Caffe2: Deep learning with flexibility and scalability

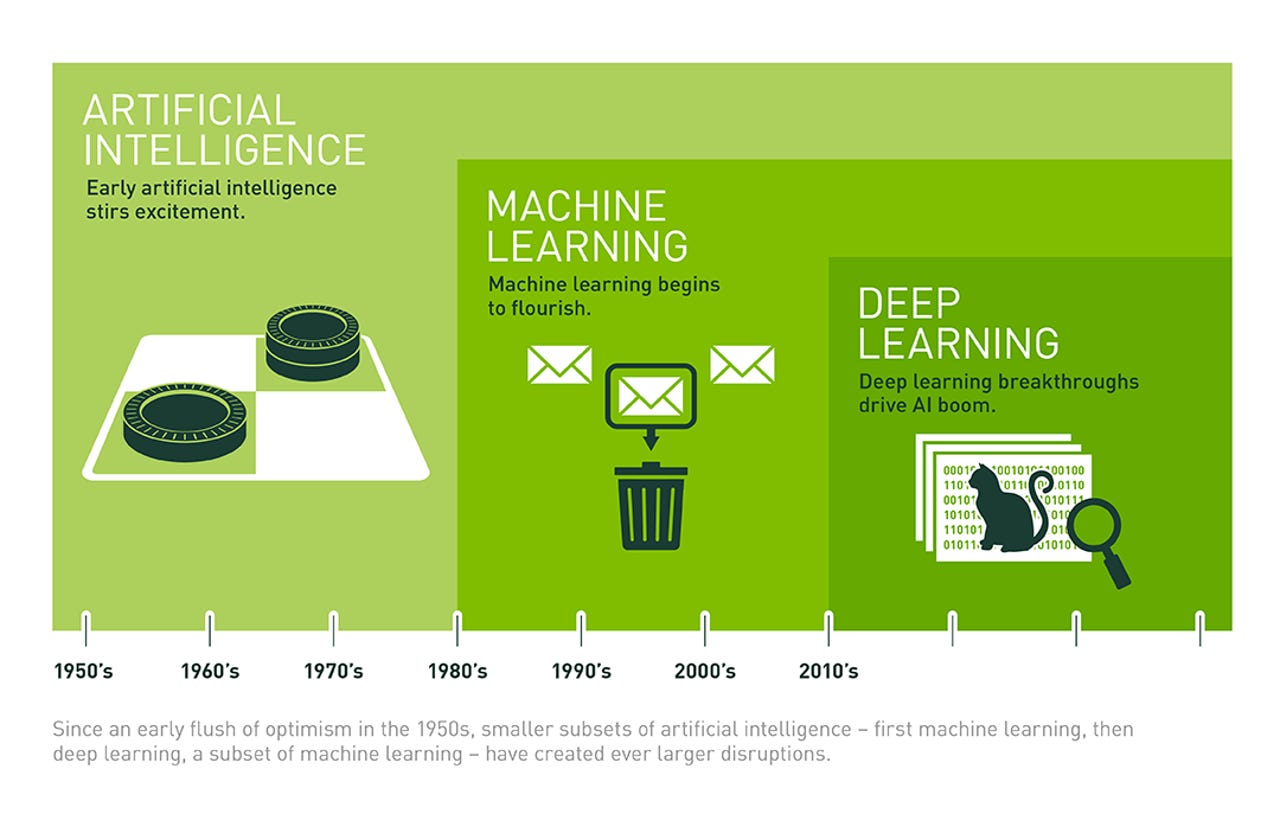
There is more to AI than machine learning, and there is more to machine learning than deep learning. Image: Nvidia
Although artificial intelligence (AI) is more than machine learning (ML), and ML is more than deep learning (DL), DL is an important part of AI that has seen lots of progress and hype as of late. Winning the hearts and minds of developers and creating an ecosystem around frameworks will be very important for this space going forward.
Featured
Taking a look at the history of Android can provide some insights, and it looks like Google is the first to learn from its own success there. Open-sourcing TensorFlow in late 2015 caused a commotion, and some go as far as to say that Google has already won the DL framework race with TensorFlow.
It may be a bit early for such claims though, and the people behind Caffe2 beg to differ.
AI's not a competition -- but who's winning?
So, what does winning even mean here? What are the criteria for defining a winning DL framework? If it's mindshare we're talking about, then yes, it looks like TensorFlow is winning. Although there's no "official" data as of yet, analyzing sources such as StackOverflow and Github seems to point towards a landslide victory for TensorFlow.
If Stackoverflow posts are any indication, TensorFlow is clearly leading the race for deep learning framework adoption. Image: Delip Rao
But perhaps the real question would be "why are people using TensorFlow" -- what are the criteria for choosing a DL framework? And, by extension, how does Caffe2 compare, and why would someone pick this over TensorFlow or other options such as Torch (in which Facebook is also heavily involved in), H2O.ai, DeepLearning4J, or Microsoft's CNTK?
Yangqing Jia, research scientist in Facebook's Applied Machine Learning group and Caffe2 project lead, says:
"Caffe2 is deployed at Facebook to help developers and researchers train large machine learning models and deliver AI-powered experiences in various mobile apps, like style transfer. One great feature of Caffe2 is its flexibility to perform a number of deep learning tasks, so it's easy to customize for specific workloads. We've run Caffe2 on our Big Basin GPU servers and Yosemite CPU servers, both of which are available through the Open Compute Project.
We encourage people to use Caffe2 because of its high performance and first-class support for large-scale distributed training, mobile deployment, new hardware support (in addition to CPU and CUDA), and flexibility for future applications such as quantized computation."
So the emphasis is on performance and flexibility. While performance may seem more straightforward (spoiler alert: it's not), what about flexibility? Jia goes as far as to hint Caffe2 will be quantum-computing ready. This claim may be difficult to assess today, but hardware support and programming language support are fairly tangible aspects of flexibility.
Facebook previously embraced criticism towards Caffe and pointed towards Torch, but the release of Caffe2 may signify a change in course. Facebook worked closely with Nvidia, Qualcomm, Intel, Amazon, and Microsoft to optimize Caffe2 for both cloud and mobile environments. But as many examples have aptly demonstrated, technical merit alone does not always ensure market domination.
Winning hearts and minds
The role of developers is paramount in creating ecosystems, so winning their hearts and minds is essential for winning the battle for DL framework domination. Ease of use and comprehensive documentation and training are key parts of this, and Google has been trying to address this for TensorFlow -- although not always successfully.
Facebook gets this, and that's the reason it's providing internal DL courses. Its employees also get this, and that's the reason these courses are oversubscribed. But internal courses are not enough obviously, so Caffe2 and the partnership with Nvidia is another way for Facebook to address this.
Nvidia runs the Deep Learning Institute (DLI), through which it helps developers learn to use frameworks to design, train, and deploy neural network-powered machine learning for a variety of intelligent applications and services. Starting at Nvidia's GPU Technology Conference on May 8-11, Nvidia is adding Caffe2 training to the DLI curriculum. Members of the DLI team will be on hand to help developers get their hands dirty with Caffe2 through a self-paced lab.
At the GPU Technology Conference in March last year Nvidia shared this graph showing the rapid growth in organizations engaged in deep learning. Image: Nvidia
Will Ramey, Nvidia director of developer programs, comments:
"When we first started offering DL training, most of the interest came from universities and academic researchers. Now we're seeing a significant surge in both interest and adoption of DL in companies, across a wide range of application domains.
Last year alone DLI trained more than 10,000 developers, data scientists, and researchers worldwide through online labs and instructor-led workshops. What we've learned is that the best way for developers to get started with DL is through hands-on experience. That's why our DLI training includes interactive projects the help you learn by actually applying DL to solve challenging problems in healthcare, autonomous driving, robotics, and other industries.
We give developers the skills and experience they need using the latest deep learning frameworks and powerful GPU-accelerated workstations in the cloud, so you can learn how to create deep learning applications without having to purchase or setup a new development system."
Deep Learning at scale everywhere
The need to purchase new development systems is a common concern with DL. In Nvidia's announcement of Caffe2 there was particular emphasis on AI applications for edge devices. At the same time however, it seems like the focus of Caffe2 is on GPUs running on servers like Big Basin, so nowhere near the edge or the capabilities of edge devices.
Nvidia emphasizes Caffe2 performance on GPUs, as far as training is concerned. But performance overall is hard to measure and compare. Image: Nvidia
When asked to clarify this somewhat confusing verbiage, and to explain whether there is something about Caffe2 that makes it particularly suitable for developing AI apps for edge devices, Ramey replied as follows:
"Caffe2 was designed to support the deep learning AI workflow from end-to-end. Its modular, lightweight framework can take full advantage of large scale GPU servers as well as run efficiently on lower powered embedded edge devices.
Caffe2 uses the Nvidia Deep Learning SDK libraries, which are performance-optimized for all Nvidia GPU platforms ranging from Facebook's high-performance Big Basin servers and the Nvidia DGX-1 supercomputer, to energy efficient low-powered embedded devices such as the Nvidia Jetson TX2 which powers smart cameras, robots, drones, and more."
Intel from its side highlights something different in its Caffe2 announcement:
"Most deep learning workloads consist of both training and inference. Training usually requires many hours or days to complete. Inference usually requires milliseconds or seconds and is often a step of a larger process.
While the computing intensity of inference is much lower than that of training, inference is often done on a much larger dataset. Therefore, the total computing resources spent on inference are likely to dwarf those spent on training. The overwhelming majority of all inference workloads run on Intel Xeon CPUs."
The takeaway is that measuring DL performance is complicated. There is the training and the inference part, and then there are different scenarios and hardware that each of these may be running on. Caffe2 has gone to some lengths to get its bases covered in all of those, but although it highlights its improvement over its previous versions, measuring performance against the competition is rather hard.
"All frameworks are more or less at a similar scalability factor,"says Jia. "We're pretty confident that Caffe2 is probably a little bit better than the rest." So the jury is not out on what the most scalable DL framework out there is.
Scalability is a key feature, but it may not be the deciding factor on who wins the DL framework battle. Google seems to have a head start with TensorFlow. Still, this is too important, and it's too early for others to just roll over.
IBM puts deep learning to work on diabetic eye disease: