OpenAI proposes open-source Triton language as an alternative to Nvidia's CUDA

Graphics processing units from Nvidia are too hard to program, including with Nvidia's own programming tool, CUDA, according to artificial intelligence research firm OpenAI.
The San Francisco-based AI startup, backed by Microsoft and VC firm Khosla Ventures, introduced the 1.0 version on Wednesday, a new programming language specially crafted to ease that burden, called Triton, detailed in a blog post that links to GitHub source code.
OpenAI claims Triton can deliver substantial ease-of-use benefits over coding in CUDA for some neural network tasks at the heart of machine learning forms of AI such as matrix multiplications.
"Our goal is for it to become a viable alternative to CUDA for Deep Learning," the leader of the effort, OpenAI scientist Philippe Tillet, told ZDNet via email.
Triton "is for machine learning researchers and engineers who are unfamiliar with GPU programming despite having good software engineering skills," said Tillet.
The fact that the language is coming from OpenAI, which developed the GPT-3 natural language processing program that has taken the world by storm, may give the code some added preeminence in the AI field.
The software is offered as open-source with the requirement that the copyright notice and permissions be included in any distribution of substantial copies of the code.
Also: The chip industry is going to need a lot more software to catch Nvidia's lead in AI
The original Triton unveiling happened with a paper put out by Tillet in 2019 while a graduate student at Harvard University, along with his advisors, H. T. Kung and David Cox.
The problem Tillet set out to solve was how to make a language that would be more expressive than the vendor-specific libraries for AI, such as Nvidia's cuDNN, meaning, able to handle a wide variety of operations on matrices involved in neural networks; and at the same time be portable and have performance comparable to cuDNN and similar vendor libraries.
Programming GPUs directly in CUDA, according to Tillet and the team, is just too difficult. For example, writing native kernels, or functions, for GPUs "can be surprisingly difficult due to the many intricacies of GPU programming," Tillet and team write in the post.
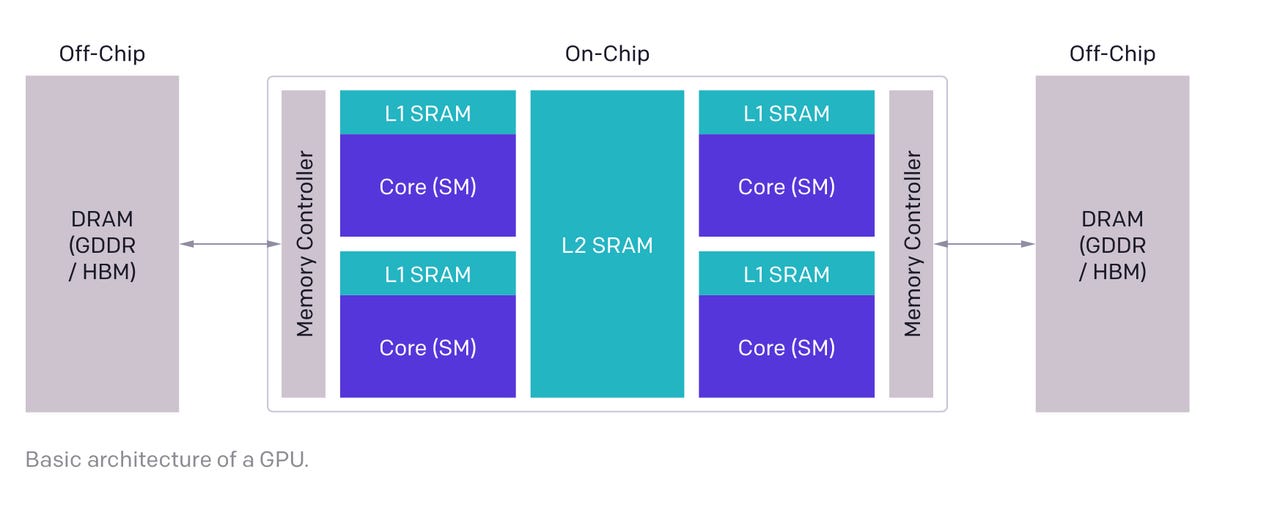
The programming challenge of moving assigning data and instructions across the memory hierarchy of a multi-core GPU.
In particular, "GPUs remain incredibly challenging to optimize for locality and parallelism," as the Triton documentation explains.
But Tillet also wanted the language to be easier to program than custom efforts to date, based on what are called "micro-kernels" that "involve a lot of manual effort." In particular, Triton is presented as an alternative to the two main approaches used in place of vendor libraries, which are called polyhedral compilation and scheduling languages.
What Tillet settled on is an approach called tiles. Tiles, which are used extensively in CUDA programming, take the matrices used in a machine learning program and break them into fragments that can be efficiently distributed across shared SRAM memory and fast register memory and efficiently operated on via multiple threads of instruction in parallel.
However, doing parallelization in CUDA is difficult because of things such as the need to make explicit synchronisation statements between instruction threads of a program.
Triton's semantics specifies tiles as built-in types so that a Triton compiler can do the work of figuring out how those fragments can be efficiently apportioned among the many cores of a GPU and their accompanying registers.
Effectively, the work of parallelizing and optimizing code is pushed from the language down into the compiler.
As Tillet puts it, the compiler "automatically perform[s] a wide variety of important program optimizations."
"For example, data can be automatically stashed to shared memory by looking at the operands of computationally intensive block-level operations."
The instruction flow, from a programmer's coding into the Trition intermediate representation, and then into LLVM compiler intermediate representation, and then into the Parallel Thread Execution, or PTX, that is the low-level language for controlling the GPU.
The Triton programmer's high-level code is first turned into an intermediate representation that is inspired by the intermediate representation found in the open-source LLVM compiler infrastructure. As Tillet described it in the original paper, "just a few data- and control-flow extensions to LLVM-IR could enable various tile-level optimization passes which jointly lead to performance on-par with vendor libraries."
The intermediate representation is then fed to a just-in-time compiler that does the work of fashioning the various matrices into fragments in a way that will optimally fit in the shared memory and the registers of GPU cores.
The JIT organizes threads of instruction inside GPU cores to pull from the same values in the main memory, called "memory coalescing." Likewise, the JIT places data that are of mutual interest to such threads into shared memory for efficient manipulation, known as "shared memory allocation."
As Tillet describes it, the result are programs that are "single-threaded and automatically parallelized." The JIT is doing the work of auto-tuning the tiles, the data fragments, to most efficiently distribute them amongst cores.
In the original Triton paper, Tillet proposed a C-like form of Triton based on the syntax of CUDA. In this new 1.0 release, however, Triton is integrated with Python. The details are spelled out in the blog post.
The benefit of using Triton should be an immediate speed-up in developing some essential operations of neural networks. As Tillet spells out in the blog post, "It can be used to write FP16 matrix multiplication kernels that match the performance of cuBLAS," an Nvidia library that implements the open-source Basic Linear Algebra Subprograms, "something that many GPU programmers can't do -- in under 25 lines of code."
Tillet works on the project full-time at OpenAI, he said, under the supervision of OpenAI's head of supercomputing, Chris Berner. But also has help on the Triton project from several OpenAI staff members.
"Recently, several OpenAI employees and researchers -- all without GPU programming experience -- have contributed code and ideas to the project," Tillet told ZDNet. "We've used it to accelerate and rewrite a large portion of our GPU kernels, and we are committed to making it even more broadly applicable through subsequent releases."
Tillet noted that the project has received "meaningful contributions" from outside OpenAI, including Da Yan of the Hong Kong University of Science and Technology, the team working on Microsoft's DeepSpeed optimization library, and commercial AI startup Anthropic.
Wednesday's blog post does not emphasize performance metrics other than to say that Triton can match CuBLAS. However, in the original paper by Tillet, the Triton-C version of the language was able to get better performance than Nvidia's CuDNN library when running what is called deep convolutions, operations that treat input as groups of locally-related data, such as image pixels.
Note that the software for the moment is only for Nvidia GPUs; it is not yet available for AMD's GPUs, nor will it compile to CPUs. The authors invite collaborators interested in those chips to join the effort.
Also: Graphcore brings new competition to Nvidia in the latest MLPerf AI benchmarks
Tillet's language effort comes at an interesting time for the field of AI hardware acceleration. Nvidia has substantial competition from AI chip and system startups such as Cerebras Systems, Graphcore, and SambaNova. Those companies all have various chip architectures that can apportion parallel computations to multiple on-die cores. SambaNova, in fact, has a so-called data flow architecture for its chip that shares some of the principles of Triton.
However, all of those vendors have had to develop their own software tools to optimize the movement of PyTorch and TensorFlow programs to their computers. In contrast, Nvidia has the advantage of over a decade of development of CUDA and a wide developer base for the software.
It's conceivable that Triton could be one of the new software tools that competition needs to get a broad, open-source platform for their chips.