Unsecure directory on PHP.net contains Blu-ray movies, usernames and passwords, and more
PHP, utilized by millions of Web sites around the Web, has a not-so-hidden secret on their Web site: a directory full of pirated content, config files containing user name and password information, and more.
Update: The directory has now been taken care of; however, for the time being, Google's cache of the directory remains intact.
It's interesting what a night of advanced Google querying can yield. On the heels of running across USA Today's prototype Windows 8 application in a designer's profile (thanks to advanced querying), I've now stumbled upon a directory on PHP's official Web site that contains a number of pirated Blu-ray movie rips, config files with user names and passwords, games, music, and more.
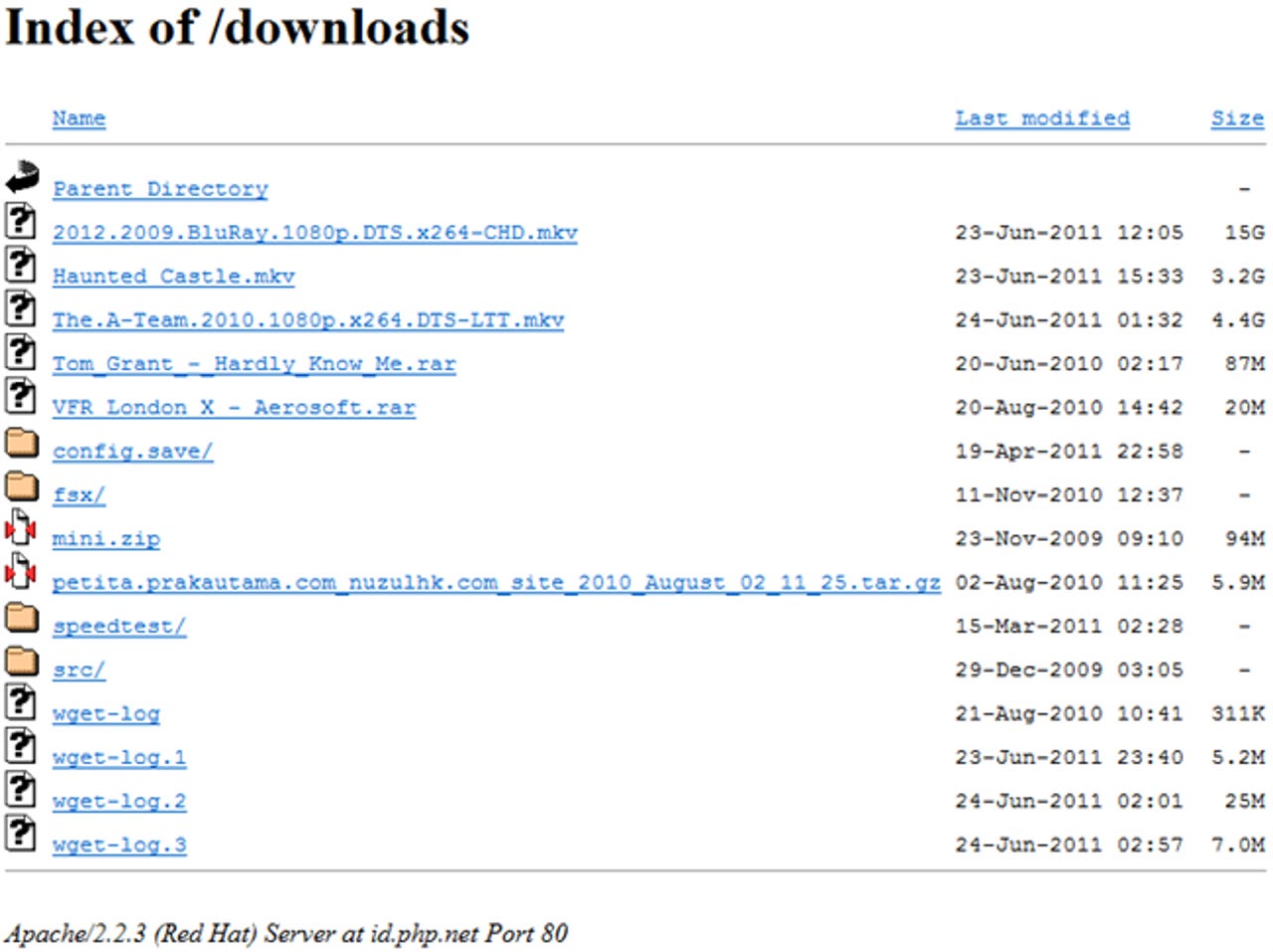
If you like CSI or taking part of investigative research, you're going to love this post. I'm not just going to show you the directory, but I'm also going to break down how I found it, how things like this get found and indexed by Google, and I'll shore it all up with key takeaways. But before I delve into all of that, let's begin with a screen shot of the directory for quick reference:
Now, as you can see, the most obvious files within the directory are the Blu-ray titles and music albums. Admin types will quickly notice the wget logs and the folder titled "config.save" -- both, containing telling information, as you would expect. The directory "fsx" contains a copy of Microsoft's Flight Simulator X and the rest of what you see there is source content for Web sites.
So, where did this directory come from and how did Google find it to index? After all, this is obviously a directory that wasn't meant for public consumption. Well, put simply, a link to this directory has been posted in some form or fashion, somewhere on the Web. But how do we find out where that is? Sometimes, you simply can't... but that won't stop us from trying! First, Google provides an operator that shows us sites that link to an address you specify. Since the directory we're interested in is "id.php.net/downloads/", we'll try that operator (link:) to see if we can find any sites that link to it by leveraging the following query:
link:id.php.net/downloads
Hmm. That returned no results, so let's remove "/downloads" from the query and see what that does:
link:id.php.net
That didn't return any relevant results, either, but why? Well, it could be due to a number of factors -- anything from "nofollow" (which basically tells Google, "I don't want you to pass any link juice to this site from my site" on any links you specify as "nofollow" on your site); to link: operator fickleness; to Google simply not wanting to show every site in their index that another site is linked to from.
With that in mind, let's try searching for the URL residing on other sites as a textual string instead. It's completely possible that a link to this directory may well reside on PHP.net's site somewhere, but we'll start this leg of our investigation by excluding results from php.net:
"id.php.net/downloads" -site:php.net
Looking through the results, we see numerous sites that contain the text "http://id.php.net/downloads.php" on them. That's not *quite* what we're looking for, but let's visit that URL to see if it redirects to "http://id.php.net/downloads/", which could be the answer to our question.
Nope! It does redirect, but to a page completely unrelated from what we've discovered. Continuing down the list of results in Google, we finally come to a result yielding a rather interesting URL structure: http://id.php.net/downloads/src/redhat/RHEL_5.5/x86/rhel-server-5.5-i386-dvd.iso
This is quite promising, so let's look at the cached version of the page in the results. Doing a CTRL + F to bring up a search box in the browser, searching for id.php will take us right to the spot on the page. Is Google smart enough to recognize a URL in textual format, parse it, and try to crawl it? Absolutely. But before we call it a day, let's go back over to the search results to see what else we find.
Ah, yes. In the search results, we see a result with the following link: http://id.php.net/downloads/src/redhat/
Let's visit the cached version of that page and once again do a CTRL + F to search for id.php and locate it on the page. What do we see? A hyperlink! This looks like a much more likely candidate for how Google found its way to the id.php.net/downloads directory, because Google found this site, crawled it, saw that hyperlink, followed it, then crawled that directory. And because the index in that URL contains a link to "parent directory," *everything* that's not 403d (or hidden/access denied) within id.php.net/downloads is now able to be discovered by Google -- thus, index-able by Google.
Now, viewing the source code of the page that hyperlink was discovered on, we see no signs of "nofollow." Theoretically, that means that performing the link:id.php.net search query *should* have shown this page as a result. But all it really means is that the link: operator is extremely fickle, or Google simply doesn't want us to see very much when using the link: operator. Or a little of both.
Most of you won't know this, but we've actually lucked out in terms of finding some good examples of how this directory may have been discovered by Google. There are plenty of other scenarios for why this directory could currently exist in Google with all traces to it having disappeared. For instance, the Web site that Google initially discovered the directory on could have been nixed and Google updated its index to reflect as such. Or, Google could have found its way to that directory from a hyperlink using anchor text like "click here," yet deciding not to return that site in a link: query.
Interestingly, other *.php.net sub-domains that I tried all redirected properly, such as http://us3.php.net/downloads.php and http://us3.php.net/downloads, so why has this one slipped through the cracks? Also, the config files in the config.save directory contain some easily-decrypt-able (for those who know how) information within them -- all of which is cached in Google. This serves as an example that -- in some cases -- your data can end up exposed to others in the most unpredictable of ways. Lastly, a peek at the wget files in Google's cache reveals the source of the pirated content residing in that directory: http://linux1.hk.psn.net.id/~buset/
Overall, this was a pretty big find -- especially for one that happened by chance. As of this moment, the contents of that entire directory (including its sub-directories) are indexed by Google, so even if the admins over at PHP.net nix access to the directory directly, they will still have to wait for Google's index to reflect the change. To note, this directory appears to be publicly accessible since at least 2009. The picture below from archive.org shows a snapshot of the directory from May 30, 2009:
And with that, I'll wrap up this post. As you can see, it's surprisingly simple for an otherwise private section of a site to be indexed in Google when a file within such a directory is linked to somewhere discoverable and crawl-able. To note, I'm planning to start a weekly series where I reveal directories I find that contain pirated content sitting on people's personal and professional Web sites. I want to show just how commonplace these instances really are and I hope the awareness I create will be significant.
In the mean time, be sure to check out part one and part two of my "search ninja" series to learn for yourself how to discover such wondrous results in Google and other places! Additionally, have a look at the related posts below to read my other case studies that expose data via in-depth Google querying. Thanks for reading!
-Stephen Chapman SEO Whistleblower