Open source "Gandiva" project wants to unblock analytics

The key to efficient data processing is handling rows of data in batches, rather than one row at a time. Older, file-oriented databases utilized the latter method, to their detriment. When SQL relational databases came on the scene, they provided a query grammar that was set-based, declarative and much more efficient. That was an improvement that's stuck with us.
But as evolved as we are at the query level, when we go all the way down to central processing units (CPUs) and the native code that runs on them, we are often still processing data using the much less-efficient row-at-a-time approach. And because so much of analytics involves applying calculations over huge (HUGE) sets of data rows, this inefficiency has a massive, negative impact on the performance of our analytics engines.
Bundle up
So what do we do? Analytics platform company Dremio is today announcing a new Apache-licensed open source technology, officially dubbed the "Gandiva Project for Apache Arrow," that can evaluate data expressions and compile them into efficient native code that processes data in batches.
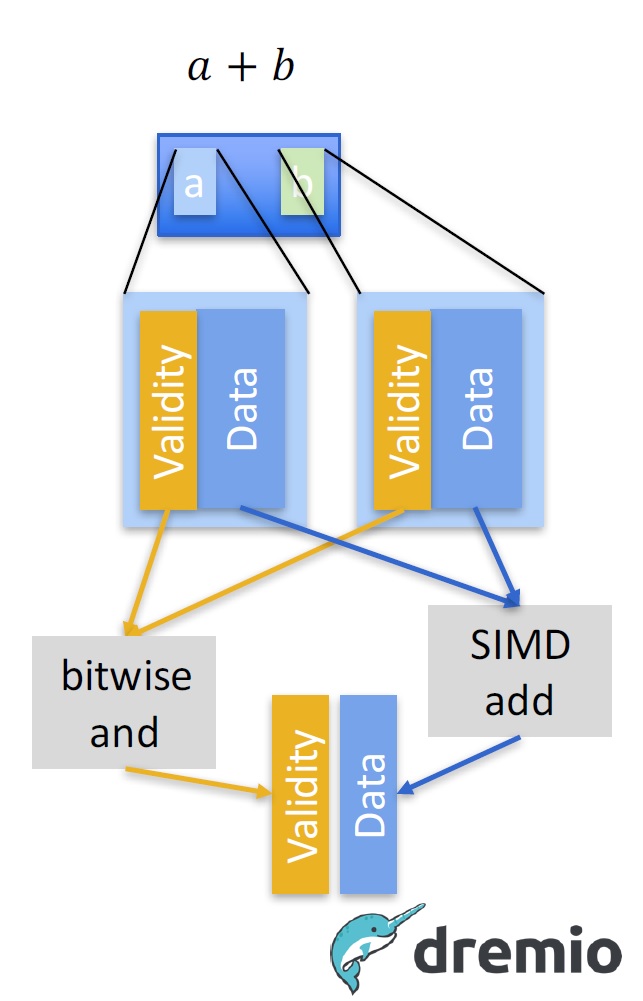
Dremio has been working hard on this problem for a while, actually. Even before the company emerged out of stealth, it captained the development of Apache Arrow to solve one part of the problem. Arrow helps with representation of data in columnar format, in memory. This, in turn, allows whole series of like numbers to processed in bulk, by a class of CPU instructions called SIMD (single instruction, multiple data), using an approach to working with data called vector processing.
Also read: Apache Arrow unifies in-memory Big Data systems
Also read: Startup Dremio emerges from stealth, launches memory-based BI query engine
Efficiency experts
Even though SIMD instructions were introduced by Intel almost 20 years ago, precious little code, to this day, can take advantage of them. But Gandiva's intelligent expression evaluation grooms data for SIMD instructions and vector processing in general. Essentially, Gandiva eliminates conditional tests embedded in expressions from being applied in the row-at-a-time fashion we want to avoid, instead applying them as a sort of post-processing filter.
Gandiva's approach thus allows the core calculations in an expression to be performed in a set-wise manner. This both reduces the number of CPU instructions that must be executed and makes the remaining instructions more efficient. Multiply that optimization by the billions and billions of data rows that we process every day, and the impact could be significant.
Gandiva is SIMD-proud
Gandiva, Arrow and Dremio
Gandiva works hand-in-hand with Apache Arrow and its in-memory columnar representation of data. According to Dremio co-founder and CTO Jaques Nadeau, "Gandiva" is a mythical bow that can make arrows 1000 times faster. In the world of data technologies, Nadeau says that Gandiva can make Apache Arrow operations up to 100 times faster.
Dremio is hard at work integrating Gandiva inside the Dremio product, replacing code which, while ostensibly well-crafted, could not hope to perform as well as Gandiva-generated code. I don't know if there will be a sticker, but the 3.0 release of Dremio will have "Gandiva inside"
Greater Good
But Dremio isn't keeping Gandiva all to itself. It is open-sourcing it with an Apache license, and is encouraging the adoption of Gandiva into other projects and products. Nadeau believes that other technologies -- including Apache Spark, Pandas and even Node.js could benefit from adoption of Gandiva. And Nadeau is working hard to evangelize that adoption.
Nadeau has a good track record there: he's the PMC (Project Management Committee) Chair of Apache Arrow, and was a key member of the Apache Drill development team back when he was at MapR. The Arrow project has the support and participation of a great number of companies in the data and analytics space and is even endorsed by Nvidia through its support of the GPU Open Analytics Initaitive (GOAI), which has adopted Arrow as its official columnar data representation format.
Cross-platform, cross-language
Speaking of GPUs (Graphics Processing Units, used extensivley in machine learning and AI), the Gandiva team plans to support GPUs as target execution environments, even though the project is limited to CPUs today. In general, technology that takes advantage of SIMD instructions and vector processing is often a good candidate for GPU operation as well.
And since Gandiva utilizes the open source LLVM compiler technology, it can generate optimized code for a variety of platforms. That's consistent with Gandiva's goal of of working across products, platforms and programming languages. Gandiva supports C++ and Java bindings today and plans to add support for Python.
Consider this
Is Gandiva, and what it does, fairly geeky and esoteric? Sure. But sometimes such initiatives, when they aim at an industry-wide pain point and gain widespread adoption, can have major impact. If Gandiva can get a whole class of products and projects to take better advantage of vector processing and set-based operation in general, it will be a real service.