Simple semantic mashups from InfoSpace show possibilities

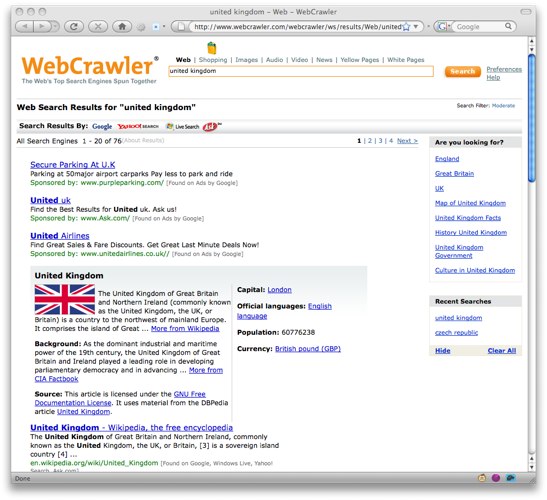
Kris Bradley over at InfoSpace got in touch recently, to show me some of the work they've done to pull content from Semantic Web resources in order to enrich results displayed at webcrawler.com.
According to Kris, the team are pulling information from sources such as DBpedia and the CIA Factbook in order to enrich the basic results.
"To my knowledge [writes Kris], we are the first search site to make use of the data in this fashion, and provide links to the underlying semantic data."
They've begun with countries and cars, and the enriched results can be seen in response to searches such as this or this.
In related news, Yahoo! have tweaked the way in which SearchMonkey-derived enhancements appear within the Yahoo! results page. As of today, a number of those applications will be turned on by default for all users.
As we see more and more Linked Data become available for mashing and meshing in this way, the value of those linkages become ever-more apparent. That both of these examples pull you back to the traditional results page of a mainstream search engine site is merely a factor of the stage we are at in adoption. The capabilities become far more compelling as any application, anywhere is able to enrich itself by means of simple calls to data residing elsewhere in the Cloud.
So what's next? And how do those traditional search engines continue to transform themselves in ways that sustainably deliver these capabilities to the point of need, rather than pulling users back to the site every time?