot quickly provide either a fix or work-around.
There are also platform failures that can be less obvious to spot, specifically getting close to boundary conditions of the hardware or software including network capacity, balance between physical RAM and swap file, getting close to hard disk space limits, etc.
Business failures refer to issues and problems driven by the internal organization itself.
One of the most obvious forms of business failure also turns out to be the primary reason that development organizations cannot readily adapt to changing conditions: specifically, lack of management commitment. No project can succeed without management commitment (and on occasion, management drive).
[E]xperience [also] suggests an expansion of the concept of business failure to include the notion of tool vendor concerns for the customer value chain. The customer of my customer should be treated like they are my customer. Does the tool vendor do that?
THE PROJECT FAILURES ANALYSIS
The white paper places the risk sources underlying IT failure into three reasonable categories. Nonetheless, for simplicity's sake, I recommend readers combine business and process failures into a single category encompassing both. Importantly, the paper does a good job making the distinction between business and technical causes of failure, and it provides examples of each.
Although the white paper covers no new ground in categorizing project risk, it includes a useful chart showing "the relationship between complexity, calendar duration, and risk:"
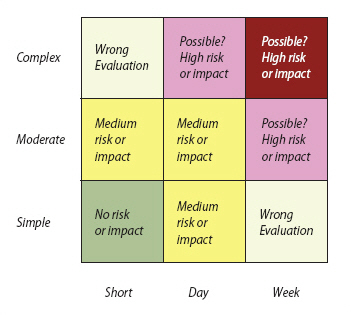
Take a project task, such as developing a particular feature, and map it onto the chart. The grid provides a quick litmus test for evaluating estimates against a consistent framework of risk, complexity, and time. It's a simple, nice, and useful method to perform intuitive risk testing.
Overall, the white paper is worth a read. It won't send off skyrockets in your mind but it's solid, covers good territory, and provides lots of concrete examples.