Apache Arrow unifies in-memory Big Data systems

In-memory data systems have have had a panache for several years now. From SAP HANA to Apache Spark, customers and industry watchers have been continually intrigued by systems that can operate on data directly in memory, bypassing the slowness of disks and the sequential read rubric of file systems. Whether or not in-memory is always the best way to go, it's usually a crowd-pleaser.
In fact, most modern BI systems use their own in-memory engines that also store the data in a column-wise fashion. Doing so allows for high rates of compression, because data for a given column across rows will often be the same, or very close, in value. This, in-turn, allows more data to fit in memory at once.
Common approach, varied implementation
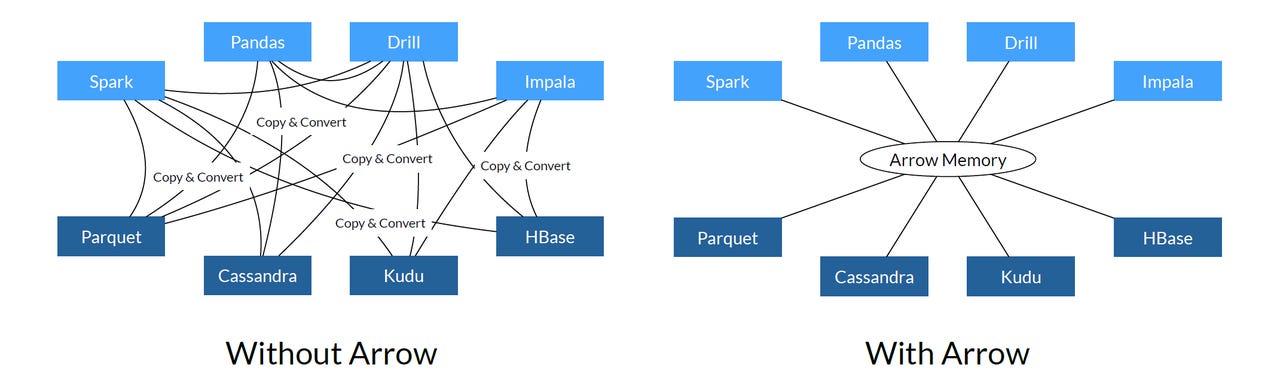
There's wide consensus around the columnar, in-memory approach but, ironically, this makes for inefficiencies, because almost every analytics product, be it commercial or open source, uses its own representation for columnar, in-memory data. This makes moving data between these products and their sub-systems especially inconvenient, as the data must be translated from one in-memory representation to something more universal, and then into the next product's proprietary representation. If the data is irregular or hierarchical in structure, the problem gets even worse.
In the world of software, whenever you can find pain points that are common and point solutions used to alleviate them, there is great opportunity to establish a standard, drive adoption of it, and eliminate massive amounts of duplicated effort. This is exactly what the Apache Arrow project aims to do for in-memory representation of Big Data.
Commonality, codified
Arrow is not an engine, or even a storage system. It's a set of formats and algorithms for working with hierarchical, in-memory, columnar data and an emerging set of programming language bindings for working with the formats and algorithms.
Arrow is the collaborative work of lead developers (Program Management Committee Chairs, Co-Chairs and project Committers) of the following 13 open source Big Data projects: Calcite, Cassandra, Drill, Hadoop, HBase, Ibis, Impala, Kudu, Pandas, Parquet, Phoenix, Spark and Storm. Ostensibly because of the collective braintrust and community behind these "feeder" projects, Arrow will skip the normally prerequisite Incubator phase, where a project's efficacy is vetted, and go directly to top-level project status under the Apache Software Foundation umbrella.
Jaques Nadeau, co-founder and CTO of stealth startup Dremio, as well as Program Management Committee (PMC) Chair of Arrow itself, briefed me on Arrow last week. Nadeau, who is also PMC Chair of Apache Drill, explained that before year-end, Drill, as well as Impala, Kudu, Parquet, Ibis and Spark, will be "Arrow-enabled." Other open source projects are expected to follow and, when I asked Nadeau if commercial projects would also jump on the Arrow bandwagon, he sounded optimistic.
Partying on the data
Once multiple projects adopt Arrow, they will be able to share data with little overhead, since the data won't need to be serialized and deserialized between multiple proprietary, in-memory data formats. For systems installed on the same cluster, sharing the memory on each node, the data need not move nor transform at all.
Instead, different projects and products can pipeline together, each taking turns working with the data, in a cumulative fashion. And because the Arrow formats are optimized for modern CPU architectures, on-chip cache storage can be optimized as can Intel vector/SIMD (Single Instruction Multiple Data) instructions, which work on multiple data values simultaneously, in a single CPU clock cycle.
Featured
Developers can get in on the action too. Initially, language bindings will be available for Java, Python, C and C++, allowing developers in those languages to make their applications participate in the same pipelines as the Arrow-aware Big Data projects. Bindings for R, Julia and JavaScript should be available soon.
Desperately seeking standardization
Will all this goodness bear fruit? Can such a collaborative process really work? Well, as Nadeau tells the story, the leaders of the 13 projects have already been working together, not just on the technology, but on keeping it mostly confidential until now. That's at least a good omen.
I've been pretty vocal about the fragmented state of Big Data technology and Apache projects. The amount of competitive, duplicated effort that we've seen in the open source Big Data space is inefficient, and it makes the selection of technology an experience that is full of risk and trepidation for customers. That inhibits adoption and deployment of the technology and hurts the analytics industry overall.
A project like Arrow addresses that very criticism, making various technologies inter-operate and perform better. It reduces complexity and frees up resources to work on unique functionality instead of reinventing technology that should be common among projects. That's the power of a standard. And with it, Apache Arrow could very well be a victory for common sense in the Big Data arena.