Can't get a word in edgewise? 3D voice positioning may help

If you do multi-participant audioconferencing - VoIP or not, you've surely run into this problem.
Say you have eight people, each from one of your branch offices. The conference moderator throws out a question, and then four people talk at once.
Or, you, the speaker, pause for 2 seconds mid-sentence to collect the rest of your thoughts. Unfortunately, lacking visual clues, other participants deem that pause as a signal you have finished. But you haven't. Your train of thought is interrupted and apologies are tendered- throwing you off track from the subject matter at hand.
Keith Weiner, CEO of digital audio conferencing solutions provider Diamondware spoke about this issue at the VoIP 2.0 IP Telephony Conference panel "VoIP: Where We're Going, Where We've Been."
When the moderator (me) turned to Keith for his insights, he reflected on a concept called 3D voice positioning.
Keith made the point for IP-based 3D voice positioning as a solution that can "provide intelligibility" during overtalk." He also waved the flag for this technology as a solution for speaker identification.
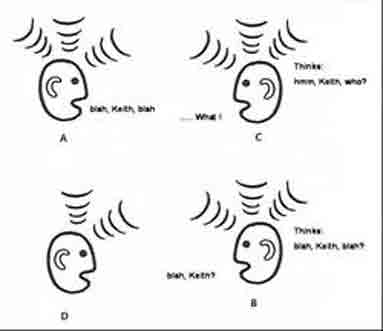
That's a big one, people? How many times have you been on traditional telecom conference calls where six voices - none of whom you are familiar with - are on the line? I know what happens in these calls. After the third, "hi, Pete Jackson again from network services - you, as the listener, tend to think to yourself "yea, I know that."
But what happens if Pete Jackson tires of this drill and doesn't identify himself by name every time he speaks up?
3D voice positioning can be the secret sauce here.
As explained on the Diamondware site:
Of course, in the human ears, sound is heard and processed in stereo. In conventional voice communications networks, both PSTN and VoIP, all sound is monaural. Consequently, they provide no means for the ear to follow a particular voice when two or more people speak at once. They also provide no sense of reality or presence. The value of such conventional conference calling is limited, as the resilience of business air travel even in the wake of 9/11 has proven.
It is possible, in an artificial environment like a voice call over a network, to synthesize stereo cues. The result solves several problems. First, as discussed above, is the problem of distinguishing between two or more people speaking at the same time.
Another is almost the exact opposite. One person speaks for 15 minutes, and then someone else offers a quick comment. How does one determine who is the new voice in the dark? If each person had a position around a virtual conference table, that would provide the information out of band, like an audio "heads up display."
3D positioning of voices provides a subtle but profound improvement in the presence and the reality of the conference. It is a significant step closer towards a real face-to-face meeting. This has a psychological effect on people in terms of making them feel more comfortable, and less in need of getting on a plane as well as the real effect of increasing the value of a conference call.
Imagine: interruption-free VoIP audio conferencing!