IBM Research: Mining for the future of search

How will the IBM vision for intelligent information analysis and unstructured information mining impact the future of search?
The IBM T. J. Watson Research Center is investigating fundamental research issues involved in the automatic extraction of intelligent information from unstructured information such as images, audio, video, rich text, as well as heterogeneous distributed sensor networks. The common goal across all projects is to apply machine learning, signal processing and database techniques to extract information that can be used for accessing the unstructured data at a semantic level. The analysis will help build solutions for semantic enrichment and repurposing of the unstructured data.
The research team is passionate about the challenge and they shared their passion with me today in their labs.
MARVEL is a new multimedia search engine for searching over large video repository using automatically generated semantic labels. The multimedia analysis and retrieval system helps organize the large and growing amounts of multimedia data (e.g., video, images, audio) by using machine learning techniques to automatically label its content.
According to IBM:
MARVEL aims to replace a costly, time-consuming, and error-prone processes of authoring metadata with a semantics machine learning approach. MARVEL works by building statistical models from visual features using the training examples and applies the models for automatically annotating large repositories. The MARVEL process reduces the total cost of creating metadata, reduces annotation errors and allows more effective search and retrieval.
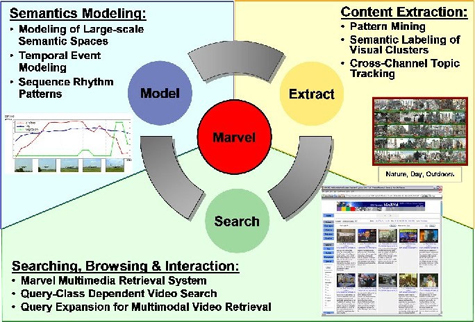
The MARVEL system consists of two components: the MARVEL multimedia analysis engine and the MARVEL multimedia search engine.
The MARVEL multimedia analysis engine – applies machine learning techniques to model semantic concepts in video from automatically extracted audio, speech, visual content. It automatically assigns labels (with associated confidence scores) to new video data to reduce manual annotation load and improve searching and organizes semantic concepts using ontologies that exploit semantic relationships for improving detection performance.
The MARVEL multimedia retrieval engine – integrates multimedia semantics-based searching with other search techniques (speech, text, metadata, audio-visual features, etc.). It also combines content-based, model-based, and text-based searching for video searching.
I was invited by the team to share with them my views on how Web 2.0 will impact the enterprise.
Below is a synposis of my presentation. The full interactive version is here.
SOCIAL CAPITAL THEORY MEETS WEB 2.0
Interactive Presentation Authored by Donna Bogatin
Presented at IBM Research Center by Donna Bogatin, Tuesday, February 6, 2007
Tim Berners-Lee envisaged the World Wide Web as a participatory medium from its origination. The original browser was also an editor and Berners-Lee wanted it to function as a collaborative authoring tool enabling interaction and editing.
Web 2.0 technologies, applications and business models are now sparking user participation and fostering group communication in both the personal and professional spheres. From blogs to wikis to social networking, consumers and businesses are tagging, bookmarking, commenting and sharing for personal expression and community building.
Is the Web 2.0 phenomenon a democratizing force? Are businesses capturing and delivering value through Web 2.0 experiences? Will Web 2.0 flourish in 2007 and beyond?
The impact of participatory media on individuals and within the enterprise is explored in collaborative social fashion via Web 2.0 tools.
READ MORE: Social Capital Theory Meets Web 2.0, by Donna Bogatin
IBM's PATENTS and DR. LIPYEOW LIM
Photo by Donna Bogatin
READ MORE: SOCIAL CAPITAL THEORY MEETS WEB 2.0, by Donna Bogatin