Welcome to the Data Cloud ?

'The Cloud' is increasingly prevalent in tech conversation these days. Stalwarts of the space such as Amazon and Salesforce go from strength to strength, whilst titans of an earlier model such as Larry Ellison and even Steve Ballmer now seek to appropriate the meme. New blogs like CloudAve play a role in aggregating commentary from near and far.
"Cloud computing is Internet ('cloud') based development and use of computer technology ('computing'). The cloud is a metaphor for the Internet... and is an abstraction for the complex infrastructure it conceals. It is a style of computing where IT-related capabilities are provided ‘as a service’, allowing users to access technology-enabled services from the Internet (‘in the cloud’) without knowledge of, expertise with, or control over the technology infrastructure that supports them. According to the IEEE Computer Society ‘It is a paradigm in which information is permanently stored in servers on the Internet and cached temporarily on clients that include desktops, entertainment centers, table computers, notebooks, wall computers, handhelds, etc.’
Cloud computing is a general concept that incorporates software as a service, Web 2.0 and other recent, well-known technology trends, where the common theme is reliance on the Internet for satisfying the computing needs of the users. For example, Google Apps provides common business applications online that are accessed from a web browser, while the software and data are stored on the servers.”
Perhaps more important than the general preamble, Wikipedia continues;
“As customers generally do not own the infrastructure, they are merely accessing or renting, they can forego capital expenditure and consume resources as a service, paying instead for what they use. Many cloud computing offerings have adopted the utility computing model which is analogous to how traditional utilities like electricity are consumed, while others are billed on a subscription basis. By sharing ‘perishable and intangible’ computing power between multiple tenants, utilization rates can be improved (as servers are not left idle) which can reduce costs significantly while increasing the speed of application development. A side effect of this approach is that ‘computer capacity rises dramatically’ as customers do not have to engineer for peak loads. Adoption has been enabled by ‘increased high-speed bandwidth’ which makes it possible to receive the same response times from centralized infrastructure at other sites.”
So, Cloud computing enables users and developers to call upon computational resources almost at will; resources that it would often be uneconomic for them to assemble and sustain for themselves. It is but a short step from moving your own applications out of your server room and into the Cloud toward more readily embracing applications and components offered there by third parties.
The emphasis for much of this wider discussion remains firmly rooted in the realm of computation and storage. On many levels it’s about offloading the costs of scaling and maintaining local infrastructure, and ‘data’ doesn’t really enter the conversation at all. Something is ‘stored,’ but it’s a nameless, faceless, shapeless something that merely exists in order to be stored or computed upon.
Joining Sunday evening’s usual flow of slightly strange Twitter banter whilst waiting for a child’s bath to fill, I postulated that there might be a useful notion of a 'Data Cloud;' a cloud more closely aligned to the Semantic Web.
UKOLN’s Paul Walk wasn’t so sure, suggesting that we don’t want data to become commoditised. Deepak Singh, too, was initially sceptical, before thinking through the possibilities a little more in an exchange of private messages. Kingsley Idehen seemed resigned to the inevitability of another attempt to make the Semantic Web accessible by means of rebranding.
Disagreeing with Paul Walk, who’d had less time to think it through than I, I’d suggest that we do want and need to see data become commoditised. Not all of it, clearly... but much (most?) of it.
Just as ‘we’ used to duplicate and under-utilise computational resources, so we do something very similar with our data. We expensively enter and re-enter the same facts, over and over again. We over-engineer data capture forms and schemas, making collection exorbitantly expensive, whilst often appearing to do all we can to limit opportunities for re-use. Under the all-too-easy banners of 'security' and 'privacy' we secure individual data stores and fail to exploit connections with other sources, whether inside or outside the enterprise.
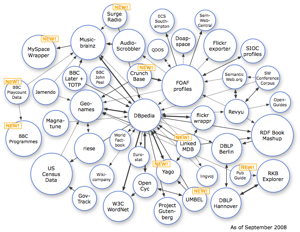
In a small way, the efforts of the Linked Data Project's enthusiasts have demonstrated how different things should be. The cloud of contributing data sets grows from month to month, and the number of double-headed arrows denoting a two-way linkage is on the rise. Even the one-way relationships that currently dominate the diagram are a marked improvement on 'business as usual' elsewhere on the data Web; even in these cases, data from a third party is being re-used (by means of a link across the web) rather than replicated or re-invented. Costs fall. Opportunities open up. Both resources, potentially, improve. The strands of the web grow stronger.
Sir Tim Berners-Lee's Linked Data Design Issues are simple, compelling, and easily applicable.
"The Semantic Web isn't just about putting data on the web. It is about making links, so that a person or machine can explore the web of data. With linked data, when you have some of it, you can find other, related, data.
Like the web of hypertext, the web of data is constructed with documents on the web. However, unlike the web of hypertext, where links are relationships anchors in hypertext documents written in HTML, for data they [are] links between arbitrary things described by RDF. The URIs identify any kind of object or concept."
By sound application of Tim's principles, much more of the background data upon which we make decisions, run processes, and empower applications could surely become a web-accessible commodity, freeing data owners and managers to concentrate upon (and guard, if necessary) the subset of that which they currently manage that is actually unique and valuable to them.
As I wrote in the SemanticReport last year,
"Reliable, cheap and speedy access to data, computational resources, and aggregation and analysis services via the Internet offers opportunities to fundamentally rethink the relationship between corporations and ‘their’ data. Previously considered (to paraphrase Geoffrey Moore) ‘core,’ much of the data collected, maintained and hoarded by the world’s corporations may increasingly be seen as little more than ‘context.’ The value lies in benchmarking these data against trends and metrics derived from your competitors, and in both the innovative analysis you think to undertake and the business decisions you then make as a result. By releasing the corporate grip upon the merely contextual, the pool of knowledge from which core value may be derived grows, as do the opportunities for success."
The link is a fundamental building block of the Semantic Web. Unlike the web of documents, this link does not just point from one 'page' to another, but (potentially) from one 'fact' or item to another, complete with context and rationale. If those links are to have utility outside the lab and beyond the firewall, then that to which they point must also become visible (although not necessarily 'free'). Does the language and rationale of the Cloud assist or obstruct?