Using no-code tools to auto-archive social media information

One of the biggest problems with social media services like Twitter is that it's hard to get information out of them. Sure, you can download everything you've ever tweeted as JSON and CSV files, but after a while that gets large, and it's hard to search -- even when you take advantage of tools like Microsoft's Power BI to explore your archive.
Like many other technology writers, I find Twitter a useful tool for keeping tabs on news and information from various companies that I track, using built-in tools like lists to see what's being said and by whom. You can often find useful pointers to software and SDKs, as well as to obscure pieces of documentation that solve complex problems. I've taken to using Twitter's favoriting tools as a way of bookmarking the content I want to look at later, but favorited tweets don't end up in your archive, and it's near-impossible to search them on Twitter itself.
It's an itch that I needed to scratch -- but one that was very personal and unlikely to be of much use to many other people. How, then, to turn that itch into software?
A simple no-code application running on Zapier, linking two very different cloud services.
Luckily, we're in the golden age of software development, with tools and ways of working that make much of this very easy indeed, building on the growing world of APIs and web services. For my problem, Twitter's APIs come in handy, along with a selection of no-code-based web services that take the output of one web service and deliver it into the inputs of another. I've written about them in the past, starting with the original (and now sadly missed) Yahoo! Pipes.
My initial experiments with automated social media archiving were flawed, as I made one fundamental mistake. Instead of concentrating on how I was going to consume the data, I quickly chose a familiar tool as my endpoint, and then spent time looking into how to collect the data I wanted.
IFTTT and Flow
OneNote was also one of the first applications to offer API access to If This Then That (IFTTT). One of the earliest of the current generation of no-code API connectors, IFTTT had a very flexible set of triggers based on the Twitter APIs. I could quickly set up a couple of different rules, one to handle everything I posted as a test archive, and one that archived everything I favorited. The problem here was, of course, that I'd missed significant limitations in my target platform.
Enterprise Software
OneNote is a great freeform notetaking tool. It is, however, a terrible choice for hosting semi-structured data. I could dump tweets into it, but I couldn't separate out the things I needed, especially the full URLs of content. Delivering to OneNote, all I got was the t.co shortened URLs from Twitter.
There was another, bigger, problem that arrived later: there was a limitation in the size of a OneNote page, and the OneNote APIs weren't able to report the error. After all, as far as the API was concerned the connection had been a success. Instead, as a page got longer, the API started responding slowly, and my archive applet started retrying. That left me with a page filling up with duplicate messages until I noticed, and pointed the applet at a new OneNote page.
I needed to find an alternate endpoint for my applets, one that was effectively infinite, and one that would be able to structure my data. I needed a database or a spreadsheet. Sadly, that's one area where IFTTT falls down, and so I had to look for another tool.
With the launch of Flow, Office 365 had a tool that could work with many different, more enterprise-focused endpoints. These included OneDrive, and Office documents stored on OneDrive. That let me set up an Excel spreadsheet, with columns to handle the Twitter data and metadata I wanted to extract, and a set of Flow rules that would create a spreadsheet if one didn't exist, and start to populate it with data.
That worked well for trapping tweets I made, as Flow only offered a basic set of Twitter triggers for its actions. But I now had part of my solution working, and a rapidly growing set of data on a personal OneDrive. Excel's APIs let me have secure access, and I could sync the directory with the spreadsheet to a PC in order to analyze my data. However, Flow didn't support additional triggers, so I needed to look elsewhere for the final part of the puzzle.
Zapier
Zapier lies somewhere between IFTTT and Flow. Where Flow is a wrapper on top of elements of Azure's serverless compute tooling, Zapier is much more Yahoo! Pipes-like, with the option of building multi-stage actions at higher subscription tiers. There's also a basic free tier that lets you build five actions (or 'zaps') with 1000 runs a month. As much as I use Twitter, I don't make that many favorites so it was worth a look.
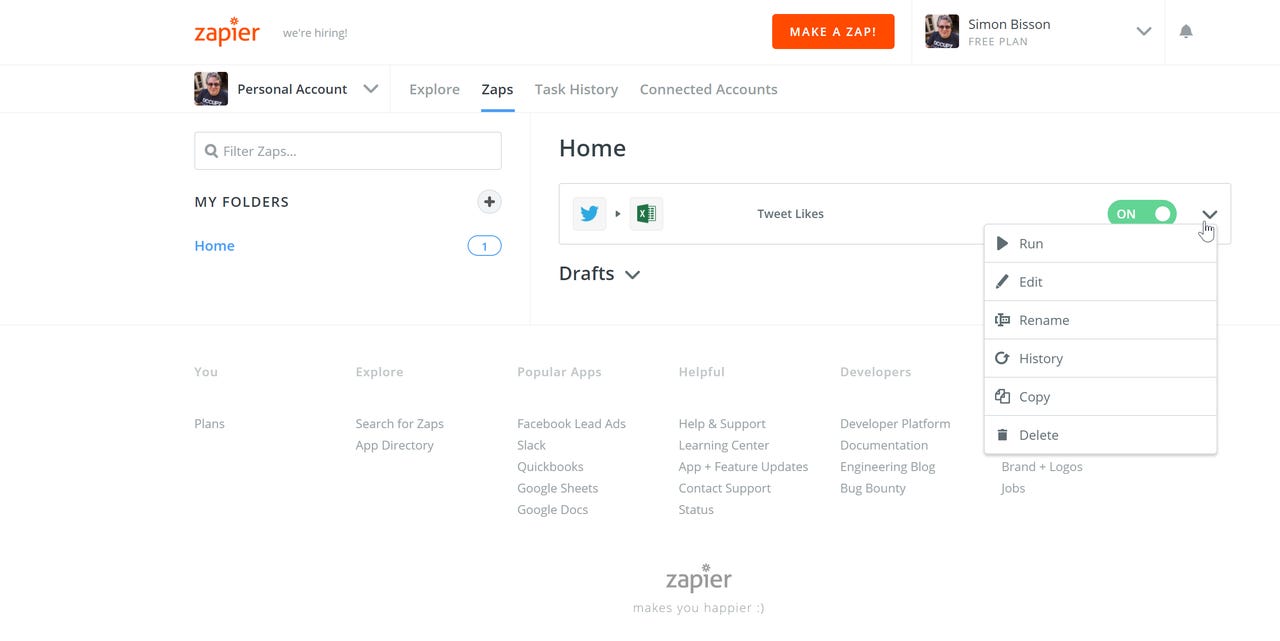
Editing a Zapier 'zap' connecting Twitter and an Excel spreadsheet hosted on OneDrive for Business.
Excel's API is a valid endpoint for Zapier, and the service offers many more Twitter triggers than both Flow and IFTTT. I was able to quickly build a zap that would trigger on my favoriting a tweet, and that would populate a mix of data and metadata, including the expanded URL I wanted to capture, in an Excel spreadsheet. Oddly I was unable to connect Zapier to a consumer OneDrive account, and so had to run it against an Office 365 OneDrive for Business instance.
The basic Zapier account won't automatically retry failed messages, as I discovered when I had the Excel file open locally (and locked for other users). Luckily there's an option to manually retry a failed update, so I didn't miss storing the information I wanted.
There's a lot to be said for using tools like this to automate working with social media. You're able to take the information you want to use and have it where you can get at it easily, and surprisingly quickly. You don't need to write code: all you need is a tool that connects one API to another, handling translation between one JSON format and another. It's how the API world should work; now we need to get more people using these tools to scratch their own, very personal, itches.
Read more by Simon Bisson
- Salesforce bridges gap between development worlds
With Salesforce DX, the SaaS CRM giant is taking a leap into the modern development world. - MongoDB Stitch: Serverless compute with a big difference
MongoDB's Atlas database as a service becomes a platform. - Serverless computing takes another step forward
Twilio's new Functions tooling brings serverless computing to a pioneer of the API economy. - Need a chatbot fast? Your best bet might be a firm you've never heard of
New tools let you go straight from documentation to chatbot, with no code at all.