Intel takes its next step towards exascale computing

Intel is betting on the market for supercomputing growing substantially in the coming years as big data analytics becomes the cornerstone of modern business.
That expectation has prompted Intel to predict substantial demand for supercomputing hardware, forecasting its HPC revenues will be growing by more than 20 percent each year by 2017.
To serve that burgeoning market the chipmaker will next year release Knight's Landing, its new Xeon Phi many-core processor.
Knight's Landing will deliver up to three trillion double precision floating point operations per second (3 teraflops) in a single processor socket. The processor is capable of three times the operations of the chip it will succeed, Intel's current Knight's Corner Xeon Phi co-processor.
But perhaps the most important change from Knight's Corner is that Knight's Landing will be available as a standalone CPU, as opposed to solely being a co-processor card sitting in a PCI-Express slot. The form factor change means Knight's Landing will fit into a wide range workstations and supercomputer clusters, opening up the chip for far broader use than its predecessor.
The move may help Intel win over a larger share of the HPC market. Of the top 500 supercomputers in the world only 17 use Intel's Xeon Phi co-processor, compared to the 44 that use Nvidia's Tesla GPU-based co-processor boards. That said, the world's fastest supercomputer, the Tianhe-2, uses Knight's Corner.
The 3 teraflops performance of Knight's Landing is another step towards the computing industry's goal of, by the end of the decade, building an exascale computing system - a machine capable of 1,000 times the performance of the world's fastest supercomputer in 2008. However Charlie Wuischpard, general manager of High Performance Computing at Intel, said that as systems edge closer to that exascale goal pushing the performance envelope becomes increasingly complicated.
"The race to exascale at the end of the decade is one of the goals we've all got our eye on in the HPC market," he said.
"New challenges keep on arising just outside of compute. As we head towards exaflop, issues of power consumption, network bandwidth, I/O, memory, resilience and reliability all become large problems to solve.
"One of the ways this is going to be resolved from a physics perspective is by greater integration [of hardware components such as processors, memory, interconnects]. Greater integration helps reduce latency. We're making investments in the whole stack and not just from a processor perspective."
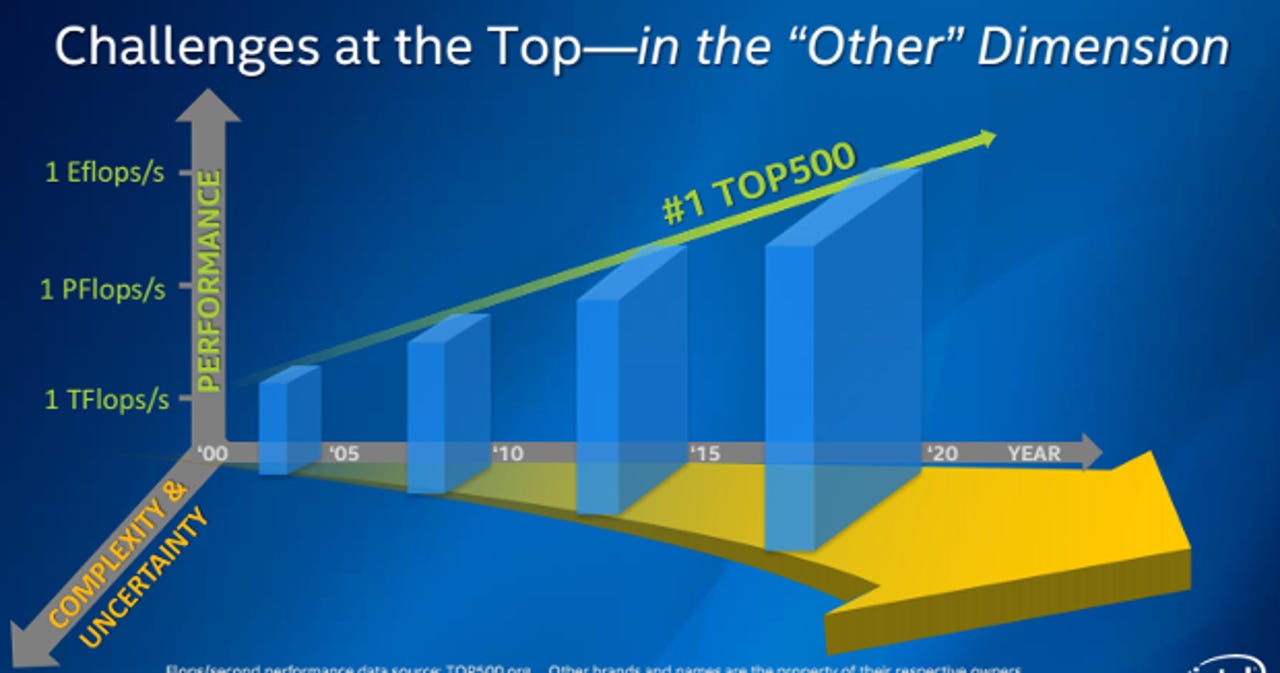
Resolving these issues is made more difficult by the need for new HPC architectures, for example systems utilising processors with tens of cores, to maintain compatibility with existing HPC applications.
"Many of the programs in use today were designed for single-core, single-thread performance. We know and have seen massively-parallel environments are going to be the future.
"While we're developing these next-gen technologies we have to be cognisant of the challenges that exist in the application programming area and ensure we're able to bring those applications forward."
The specs
Knight's Landing will use a more efficient chip architecture than its predecessors, moving to the Silvermont processor core, the low-power core with an out-of-order architecture used in Intel's Atom system on a chip. It will be manufactured using a 14nm process.
Intel has modified the Silvermont core to add what it calls HPC enhancements, including support for the AVX512 instruction set and for four threads per core.
Knight's Landing processors have previously been reported as having up to 72-cores, but Wuischpard only went as far as to say they would have at least 61, connected by a "low latency mesh", the same number as in the Knight's Corner co-processors.
It is by splitting compute tasks between these cores and running them in parallel that the Knight's Landing processor is able deliver three teraflops of performance per socket. Scale that up to a four socket 1U server and there's the possibility of delivering half a petaflop (one quadrillion operations per second) of performance using a 42U rack. Rumours have suggested the chip would deliver between 14 and 16 gigaflops per watt of performance, which would compare favourably to the bang for buck possible using current supercomputers.
The cores also have the advantage of being able to run code that works on Intel Xeon processors, albeit the instructions won't have been optimised to run in parallel on Knight's Landing's many core architecture.
One of the biggest bottlenecks in HPC, according to Wuischpard, is getting data in and out of the processor cores. To alleviate that problem each Knight's landing processor will have up to 16GB of on-package memory, that can transfer data in and out of the cores at up to 500GB/S, which Intel estimates is about five times the bandwidth provided by DDR4 system memory. The on-package memory is based on the low-latency Hybrid Memory Cube Nand flash DRAM chip, which Intel developed with Micron.
The chip is also rumoured to support up to 384GB of DDR4-2400 system memory via a six channel integrated memory controller.
Knight's Landing will be available in systems in the second half of 2015. One of the first supercomputers to use the processor will be run by the US Department of Energy’s National Energy Research Scientific Computing (NERSC) Center.
The $70m system will have more than 9,300 Knight's Landing Cores, and is expected to deliver 10x the sustained computing capability of NERSC's Hopper system, a Cray XE6 supercomputer. It will be used to address challenges such as developing new energy sources, improving energy efficiency, understanding climate change, developing new materials and analyzing massive data sets from experimental facilities around the world.