IBM offers explainable AI toolkit, but it’s open to interpretation

Decades before today's deep learning neural networks compiled imponderable layers of statistics into working machines, researchers were trying to figure out how one explains statistical findings to a human.
IBM this week offered up the latest effort in that long quest to interpret, explain, and justify machine learning, a set of open-source programming resources it calls "AI 360 Explainability."
It remains to be seen whether yet another tool will solve the conundrum of how people can understand what is going on when artificial intelligence makes a prediction based on data.
The toolkit consists of eight different algorithms released in the course of 2018. The IBM tools are posted on Github as a Python library. The project is laid out in a blog post by IBM Fellow Aleksandra Mojsilovic.
Thursday's announcement follows on similar efforts by IBM over the course of the past year, such as its open-source delivery in September of "bias detection" tools for machine learning work.
The motivation is clear to anyone. Machine learning is creeping into more and more areas of life, and society wants to know how such programs arrive at predictions that can influence policy and medical diagnoses and the rest.
Also: IBM launches tools to detect AI fairness, bias and open sources some code
The now-infamous negative case of misleading A.I. bears repeating. A 2015 study by Microsoft describes a machine learning model that noticed that pneumonia patients in hospitals had better prognoses if they also happened to suffer from asthma. The finding seemed to imply that pneumonia plus asthma equaled lower risk, and therefore such patients could be discharged. However, the above-average prognosis was actually a result of the fact that historically, asthma sufferers were not discharged but instead were given higher priority and received aggressive treatment in the ICU, all because they were at higher risk, not at lower risk. It's a cautionary tale about how machine learning can make predictions but for the wrong reasons.
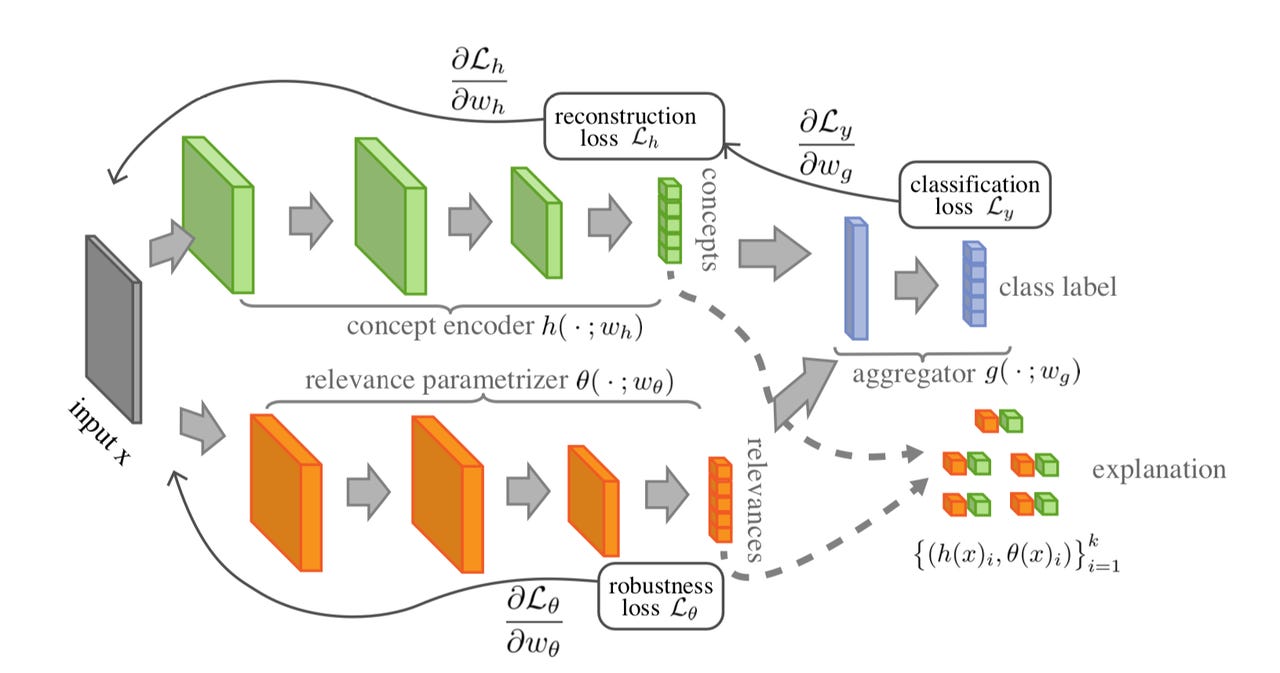
An example of one approach to a "self-explaining neural network" in the IBM toolkit, from the paper "Towards Robust Interpretability with Self-Explaining Neural Networks" by David Alvarez-Melis and Tommi S. Jaakkola.
The motive is clear, then, but the path to explanations is not clear-cut. The central challenge of so-called explainable A.I., an expanding field in recent years, is deciding what the concept of explanation even means. If one makes explanations too simple, to serve, say, a non-technical user, the explanation may obscure important details about machine learning programs. But a complex, sophisticated discussion of what's going on in a neural network may be utterly baffling to that non-technical individual.
Another issue is how to balance the need for interpretability with the need for accuracy, since the most powerful neural networks of the deep learning variety have often gained their accuracy as a consequence of becoming less scrutable upon inspection.
IBM's own researchers have explained the enormous challenge that faces any attempts to explain or justify or interpret machine learning systems, especially when the recipients of said expressions are non-technical clients of the system.
As Michael Hind, a distinguished research staff engineer at IBM, wrote in the Association for Computing Machinery's journal XRDS this year, it's not entirely clear what an explanation is, even between humans. And if accuracy is what matters most, most of the time, with respect to a machine learning model, "why are we having higher demands for AI systems" than for human decision-making, he asks.
An IBM demo of how a denial of home-equity line of credit might be explained to a consumer, from IBM's AI Explainability 360 toolkit.
As observed by research scientist Or Biran with the Connecticut-based A.I. startup Elemental Cognition, the attempts to interpret or explain or justify machine learning have been around for decades, going back to much simpler "expert systems" of years past. The problem, writes Biran, is that deep learning's complexity defies easy interpretation: "current efforts face unprecedented difficulties: contemporary models are more complex and less interpretable than ever."
Also: IBM adding recommended bias monitors to Watson OpenScale
Efforts over the years have dividend into two basic approaches: either performing various experiments to try and explain a machine learning model after the fact, or to construct machine learning programs that are more transparent, so to speak, from the start. The example algorithms in the IBM toolkit, which were introduced in research papers over the past year, include both approaches. (In addition to the Biran paper mentioned above, an excellent survey of approaches to interpreting and explaining deep learning can be found in a 2017 paper by Gregoire Montavona and colleagues of the Technische Universitat in Berlin.)
For example, "ProtoDash," an algorithm developed by Karthik S. Gurumoorthy and colleagues at IBM, is a new approach for finding "prototypes" in an existing machine learning program. A prototype can be thought of as a subset of the data that have greater influence on the predictive power of the model. The point of a prototype is to say something like, if you removed these data points, the model wouldn't function as well, so that one can understand what's driving predictions.
Gurumoorthy and colleagues demonstrate a new approach that homes in on a handful of points in the data, out of potentially millions of data points, by approximating what the full neural network is doing.
In another work, David Alvarez-Melis and Tommi S. Jaakkola come at it from the opposite direction, building up a model that is "self-explaining," by starting with a linear regression that maintains the interpretability of the network as the network is made more complex by making sure that input data points are locally quite close to one another. They argue that the approach makes the resulting classifier interpretable but also powerful.
Needless to say, none of these various algorithms are canned solutions to making machine learning meet the demands of explaining what's going on. To accomplish that, companies have to first figure out what kind of explanation is going to be communicated, and for what purpose, and then do the hard work of using the toolkit to try and construct something workable that meets those requirements.
There are important trade-offs in the approaches. A machine learning model that has explicit rules baked into it, for example, may be easier for a non-technical user to comprehend, but it may be harder for a data scientist to reverse-engineer in order to test for validity, what's known as "decomposability."
IBM has provided some tutorials to help the process. The complete API documentation also includes metrics that measure what happens if features that are supposed to be most significant to the interpretation are removed from a machine learning program. Think of it as a way to benchmark explanations.
And a demo is provided to frame the question of who the target audience is for explanations, from a business user to a consumer to a data scientist.
Even with objectives identified, data scientists will have to reconcile goals of explainability with other technical aspects of machine learning, as there can be serious conflicts. For example, methods such as prototypes or local linear calculations put forward in the two studies cited above can potentially conflict with aspects of deep neural networks such as "normalization," where networks are engineered to avoid problems such as "covariate shift," for example.
The bottom line is that interpretable and explainable and transparent A.I., as an expanding field within machine learning, is not something one simply turns on with the flip of a switch. It is its own area of basic research that will require continued exploration. Getting a toolkit from IBM is just the beginning of the hard work.