Apache Spark: How Hortonworks aims to fire up the in-memory engine

Hadoop software and services firm Hortonworks says the plans it outlined today for Apache Spark are designed to make the in-memory engine a better candidate for enterprise use.
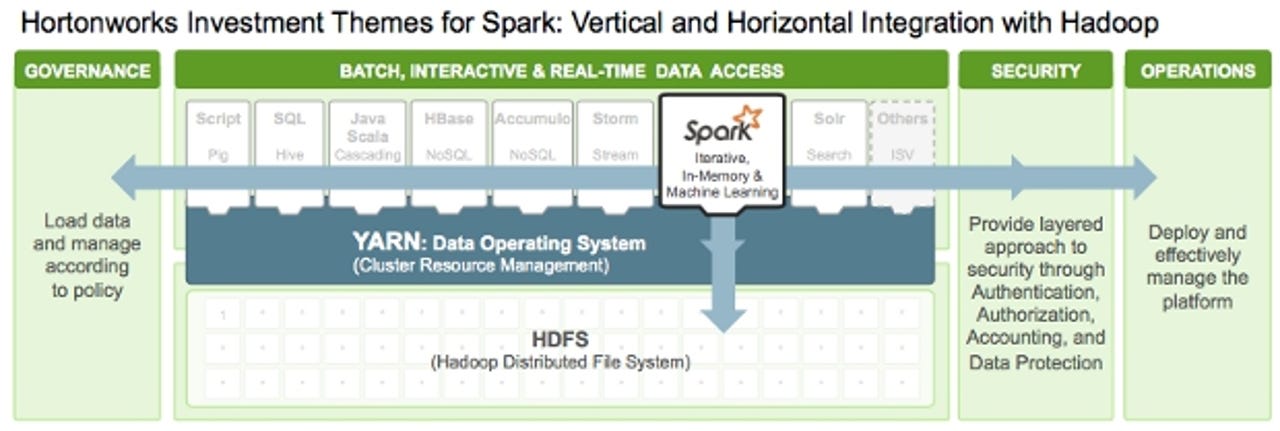
The company is focusing its efforts on improving the way Spark works with Hadoop's YARN resource-management layer and on providing the engine with better governance, security and operations.
The goal of integrating Spark more deeply with YARN is about enabling it to operate more efficiently with other engines, such as Hive, Storm and HBase, on a single data platform and remove the need for dedicated Spark clusters.
According to Hortonworks, it will continue its policy of contributing the results of these initiatives back to the Apache Hadoop open-source project.
"Spark is one of the most interesting things that has come out of the open-source community and it's a testament to both the resilience of the Hadoop ecosystem and the Apache open-source community that we're seeing all these innovations," Hortonworks co-founder Arun Murthy, who has worked on Hadoop since its creation in 2006, said.
"Memory is getting cheaper. We have customers who are now easily running 100GB or so on every box, which means if you stitch together 10 or 20 of these machines, then you suddenly have a terabyte or two of RAM.
"In those scenarios it's very appealing for the data scientist to come in and say, 'I'll do fast interactive analytics and write some algorithms like machine learning and modelling and iteration with a framework like Spark'. That's why Spark is so alluring, particularly to the next generation of developers."
What adds to that appeal is Spark's Scala API, given the scripting language's role as a Lisp-like functional programming language for mathematics.
"Put together that Scala is a good language for math, and for people who think in terms of math, and the fact that you have enough memory in terms of the evolution of the hardware," Murthy said.
"When I started off in Hadoop, our servers would have about 4GB to 8GB of RAM per box. That was state of the art at that point. Today it's not 4GB or 8GB; it's 128GB or 256GB of memory. So Spark is the right technology at the right time."
Although a lot of the interest in Spark is currently coming from data scientists engaged in machine learning, Hortonworks is keen that the framework functions well when a business is running multiple workloads.
"If you look at the overall context of data, that's why we've had this idea of YARN as this data operating system and to have all your data in Hadoop," Murthy said.
"Then, whether it's the data scientist using Spark, whether it's an analyst using Hive, or a programmer or developer using a NoSQL database, all these people can come to one place and use YARN to mediate among the many engines that you'll have within the same context."
This objective is illustrated by the work Hortonworks has been involved in on improving the integration between Spark and the Apache Hive data warehouse software and its ORC binary file format.
"If you do your ETL and put your data in ORC format, so that you can query it efficiently using Hive, now the data scientist who wants access to this data can have a similarly good experience processing these files via Spark," Murthy said.
On the security front, Hortonworks says it is investing heavily in ensuring Spark works smoothly on a secure Hadoop cluster and meets customer demand for authorisation with LDAP or Active Directory before access is granted to the Spark Web User Interface.
Hortonworks is also trying to address what it describes as the less than ideal way Spark on YARN uses cluster resources.
"Today what currently happens is the Spark deployment model in YARN looks more like a long-running service, where you come in, grab a bunch of memory on these boxes and run," Murthy said.
Tech Pro Research
"That deployment model is great if you're doing interactive analytics and iterations but it's not so good if you're doing batch because if you're doing batch you might want to access a lot of resources at one point and fewer resources at a later point. You have these ebbs and flows in your application.
"So what we've done is we're proposing an alternative execution or deployment model for Spark for batch where Spark can now start to use some of the native features available in the Hadoop platform, whether it's the Hadoop shuffle in YARN, which allows you to transfer intermediate data.
"We want to use the Yarn shuffle, we want to use some of the advances we made in a similar project to Spark, Apache Tez, and actually leverage investments in both places.
"We can use the two of these and give our overall enterprise users a significantly good experience so that they can get a high utilisation and high throughput for their batch applications through Spark."
Murthy said Hortonworks' initiatives for Spark employ the same approach that it has already successfully applied to emerging technologies, such as distributed computation framework Storm and high-throughput distributed messaging system Kafka.
"We've had a number of customers using all these technologies early on. They opt into the programme and we spend time with them to understand the areas that we as an enterprise software vendor have to focus on to make it really rock-solid," he said.
"What we're doing now is announcing the result of this programme, which we want to go ahead and pull into the core Apache Spark project. Then we can comfortably support it."
More on Hadoop and big data
- Big data: Still dogged by security fears but Europe's catching up
- DataStax sets out how Apache Cassandra benefits from $106m funding boost
- Teradata acquires Hadoop consulting firm Think Big Analytics
- From Hadoop's earliest days to post-YARN: Why some issues just won't go away
- Beefed-up Couchbase Server 3.0 beta targets developers and admins
- Pivotal and Hortonworks collaborate on Ambari for enterprise Hadoop
- Hadoop's Tez: Why winning Apache's top level status matters
- Developers or their bosses: Who really picks the database?
- Hadoop security: Hortonworks buys XA Secure – and plans to turn it open source