Benchmarks: AMD's 45nm 'Shanghai' Opteron

AMD's 'Shanghai' processors are the company's first chips to exploit the improved performance and efficiency of 45nm technology. ZDNet's tests show that they have made up important ground on Intel's Xeons.
AMD's 45nm chips have arrived almost exactly one year after the first Intel processors to use the same feature size — currently the most advanced process used in mainstream processor production. Codenamed 'Shanghai', the new AMD processors are arriving first in quad-core Opterons for two-, four- and eight-processor server platforms, enabling up to 32 cores per server. Phenom variants for desktops, codenamed Deneb, are due in the first quarter of 2009.
For the most part, AMD is sticking with its previous 65nm processor design, Barcelona. But by investing in miniaturisation, AMD has created the space on the chip to increase the L3 cache, which was Barcelona's weak spot and which promises good performance return on design investment.
All Shanghai models offer up to 6MB of Level 3 (L3) cache, a three-fold increase on Barcelona's 2MB. The per-core caches — 512KB of L2 cache and 64KB of L1 data and instruction cache — remain unchanged.
On top of that, AMD now supports DDR2 RAM at up to 800MHz, an improvement on Barcelona CPUs' maximum of 667MHz. DDR3 RAM is not supported by the first Shanghai models. Furthermore they are not yet equipped with the HyperTransport 3.0 communications bus, which can run at up to 17GB/s. Early adopters will have to be content with 8GB/s. HyperTransport 3.0 and DDR3 support will be available in the second quarter of 2009.
The instruction set inherited from Barcelona remains unchanged, and Intel's SSE2 and SSE3 instructions are supported, as well as the standard x86 instructions. But although AMD's SSE4a corresponds to the functionality of the Insert and Extract instructions in Intel's SSE4.1, it is incompatible with them.
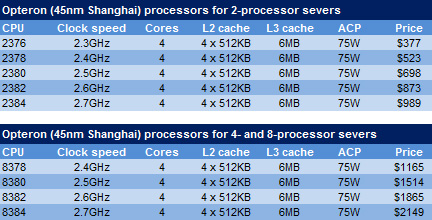
Although there are big price differences between Shanghai CPUs for 2-processor and 4- or 8-processor servers, technically there are almost none.
Locking down the instruction set for virtualisation compatibility
With Shanghai, it's now possible to lock down the instruction set to a subset of the full complement. This feature is important in the live migration of virtual machines (VMs), using, for example, VMware's VMotion. If a VM is moved from one piece of hardware to another in a live environment, it could crash if certain instructions are suddenly no longer available.
If the instruction set is limited to SSE2 when starting a VM, then the VM can be moved to any server that uses at least a Pentium 4. Since Intel's newest processors — for example, the 6-core 'Dunnington' Xeon — also offer instruction set lock-down, it should now be possible to move VMs between live AMD and Intel systems — something that would have unthinkable until recently.
Of course, that instruction set lock-down means accepting the lowest common denominator. But in practice less than five percent of all standard software uses instructions outside SSE2, so a performance hit is unlikely.
The new Shanghai Opterons all consume 75W of Average CPU Power (ACP) — which corresponds to about 95W of Thermal Design Power (TDP) — and are available with clock speeds ranging from 2.3GHz to 2.7GHz. AMD will be releasing 55W models and a 105W chip running at 2.8GHz in the first quarter of 2009.
Prices for the CPUs for two-socket motherboards start at US$377 for 2.3GHz, rising to US$989 for 2.7GHz. The almost identical CPUs for four- and eight-socket boards are significantly more expensive: US$1,165 for the 2.4GHz model and US$2,149 for 2.7GHz.
Expanded L3 cache
In Shanghai, AMD has stuck with the three-level cache architecture established with Barcelona. But while Barcelona's small L3 caches were unimpressive, Shanghai's 6MB shared L3 cache is a big step in the right direction: a cache miss in L2 cache is now much more likely to be compensated for by a hit in L3, avoiding a slow and expensive trip to main memory.
Shanghai CPUs have about the same amount of cache as Intel's first Nehalem (Core i7) CPUs. But while AMD allocates 512KB of exclusive L2 cache per core, Intel's Nehalem chips have only 256KB per core. On the other hand, Nehalem features an 8MB L3 cache compared to Shanghai's 6MB.
Intel's Xeon 5400-series server CPUs have 12MB of cache, and these processors can be viewed as direct competitors to the Shanghai two-processor models. Intel's four-processor models in the Xeon 7400 series have caches of between 14MB and 25MB, but they must access main system memory through a single external quad-channel DDR2 controller. The Nehalem architecture, which has an internal memory controller analogous to Shanghai's HyperTransport, is not yet available for servers.
The lack of support for DDR3 RAM is particularly significant for main memory. If one sets aside marketing statements and examines throughput as expressed by bits per cycle x clock frequency x the number of memory channels, it's clear the crucial factor is the number of memory channels. This scales with AMD's processors, unlike Intel's, as the number of CPUs increases.
A two-processor system with eight cores can use DDR2-800 modules at an effective memory speed of 3.2GHz. That's identical to the performance offered by the quad-channel FB-DIMM controller that Intel uses with its Xeon 5000 processors. But with current Intel server platforms each bit must run through the frontside bus to the northbridge, which also handles the PCI-Express bus.
There's no question that AMD delivers more throughput, especially if the hypervisor, operating system and applications all support a genuine NUMA (Non-Uniform Memory Access) architecture. Intel does not yet offer a server platform with an integrated memory controller, and buyers will have to wait until next year for a two-processor system. Four-processor systems will only become available towards the end of 2009.
Arithmetic performance: just behind Intel's Core 2 architectureZDNet tested a two-processor system with a Supermicro H8DM8-2 board. The system has two 2.7GHz Shanghai Opteron 2384 processors with 16GB RAM. Comparison systems were a Mac Pro with two 2.8GHz quad-core Xeon E5462 'Harpertown' processors and 16GB of RAM, and an Intel four-processor board with the 7300 'Caneland' chipset and two Xeon X7460 'Dunnington' processors, each with six 2.66GHz cores. The test system had a single SATA disk.
The 2.7GHz AMD Shanghai system consumes 183W when idle and 320W fully loaded. Equivalent figures for the 2.8GHz Intel Harpertown system were 190W (idle) and 320W (fully loaded). The 2.66GHz six-core Dunnington machine, with two SAS disks, drew 349W idle and 451W fully loaded.
Intel's Core 2 architecture, as used in the Xeon Harpertown and Dunnington CPUs, just about takes the lead when running arithmetic applications that make few demands on system memory (see graphs below). Intel's lead over AMD in these tests is nowhere near as clear as it was with Barcelona processors.
In the Lavalys AES benchmark, which tests integer performance, the Shanghai system delivers a score of 36,908 points — some 11 percent behind Harpertown, which is 100MHz faster. The Dunnington system comes out well ahead, with a 67 percent advantage. But this comparison is not strictly fair, since the Dunnington system not only has four more cores but also 32MB of Level 3 cache in total, which allows it to cope without making many demands on system memory.
In the single-precision arithmetic Lavalys Julia benchmark, the Shanghai system with SSE scores 12,813, 35 per cent below Harpertown and 46 per cent below Dunnington. With SSE instructions, Intel usually exhibits a far higher performance than AMD. In the more relevant double-precision arithmetic tests of the Lavalys Mandelbrot benchmark, Shanghai with SSE2 is only 12 percent behind Harpertown and 62 percent behind Dunnington.
As soon as main memory performance comes into play, AMD regains the advantage over Intel.
In rendering tests, the Shanghai (Opteron 2384) and Harpertown (Xeon E5462) systems deliver nearly identical results. The Shanghai system processed the Persistence of Vision (PovRay) benchmark 6.6 percent slower than Harpertown, with 3.5 percent less clock speed. The AMD machine took 5.3 percent longer to complete the Cinebench R10 benchmark than the Intel quad-core system. Meanwhile, with 50 percent more cores and an almost identical clock speed to the Shanghai testbed, the Dunnington (Xeon X7460) system ran the PovRay benchmark 54 percent faster and the Cinebench R10 test 41 percent faster.
Although CPU performance is the dominant factor in ray-tracing, memory throughput also plays its part. The Shanghai processors handled ZIP compression (Lavalys ZLib) 2.2 per cent faster than their Harpertown counterparts. That difference in performance becomes clearer with the 7Zip benchmark, in which the AMD system is 6.9 percent faster than the Intel quad-core machine. The 12-core Dunnington system outstrips Shanghai in the Lavalys ZLib benchmark by some 44 percent, but only by about 12 percent in the 7Zip test.
The Lavalys Photoworxx benchmark makes only small demands on arithmetic performance, but stresses memory throughput. Here AMD has the advantage, with the Shanghai system beating Harpertown by 10.5 percent. Dunnington's complex memory architecture and its snoop filter between the L3 cache and main memory get in the way. Intel's six-core system bring up the rear, 27 percent slower than AMD's quad-core Shanghai machine.
Like its Barcelona predecessor, Shanghai supports nested page tables, which AMD calls Rapid Virtualisation Indexing (RVI). Intel does not support this technology on its current server platforms but is expected to offer this feature with its Nehalem architecture.
Users who employ virtualisation software from market leader VMware are unlikely to see performance improvements from RVI because VMware's binary translation software is at least the equal of RVI. Technically, binary translation means nothing more than code patching, with the program code altered to match the virtual address space.
That technology only functions with supported operating systems, and is a possible source of errors — particularly when patching — if executables do not distinguish clearly between programming code and data. A hardware feature such as RVI is primarily a safe alternative to binary translation. Support for it has been implemented, or is planned, by all virtualisation vendors.
AMD's memory architecture is also useful for virtualisation. If a four- or eight-processor system is divided up so that each VM gets a physical processor with four cores, then main memory can be used optimally for each one. Memory throughput can cause problems in virtualised environments, particularly with Dunnington systems where bottlenecks can be caused by up to 24 cores depending on a single memory controller.
Conclusion
In Shanghai, AMD has a processor that can take on Intel's Core 2 architecture in all areas. For pure arithmetic performance, Shanghai still falls short of Intel's chips. But once clock speeds are taken into account, the gap is mostly reduced to a single-figure percentage. Only in single-precision arithmetic using SSE instructions do Shanghai systems show a 35 percent performance shortfall against a comparable Core 2 architecture Xeon system.
Arithmetic performance is highly significant if a server is used for rendering, video encoding or as part of a compute cluster. Typical server tasks, such as file, print, web and database serving, put a special load on memory throughput and memory latency. In these areas Shanghai systems are clearly ahead of their Intel Core 2 counterparts.
Thanks to the memory controller integrated into each Shanghai CPU, memory bandwidth scales with each additional processor in the system — an advantage that becomes particularly evident in four- and eight-processor machines. Intel's four-processor Dunnington system tries to counteract the memory bottleneck by adding large quantities of L3 cache, which succeeds in improving synthetic benchmarks. Buyers considering acquiring a 24-core system usually have to cope with large datasets that don't fit in cache and put a much greater load on the external memory subsystem.
Shanghai systems are efficient in terms of power consumption, but Intel also did its green homework with its 45nm processors, so it can no longer be assumed that AMD systems use less power than comparable Intel systems.
Buyers looking for a balance between power consumption, computational performance and memory throughput will find Shanghai processors extremely attractive. But in two-processor systems, Intel can offer clock speeds up to 3.40GHz, with commensurate increases in arithmetic performance. AMD's top Shanghai processor currently runs at 2.70GHz, but from February 2009 a more power-hungry 2.80GHz version will be available.
Processor development is forging ahead. Intel has already demonstrated what Nehalem can do on the desktop. As well as Nehalem's substantial increases in arithmetic performance, its integrated memory controller is particularly significant. Intel offers a triple-channel DDR3 controller that supports memory up to 1,066MHz, which corresponds roughly to the bandwidth of a hexa-channel DDR2 controller running at up to 533MHz.
If Intel releases the first two-processor Nehalem systems in the spring, it's reasonable to assume they will outstrip the present Shanghai CPUs in most areas. AMD will have to counter that threat with HyperTransport 3.0 and DDR3 support.
AMD's strength in four- and eight-processor systems seems set to continue. Intel is unlikely to offer Nehalem variants for these machines before the end of 2009. Intel's Dunnington chips cannot keep up with AMD's Shanghai because of their restricted main memory bandwidth. Consequently, the two chip-makers will continue to give each other good reason to improve performance and feature sets, and the power user will continue to reap the rewards.
Additional contributions by ZDNet.co.uk's Rupert GoodwinsTranslation by Toby Wolpe