Strata + Hadoop World: Cloudera introduces RecordService for security, Kudu for streaming data analysis

Strata + Hodoop World 2015 is in progress at New York's Jacob Javits Center. Ahead of the show there were two big announcements from Cloudera on Monday as it introduced RecordService and Kudu.
RecordService is an all-new security layer for Hadoop designed to ensure secure access to data and analysis engines that run on top of Hadoop, including MapReduce, Apache Spark, and Cloudera Impala. Where Cloudera's previously available Sentry security component supported the definition of access-control permissions, RecordService complements Sentry by enforcing access down to the column and row level. It also supports dynamic data masking, according to Cloudera, brining uniform, granular access control to any framework or analysis engine that's plugged into the RecordService API.
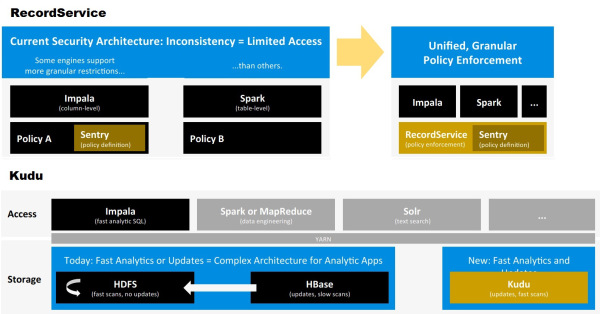
Kudu is a new storage engine that Cloudera has developed to complement the HDFS file system and HBase database. HDFS lets you add data at volume, but it doesn't update data. The HBase database, meanwhile, supports random reading and writing, but it's not a fit for fast scanning of aggregated data. Kudu brings a columnar data store to Hadoop that's aimed at real-time analytical applications such as fraud detection, ad placement and distributed, Internet-of-Things-style apps.
RecordService and Kudu are both being released as beta software downloads this week, and Cloudera says it intends to donate both open-source projects to the Apache Software Foundation. General availability will depend on feedback and revisions required, according to Cloudera, and it did not specify when it will contribute the technologies to ASF.
MyPOV on RecordService and Kudu
Despite the open-source billing, there's little doubt that both of these technologies will be promoted predominantly by Cloudera and used mostly by its customers. Cloudera rival Hortonworks previously introduced the open source Ranger project for data-access authorization, control and auditing within Hadoop. Which security project is likely see wider support? Cloudera mentioned MapR, which currently supports Impala, as showing interest in RecordService. Hortonworks, meanwhile, is a member of the Open Data Platform initiative (ODPi), which counts IBM, Pivotal, SAS and Teradata as founding members. But that group has yet to name Ranger as one of the components of the ODPi Common Core, which currently includes HDFS, YARN, MapReduce and Apache Ambari.
The good news is that Cloudera customers can now look forward to granular data-access controls across data and analysis engines, something that's crucial to secure use of the data in Hadoop in production environments. As for disunity on Hadoop, get used to Cloudera and Hortonworks going separate ways, much like Ford and Chevy or RedHat and Ubuntu.
The bottom line for Cloudera is that it's the leading Hadoop distributor and a deep-pocketed partner of Intel. It can be confident that its technology will be see adoption even there are questions about vendor lock in and dependence on commercial Cloudera Manager software.
Streaming applications are another front on which Cloudera and Hortonworks are headed in different directions. Kudu looks like a promising complement to the current Hadoop stack, and it's aimed at simplifying the complicated LAMBDA architectures that have emerged. Matt Brandwein, Cloudera's director of product marketing, tells me Kudu will work with Apache tools including Kafka and Spark Streaming and will enable developers to remain within the Hadoop stack when building streaming applications.
That sounds like a jab at Hortonworks DataFlow, which is based on its recent Onyara acquisition and Apache NiFi. While both Kudu and DataFlow are aimed at streaming use cases, they are in no way comparable. While Kudu is a storage engine, DataFlow is a much more comprehensive platform aimed at managing streaming data flows from edge sensors and devices to core systems, ensuring tracking of data provenance, and ensure the secure delivery and flow of data across multiple systems despite bandwidth disruptions or offline conditions. It's also separate from Hadoop and has yet to support YARN.
If Kudu and DataFlow have anything in common, it's that it's early days for both project. A lot of development and integration work lies ahead before either technology will see significant real-world adoption. The good news for practitioners is that the Hadoop ecosystem is maturing quickly to support a range of big data and streaming applications with all the security features needed for enterprise production deployments.