Hadoop 2.0 goes GA

The latest open source version of Apache Hadoop, the iconic parallel, distributed, Big Data technology is finally ready to roll.
This version of Hadoop includes the addition of YARN (sometimes called MapReduce 2.0 or MRv2) to the engine. YARN, a typically-silly open source acronym for "yet another resource negotiator" factors out the management components of Hadoop 1.0's MapReduce engine from the MapReduce processing algorithm itself. The MapReduce algorithm is still there, but it is now effectively a plug-in to YARN that can be swapped out for other processing algorithms, including those that run interactively, rather than using a batch mode of operation.
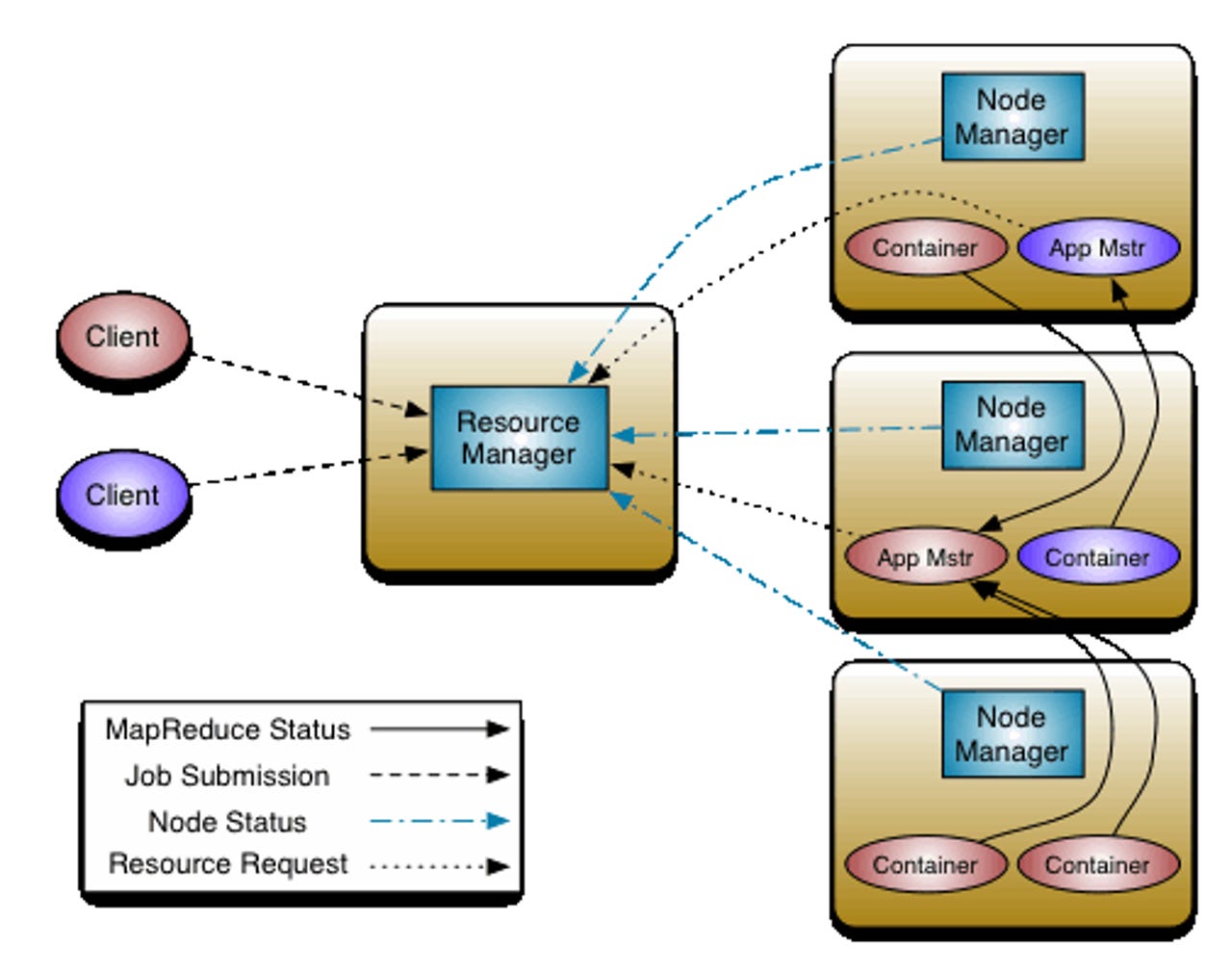
Some major distributions of Hadoop, such as Cloudera's Distribution including Apache Hadoop (CDH) already included YARN, but were in fact using what the Apache Software Foundation considered pre-release code. But YARN and Hadoop 2.0 are pre-release no more.
Arun C. Murthy, the release manager of Apache Hadoop 2.0 and Founder of Hortonworks, had this to say: "Hadoop 2 marks a major evolution of the open source project that has been built collectively by passionate and dedicated developers and committers in the Apache community who are committed to bringing greater usability and stability to the data platform."
Just yesterday, the Apache Hive project also released a new version (0.12.0), for full compatibility with Hadoop 2.0. Hive, which allows for SQL queries against data in Hadoop, is currently based on the MapReduce algorithm. But now that Hadoop 2.0 is fully released, look for a corresponding production release of Apache Tez (incubating) and Hortonworks' Stinger Initiative (projects on which Murthy also provides leadership), which extend Hive to use YARN for direct SQL querying of Hadoop data, bypassing the MapReduce algorithm completely.
It's not all about YARN though. Hadoop 2.0 also sports the following features:
- High Availability for Apache Hadoop HDFS (the Hadoop Distributed File System)
- Federation for Apache Hadoop HDFS for significant scale compared to Apache Hadoop 1.x.
- Binary Compatibility for existing Apache Hadoop MapReduce applications built for Apache Hadoop 1.x.
- Support for Microsoft Windows.
- Snapshots for data in Apache Hadoop HDFS.
- NFS-v3 Access for Apache Hadoop HDFS.
That's not a bad manifest. Honestly, this is a very exciting day in the world of Big Data, as Hadoop will morph into more of a general-purpose Big Data operating platform and less of a rigid tool that must be programmed directly.
And, hey, MapReduce, don't let the door hit your butt on the way out!