Xerox scanners alter numbers in scanned documents

When set in the non-default 'Normal' image quality mode, some Xerox scanners and photocopiers may change characters, including numerals, in scanned documents.
UPDATE: Xerox has posted a blog entry by Rick Dastin, corporate vice president and president, Office and Solutions Business Group on the scanning issue. The company emphasizes that this affects few customers, only those who use the scanning functions after changing the quality/compression settings. Customers affected by the problem can change the setting back to defaults. Alternatively, Xerox will, in the next weeks, be rolling out a software update to the devices that will '…disable the highest compression mode thus completely eliminating the possibility for character substitution.'
The initial finding of this problem was made earlier today by German researcher D. Kriesel. Kriesel demonstrated that on a Xerox WorkCentre models 7535 and 7556 scans of certain documents with numbers in them resulted in the numbers being different in the paper and scanned image. He suggests several possible implications for users:
- Incorrect invoices
- Construction plans with incorrect numbers (as will be shown later in the article) even though they look right
- Other incorrect construction plans, for example for bridges (danger of life may be the result!)
- Incorrect metering of medicine, even worse, I think.
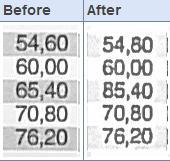
Kriesel lists many other devices which he says are affected, but which he has not personally tested himself. He also provides many examples. The images in this story were provided by him.
In response to Kriesel, Xerox issued a statement indicating that the problem was due to settings changes in the device:
The problem stems from a combination of compression level and resolution setting. The devices mentioned are shipped from the factory with a compression level and resolution that produces scanned files which are optimized for viewing or printing while maintaining a reasonable file size. We do not normally see a character substitution issue with the factory default settings however, the defect may be seen at lower quality and resolution settings
The company attributes the problem to the JBIG2 compressor software in the device. In the 'Normal' setting image compression is tuned to produce smaller files at the expense of image quality. With the 'High' setting, the JBIG2 compressor is not used, and the device emphasizes image quality over file size.
Xerox confirmed for me that 'High' is the default setting in the device and Kriesel confirmed for me that the test device was configured to 'Normal.' Kriesel suspects that the reseller from whom the device was purchased made the change.
Around the time Xerox was issuing their statement, Kriesel posted a second blog entry discussing the quality setting. At this point he seemed unaware of the default settings issue. Kriesel tells me, and also says in the second blog entry, that Xerox tech support was unhelpful and obviously unaware of this issue. He says he first contacted them on July 25.
But it turns out the problem is not news to Xerox's developers. As shown in an image in Kriesel's second post, there is a warning in the user interface for changing image quality:
The normal quality option produces small file sizes by using advanced compression techniques. Image quality is generally acceptable, however, text quality degredation and character substitution errors may occur with some originals.
Kriesel explains repeatedly that OCR was not used in any of these cases. The transpositions were made purely in image scans. Clearly the Xerox software still attempts, in such cases, to recognize objects.
In a final blog post, Kriesel summarizes his communications with the Xerox and concludes that the worst part of the problem was support's lack of familiarity with the character substitution errors.
Even if the nature of the issue is settled, it leaves the question of whether it is acceptable that a device configured in a permitted way such as this should be capable of such behavior. It turns out that Xerox does provide a fairly clear warning, but it's equally obvious that neither customers nor their own tech support knows about the problem. As Kriesel himself says, it's impossible to know how many important errors have been made because of this bug.