Amazon cloud down; Reddit, Github, other major sites affected

Another day, another Amazon outage, it seems, taking down half of the Web with it -- and it's getting worse, according to the cloud provider's status pages.
The retail turned cloud giant is suffering with issues on the U.S. East Coast, specifically in Amazon's North Virginia data center, after the firm's cloud began to fall from the sky.
The firm's EC2 operations appear to be the main source of the outage, according to Amazon's status page. Dubbed "performance issues," Amazon has yet to call the "outage" card. But since this article was written, the troubles appear to have spread to other parts of the data center.
At first the Elastic Compute Cloud crumbled and the Relational Database System soon after, but then spread through the data center to hit ElastiCache services.
At 4:00 p.m. PT, when this article was last updated, only Amazon ElastiCache was back up and running. Amazon CloudWatch was also operating normally, but customers may experience "intermittent metrics delays" from RDS services.
Amazon Relational Database Service (RDS) was at the last update still struggling, but was "recovered [in the] the majority of... instances." Amazon Elastic Compute Cloud (EC2) had recovered "half of the volumes" experiencing issues, but was "continuing to work" on the rest of the volumes.
Dozens of major websites that rely on Amazon's Web Services have fallen off the face of the public Web as a result of the outage, including the usual suspects, such as pseudo-social network Pinterest along with check-in giant Foursquare and online travel service Airbnb.
News sharing site Reddit fell down for hours, though others like code-sharing site Github was back online shortly after a brief hiccup. Many other significant startups remain offline. Highly addictive block-building game Minecraft also crumbled thanks to the Amazon data center outage, while users of Heroku, which was acquired by Salesforce in December for $212 million, became inaccessible during the downtime.
Technology and business magazine FastCompany noticed a traffic drop to zero during the first stages of the outage, according to chief technology officer Matt Mankins who tweeted this picture:
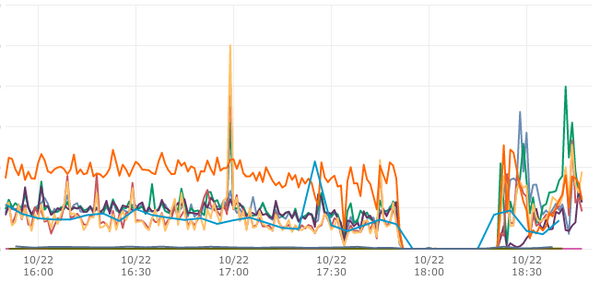
So far, Amazon has not said anything publicly about what has happened. It's probably too early to tell. Regurgiating what's on the status update page (which you can also see here), here's what we know:
Amazon Elastic Cloud Computer (EC2):
10:38 AM PDT: We are currently investigating degraded performance for a small number of EBS volumes in a single Availability Zone in the US-EAST-1 Region.
11:11 AM PDT: We can confirm degraded performance for a small number of EBS volumes in a single Availability Zone in the US-EAST-1 Region. Instances using affected EBS volumes will also experience degraded performance.
11:26 AM PDT: We are currently experiencing degraded performance for EBS volumes in a single Availability Zone in the US-EAST-1 Region. New launches for EBS backed instances are failing and instances using affected EBS volumes will experience degraded performance.
12:32 PM PDT: We are working on recovering the impacted EBS volumes in a single Availability Zone in the US-EAST-1 Region.
1:02 PM PDT: We continue to work to resolve the issue affecting EBS volumes in a single availability zone in the US-EAST-1 region. The AWS Management Console for EC2 indicates which availability zone is impaired.
2:20 PM PDT: We've now restored performance for about half of the volumes that experienced issues. Instances that were attached to these recovered volumes are recovering. We're continuing to work on restoring availability and performance for the volumes that are still degraded.
3:25 PM PDT: Were continuing to work on restoring performance for the volumes that are still degraded.
Amazon Relational Database Service (RDS):
11:03 AM PDT: We are currently experiencing connectivity issues and degraded performance for a small number of RDS DB Instances in a single Availability Zone in the US-EAST-1 Region.
11:45 AM PDT: A number of Amazon RDS DB Instances in a single Availability Zone in the US-EAST-1 Region are experiencing connectivity issues or degraded performance. New instance create requests in the affected Availability Zone are experiencing elevated latencies. We are investigating the root cause.
12:53 PM PDT: We have recovered a number of affected RDS instances and are working on recovering the remaining impacted RDS DB instances a single Availability Zone in the US-EAST-1 Region. New instance creation requests in the affected Availability Zone continue to experience elevated latencies.
2:48 PM PDT: We continue to work to resolve the issue affecting RDS instances in a single availability zone in the US-EAST-1 region. We have recovered the majority of the RDS DB instances in the affected AZ and are working to recover the remaining affected DB instances. RDS DB instances in other availability zones in the region are operating normally.
Amazon ElastiCache:
11:39 AM PDT: We are currently experiencing connectivity issues for ElastiCache Cache Nodes in a single Availability Zone in the US-EAST-1 Region.
1:08 PM PDT: We have recovered a number of affected cache nodes and are working on recovering the remaining impacted cache nodes in a single Availability Zone in the US-EAST-1 Region.
2:01 PM PDT: We are continuing to work on recovering connectivity to remaining small number of impacted cache nodes in a single Availability Zone in the us-east-1 Region.
3:32 PM PDT: We are continuing to work on resolving intermittent network connectivity issues to a small number of cache nodes in the impacted availability zone in US-East-1 region.
3:46 PM PDT: We have restored connectivity to cache nodes in the impacted availability zone. The service is operating normally.
Amazon Web Services Elastic Beanstalk:
11:06 AM PDT: We are currently experiencing elevated API failures and delays launching, updating and deleting Elastic Beanstalk environments in the US-East-1 Region.
11:45 AM PDT: We are continuing to see delays launching, updating and deleting Elastic Beanstalk environments in the US-East-1 Region.
2:05 PM PDT: We are continuing to see delays launching, updating and deleting Elastic Beanstalk environments in the US-East-1 Region.
At 4:00 p.m. PT, when this article was updated, there was no change in this status. Any changes can be seen at Amazon's status pages.
Amazon is reported increased CloudSearch error rates in search and documents, as well as CloudWatch delays to metrics for Amazon's Relational Database Service (RDS), Elastic Load Balancing (ELB), and ElastiCache in the North Virginia data center. However, Amazon reported an "operating normally" status at 2:08 p.m. PT.
At 3:45 p.m. PT, Amazon also reported that customers who were experiencing elevated error rates with the EC2 Management Console are now "operating normally".
At this point it remains unclear as to what caused the problems seen today. It's unlikely to be the weather, mind you, as it's a mildly warm day with sunny spells in Northern Virginia where the data center is located.
The last two major outages were in quick succession during the early summer.
In June, a major outage hit numerous high profile websites, including Quora, Foursquare, and even Dropbox for a time. Amazon's post-mortem of the outage led engineers to believe the power supply was to fault. In a nutshell, the firm's generators "overheated and powered off" because a cooling fan failed to kick into action.
A series of other unfortunate mishaps led to the cloud-collapse, leaving many without access to their favorite websites or enterprise Web applications for hours.
In July, however, bad weather and thunderstorms initially caused the outage at the troubled North Virginia data center -- which continues to be the root cause of the series of unforeseen outages -- but a series of unseen bugs in the firm's technology led to a prolonged period of downtime. One of the affected data centers failed to switch over the power to backup generators, and the uninterruptible power supply (UPS) ran out of juice.
Amazon did not respond to requests for comment.