Is IBM making enterprise mashups respectable?

ZDNet blog colleague Joe McKendrick beat me to the punch earlier this week with an excellent analysis of the fascinating ramifications of IBM's recent statements at the New York PHP Conference aimed at mainstreaming mashups and Web 2.0 technologies. If IBM is getting seriously involved in this, there must be something to it, and certainly Rod Smith's comments are receiving considerable attention.
Interestingly, most enterprises I talk to these days barely have mashups on their radar, yet I also continually hear from those same folks about how hard it is to create increasingly integrated business applications, as well as the slow pace of rolling out new functionality to users and customers. There indeed seems to be a rising corporate appetite for faster, more effective ways of building applications particularly when reusing existing IT software and information assets.
Despite all the attention in leading edge tech circles, there is still a general lack of knowledge about what mashups are, never mind so-called enterprise mashups, the unique obstacles to which are articulated succinctly here by Phil Wainewright. The question I get asked most frequently about this space, however, is what the exact difference is between composite applications and mashups.
One big difference? Composite applications – those supposedly elegant marriages of the resources of a SOA into brand new software that is more an assembly of existing components than "green field" development – don't have to be Web-based. Mashups do. Then there is the increased formality of composite applications, which are typically based on SOAP Web services and frequently woven together with BPEL and developed by professional programmers. Composite applications also tend to use an older generation of programming languages and technologies that have more overhead and ceremony. And, almost certainly too much exposed plumbing and infrastructure.
Read IBM's analysis of claims of 10-to-1 productivity improvements for Ruby on Rails over Java for developing Web-based software
On the other hand, mashups use almost remkarably simple, basic techniques for connecting things together. This includes guerilla-style development techniques that deliver results in preference to formal, upfront engineering. This might mean using Javascript includes of another site's software, straightforward Web services and feeds based directly on top of HTTP, and JSON for data retrieval and remixing. And with initiatives like OpenAjax, we might get first real conventions for component interoperability in the browser.
Like so many aspects of Web 2.0, the term "mashup" is poorly defined and a generally accepted definition probably does not exist today. The term itself, as applied to the informal fusion of Web services and browser-side Javascript, is so new that it only made it into Wikipedia in mid-September, 2005, less than a year ago.
A question of what's being mashed up
At the root of what a mashup is the the question of what's being "mashed" together into something new. Is it data? Is it visual presentation? Is it the underlying functionality (code)?
The answer of course is that a mashup could be all of these things, or just one of them. In the end, mashups are intentionally loosely defined because of their very nature as ad hoc aggregations of whatever needs to be aggregated. Whether that is visuals, information, or working software is immaterial to the term's application.
That most mashups today only make a couple of key connections between underlying services or software, such as Housingmaps, is besides the point; mashups are clearly useful but much of the work today still has to be done by hand (i.e. by developer.)
But this state of affairs seems to be sparking the imagination of entrepreneurs. An increasing number of companies such as Bridgewerx, Kapow, Worcsnet, and others are trying to solve (or partially solve) the problem of requiring programming skills to create mashups. This means mashups will become much more end-user directed in the near future as facilitation techniques become more sophisticated. They will be created by almost anyone for just-in-time situations and projects, and even thrown away when their usefulness ends. This is a new view of software that says that there is a long tail of demand for situational applications that just don't warrant large investment. However, their cumulative value could be quite considerable as they tap pent-up needs that could not be satisfied in a cost effective way until now.
This leads us to a key definitional point. Are mashups purely browser-based or are they fundamentally Web-based and could reside as easily in a Web browser or Web server?
I would assert that this is manifestly the case; mashups can exist anywhere on the Web, either primarily on the server as Zillow or diggdot.us are or entirely on the client side like so many of the Google Maps mashups are. Mashups connote a mindset of informal techniques that just work by virtual of the concept of "small pieces, loosely joined". Examples of this include the unassuming RSS feed, which provides essential yet very basic structure to data, is very widely understood and used, and doesn't control the conversation or require any complex processing to interact with.
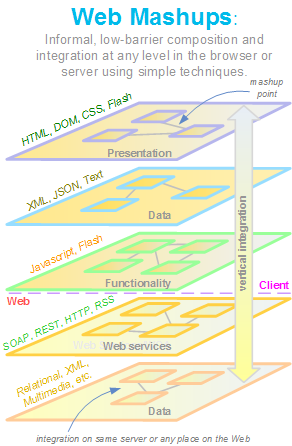
The 5 styles of mashups
Accepting that information, visuals, and software can be remixed and combined at multiple levels in an application stack means that there are (at least) five places that mashups can take place. These five styles are:
- Presentation Mashup: This is the shallowest form of mashup in the sense that underlying data and functionality don't meet. Information and laout is retrieved and either remix or just placed next to each other. Many of the Ajax desktops today fall into this category and so do portals and other presentation mashup techniques.
- Client-Side Data Mashup: A slight deeper form of mashup is the data mashup which takes information from remote Web services, feeds, or even just plain HTML and combines it with data from another source. New information that didn't exist before can result such as when addresses are geocoded and display on a map to create a visualization that could exist without the underlying combination of data.
- Client-Side Software Mashup: This is where code is integrated in the browser to result in a distinct new capability. While a component model for the browser is only now being hashed out as part of Open Ajax, there is considerable potential in being able to easily wire together pieces of browser-based software into brand new functionality.
- Server-Side Software Mashup: Recombinant software is probably easier right now on the server since Web services can more easily use other Web services and there are less security restrictions and cross domain issues. As a result, server-side mashups like those that in turn use things like Amazon's Mechanical Turk or any of the hundreds of open Web APIs currently available, are quite common.
- Server-Side Data Mashup: Databases have been linking and connecting data for decades, and as such, they have relatively powerful mechanisms to join or mashup data under the covers, on the server-side. While it's still harder to mashup up data across databases from different vendors, products like Microsoft SQL Server increasingly make it much easier to do. This points out that many applications we have today are early forms of mashups, despite the term. Of course, the more interesting and newer aspects of mashups happen above this level.
Of course, the real potential in all of this is as IBM's Rod Smith says:
[Mashups put] more capability into an individuals hands and gives them more freedom to innovate -- and because Web 2.0 technologies are based on open standards, integrating them into an open business model is easy for end users and developers alike.
And the reality is today that the infrastructure, both in terms of organizations recognizing and support the value of this approach, as well as real tools for creating, deploying, and managing enterprise mashups are lacking. Despite this, he Global SOA is happening right in front of us, the question is how to deal with licensing, governance, and all the problems that SOA in the small has already taught us.
Finally, like James Governer observed recently in response to IBM's enthusiasm for this approach compared to older, more traditional middleware and EAI methods, "lightweight mashups on the other hand really do have potential to allow business users to create interesting data and service manipulations."
Are you seriously considering ways of using increasingly rich landscape of Web services and data in the Global SOA?