AI processors go mobile

At its iPhone X event last week, Apple devoted a lot of time to the A11 processor's new neural engine that powers facial recognition and other features. The week before, at IFA in Berlin, Huawei announced its latest flagship processor, the Kirin 970, equipped with a Neural Processing Unit capable of processing images 20 times faster than the CPU alone.
The sudden interest in neural engines is driven by the rise of deep learning. These specialized processors are designed specifically to crunch the complex algorithms used in artificial neural networks faster and more efficiently than general-purpose CPUs.
This trend is already having a profound impact in the data center. Nvidia's graphics processors for games have found a second life as accelerators for training these complex models. Microsoft is now using hundreds of thousands of FPGAs (field-programmable gate arrays) to power many of its services, and will soon make that available to other customers through Azure. Google took things a step further and built its own Tensor Processing Units, and there are plenty of start-ups pursuing the same idea.
And now neural engines are migrating to the edge. Today most of the heavy lifting is done in the cloud, but there are some applications that require lower latency. The most obvious examples are embedded applications such as autonomous vehicles or smart surveillance systems where decisions need to made in near real-time. But over time the number of AI applications that can benefit from local processing, such as Apple's Face ID, is likely to grow.
This is especially challenging in mobile devices because of the power limitations. Chipmakers are adopting different strategies to address this problem.
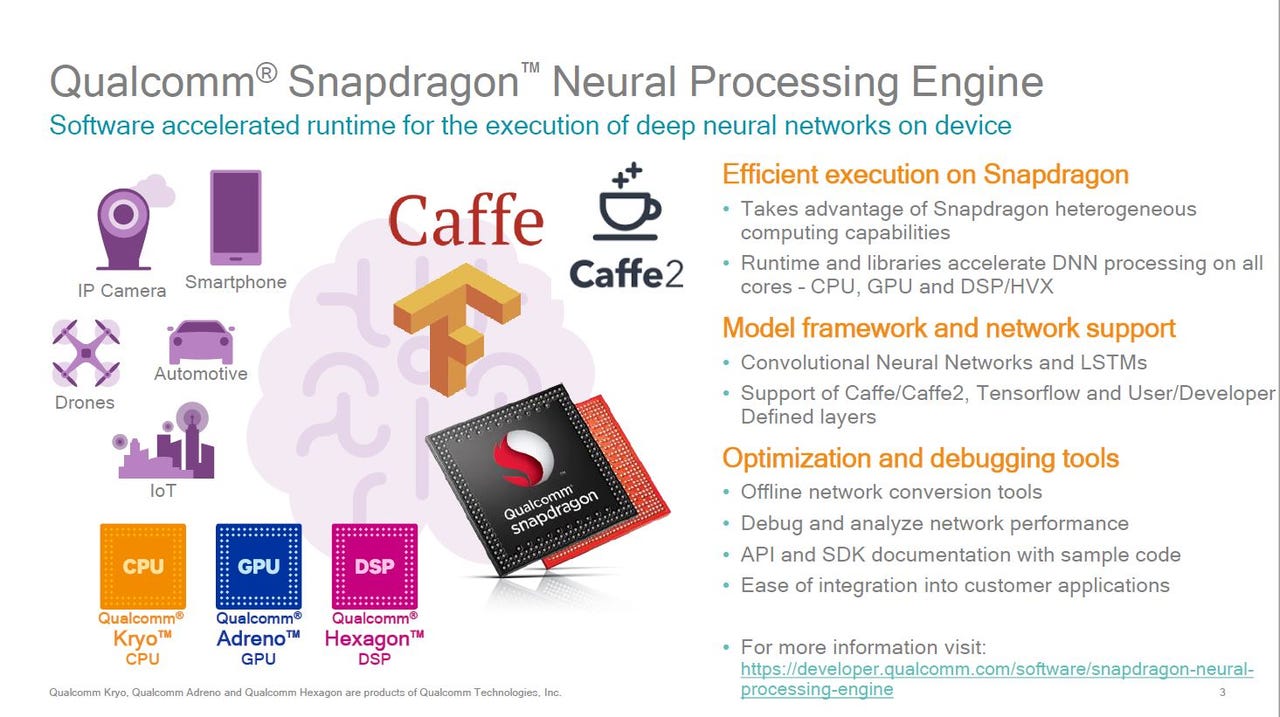
Qualcomm's strategy--at least in the short term--is take full advantage of all the resources that are already crammed onto its Snapdragon mobile SoCs. The company has been experimenting with novel hardware for about a decade, but Gary Brotman, Director of Product Management at Qualcomm Technologies and head of AI and machine learning, said it discovered that rapid advances in the CPU, GPU and Hexagon DSPs have largely eliminated the short-term need for specialized hardware for tasks such as computer vision and natural-language processing.
Qualcomm's Snapdragon Neural Processing Engine (NPE) is a set of software tools that takes models trained in Caffe, Caffe2 or TensorFlow (32-bit floating point) and converts them into Qualcomm's format to run across the Kryo CPU (32-bit FP), Adreno GPU (16-bit) or Hexagon DSP (8-bit integer) in Snapdragon 800 and 600 series processors. The company also has math libraries for neural networks including QSML (Qualcomm Snapdragon Math Library) and nnlib for Hexagon DSP developers.
The closest thing that Qualcomm currently has to specialized hardware is the HvX modules added to the Hexagon DSP to accelerate 8-bit fixed operations for inferencing, but Brotman said that eventually mobile SoCs will need specialized processors with tightly-coupled memory and an efficient dataflow (fabric interconnects) for neural networks. "For now it isn't critical, at least in mobile and on the edge, but in the coming years there will be need for dedicated AI hardware," he said. Over the next year or so Qualcomm will be focused on speeding up inferencing, but the next step with be "getting devices to learn."
Competitors are already devoting part of the die to neural processing. Apple and Huawei are the most prominent recent examples, but the Samsung Exynos 8895 that powers the Galaxy S8 and Note 8 in many parts of the world has a Vision Processing Unit that the company says speeds up motion detection and object recognition. Ceva, Cadence Tensilica, Synopsys and others offer processor IP designed to speed up convolution neural networks for image recognition at the edge.
Intel's strategy is to provide a complete AI ecosystem that spans from the data center to edge. The company notes correctly that Xeon servers are involved in nearly all training and inferencing workloads (though Nvidia Tesla GPUs provide most of the flops on for training large models). Later this year it will release Knights Mill, a derivative of the current Knights Landing processor that it says will deliver four times the performance of the Xeon Phi 7290 due to two new features, support for quad FMA (fused-multiply add) instructions and variable precision.
This will be closely followed by Lake Crest, a co-processor based on an entirely different architecture from last year's acquisition of Nervana. Amir Khosroshwahi, the CTO of Intel's AI Products Group (and co-founder and former CTO of Nervana Systems) describes Crest as a" distributed, dense linear algebra processor" designed specifically to run dataflow graphs. While Intel hasn't shared many details yet, we do know that this consists of a tile of small tensor cores with lots of on-die memory (SRAM) in a multi-chip package with four 8GB stacks of second-generation High-Bandwidth Memory. On its own the Nervana engine will deliver a boost a in training performance, but Khosroshwahi said the real key is how performance scales across multiple chips using a proprietary interconnect that Intel has previously said will be 20 times faster than PCI-Express.
Through its $16.7 billion acquisition of Altera, Intel now has a leading position in FPGAs for inferencing. Microsoft is the pioneer here and at last month's Hot Chips conference, it talked about how its Project Brainwave "soft DPU" (DNN processing unit) with a 14nm Stratix 10 FPGA will deliver "real-time AI" with a peak performance of 90 teraops using Microsoft's limited-precision format. Intel is packaging Skylake Xeon Scalable processors with FPGAs using its proprietary EMIB (Embedded Multi-Die Interconnect Bridge) 2.5D technology. The company has made two other acquisitions to expand its AI edge portfolio including Israel's Mobileye, a leader in ADAS and autonomous driving, and Movidius, which has a vision processor that delivers more than one teraflop using less than one watt of power. This week Intel announced that Alphabet's Waymo was using its Xeon CPUs, Arria FPGAs and WLAN and WWAN connectivity chips in its latest self-driving vehicles.
One obvious issue with these different approaches is that there is no standard. There are many deep learning frameworks (Caffe, TensorFlow, Torch and PyTorch, Microsoft's Cognitive Toolkit) for training and running models, and they rapidly evolving. And the hardware underneath is heterogeneous and is becoming more specialized.
This isn't a problem for Google or Microsoft--they can design their own hardware and software to deliver particular services. But it is a big challenge for developers who want to create accelerated applications that can run neural networks across all mobile devices. Facebook seems particularly preoccupied with this problem. It has previously open-sourced the Caffe2Go framework for mobile devices and at its recent @Scale conference, the company was demonstrating how OpenGL could be used to speed up image recognition and special-effects on a phone, but as EE Times notes, the API is old and hard to program.
There's clearly a need for some mobile inferencing standards and ARM has taken some steps in this direction with its Compute Library with OpenCL and Neon. But in the near team, this is likely to remain a land rush as chipmakers vie to deliver the best solutions for deep learning. "It's too early to say when things will net out from a standards point," Qualcomm's Brotman said. "It will take some time for things to settle down to a steady state."