Google, Intel, MIT, and more: a NeurIPS conference AI research tour

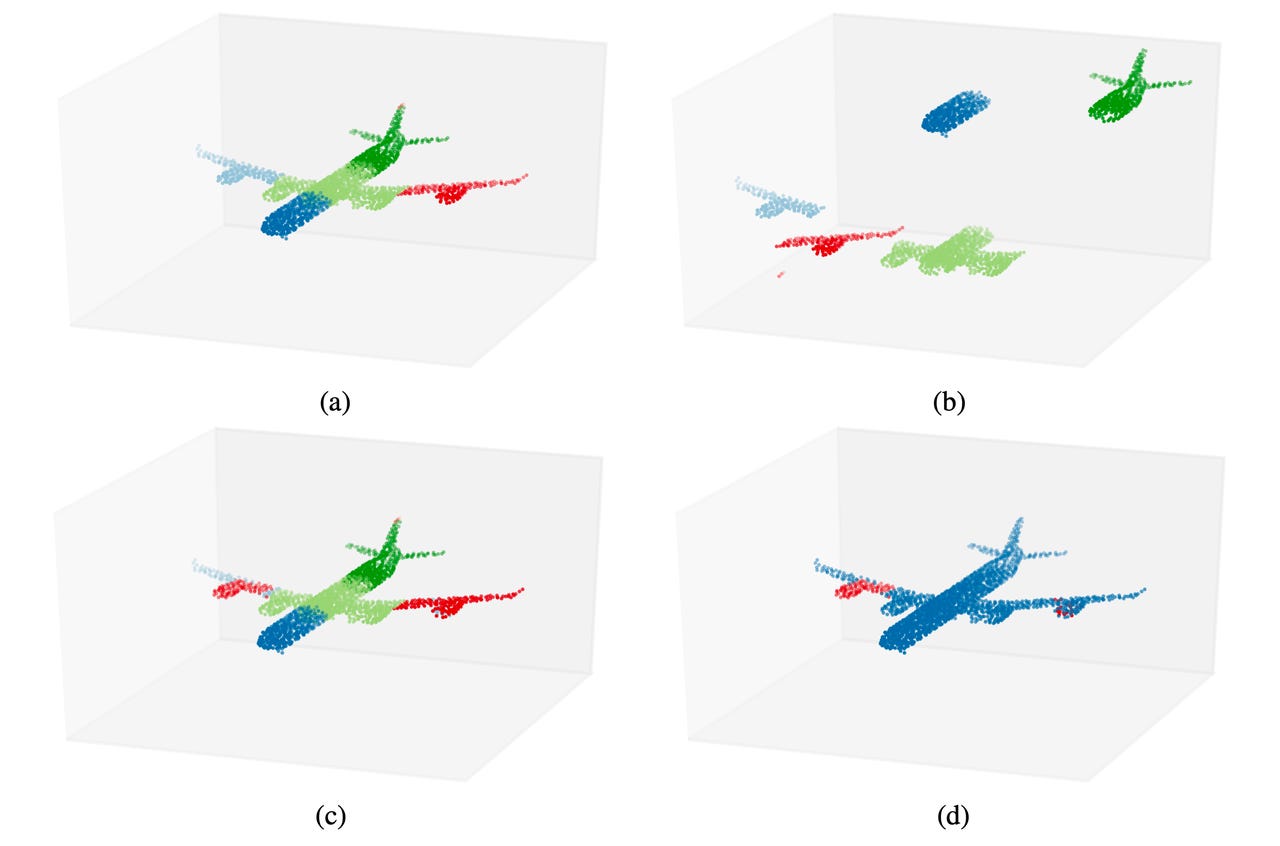
Points clouds of an object, in this case a plane, are broken apart; if a neural network can be trained to reassemble the object, it can develop a capacity to predict the parts of the object without having the point clouds labeled, a form of self-supervised learning.
This Sunday begins the annual NeurIPS conference on artificial intelligence, one of the most prominent gatherings in the field. It's being held this year in Vancouver, British Columbia.
As always, the first thing you want to do, even before the conference starts, is to look over the accepted research papers. All the papers are posted on the NeurIPS Web site, so you can take a tour of this year's research before going, or even without going at all.
ZDNet took a peek at what's posted and came away with a rather unscientific survey of some of the work. Here, in no particular order, are some interesting research efforts. (No offense meant to the tons of papers not cited here, they might very well be masterpieces.)
A whole collection of research addresses knowledge of things from images and from video, broadly speaking. For example, "point clouds," where objects are decomposed into a mass of dots in 3-D space, have become a popular way to build object-recognition systems for things such as autonomous vehicles.
Jonathan Sauder and Bjarne Sievers of the Hasso Plattner Institute in Potsdam, Germany, asked if there was a more efficient way to use point clouds than by having humans label all the points of an object by hand. In "Self-Supervised Deep Learning on Point Clouds by Reconstructing Space," they train a neural network to use "raw," unlabeled point cloud data. By breaking up the parts of an object, the neural network has to develop a sense of that whole object in order to put the parts back together in the proper order. (See the illustration at the top of the article.)
There are new applications of neural networks in the real world that are striking. For example, Miika Aittala and colleagues at MIT, in the paper, "Computational Mirrors: Blind Inverse Light Transport by Deep Matrix Factorization," show how to use convolutions to recover a scene outside of a field of view. If a camera is seeing a scene, and a projector is showing a movie on a screen just outside the camera's point of view, the camera will pick up reflected light on the objects within its field of view. A CNN can then use the reflected light captured by the camera to reconstruct the hidden movie by performing "matrix factorization," which breaks the visible scene into two constituent things, the hidden video and its "light transport" matrix. The result is a "computational mirror."
The authors expect this approach to the unseen can be used to shed light, if you will, on "a wide range of other apparently hopelessly ill-posed problems."
The deep learning procedure to recover hidden video via "matrix factorization."
How a neural network infers low-resolution video from incidental light.
There are plenty of natural language processing experiments. Jiaotao Gu and colleagues at Facebook in "Levenshtein Transformer" adapt the popular Transformer model of language processing to not only generate text but to also edit text after it's been generated via insertion and deletion operations. As they describe it, these operations work iteratively, deleting and adding words in sentences, until the policies controlling insertion and deletion converge in an optimal state. Eventually, they write, one could imagine having humans involved with the program, sharing the work of generating and then "refining" text.
As much as machine learning isn't synonymous with human thought, that doesn't stop researchers from trying to find clues to both neural networks and the human brain by examining their differences and similarities. In "Interpreting and improving natural-language processing (in machines) with natural language-processing (in the brain)," Carnegie Mellon researchers Mariya Toneva and Leila Wehbe watched human subjects read text generated by the latest neural language processing models, including Google's "BERT" and "Transformer-XL." They used functional magnetic resonance imaging (fMRI) and Magnetoencephalography (MEG) to measure how the subjects' brains lit up in certain areas as they read. Then, they trained the language models to "align" their layers to those recordings of the brain as the language models process the same text samples, to then predict the brain recording. Think of it as conditioning the language models on brain activity as a fine-tuning step.
They found when the language models were altered to be better predictors of brain activity, the models also got better at standard NLP tasks. "This result suggests that altering an NLP model to better align with brain recordings of people processing language may lead to better language understanding by the NLP model," write Toneva and Wehbe.
Five easy steps to map brain activity when looking at text to language models such as Google's BERT.
There's plenty of work here on graphs, including the "graph neural networks" that have been developed over a number of years. These are popular for things such as recommender systems, where a neural network makes sense of the structure of relations between nodes and the links between them. (Think of Google's PageRank for search.)
Seongjun Yun and colleagues at Korea University took on the challenge of what to do when parts of a graph are missing, such as a broken link between two nodes, or when the graph is heterogenous, meaning, it has lots of different entities such as a document model that has authors and paper titles and conference names. In "Graph Transformer Networks," they describe how they are able to build "meta-paths" in order to turn the one heterogenous graph into multiple graphs that handle different tasks.
A graph transformer network is a way of filling in the blanks for graphs, including knowledge graphs that have many kinds of different entities, or that have missing paths.
Of course there are many papers on how to refine neural networks for greater efficiency. Brian Cheung and colleagues at UC Berkeley describe, in "Superposition of many models into one," how they figured out how to run multiple neural networks through training operations in parallel with the name number of total weights, by making each weight be a "superposition" weights. They use a linear transformation of the weight matrices so that the weights of multiple neural works can exist in the same amount of data storage. The insight is that most networks are "over-parameterized" anyway. The work also has implications for avoiding the phenomenon of "catastrophic forgetting" in deep learning, they write.
If you can't refine neural networks, you can always figure out ways to handle their inefficiency gracefully. Hence, Google researchers Yanping Huang, Youlong Cheng, Ankur Bapna, Orhan Firat, Mia Xu Chen, Dehao Chen, HyoukJoong Lee, Jiquan Ngiam, Quoc V. Le, Yonghui Wu, and Zhifeng Chen propose GPipe. Originally announced back in March, GPipe is a library for intelligently parallelizing layer computation of deep neural networks. As described in "GPipe: Efficient Training of Giant Neural Networks using Pipeline Parallelism," the authors are grappling with the fact that deep learning neural networks are becoming huge. They cite the example of vastly improved "BLUE" scores on language translation with a Transformer that has 6 billion parameters and 128 layers.
GPipe's main appeal is to partition such giant networks across multiple accelerator chips. They had to come up with a whole bunch of tricks to do it, including splitting the mini-batches in which gradient descent is normally processed into "micro-batches." GPipe, they write, will "allow researchers to easily train increasingly large models by deploying more accelerators."
Boy, these deep networks are getting huge. Google's examples of some titanic deep learning networks that need to be split across processors.
Not that some people aren't trying to make deep learning more hardware-efficient. Shaojie Bai and J. Zico Kolter of Carnegie Mellon University teamed with Vladlen Koltun of Intel's Intel Labs research facility to propose a more memory-efficient neural network for sequence data in "Deep Equilibrium Models."
The DEQ, as it's called, is in fact "extremely memory-efficient," they boast. DEQ keeps memory size constant, regardless of the increasing number of layers of a neural network. How it does that is by using what are called "implicit layers": finding a point of equilibrium that can effectively represent an infinite number of layers. The authors note implicit layers are popular in recent years, but "our current models represent the largest-scale practical application of implicit layers in deep learning of which we are aware." The authors show the technology applied to two different kinds of sequence networks, the Transformer and "temporal convolutions." (More Intel papers can be seen on the chip vendor's Web site.)
Intel and Carnegie Mellon aim to reduce the use of memory in deep learning by considering lots of layers as "implicit," and computing an equilibrium measurement for them.
Some works break new ground in theoretical understanding of what makes machine learning work or not work. A nice example is by Gilad Yehudai and Ohad Shamir of the Weizmann Institute of Science, titled "On the Power and Limitations of Random Features for Understanding Neural Networks." The point of departure for the authors are those over-parameterized networks mentioned above. Such deep learning networks are bigger than they need to be to compute the data, and as a result, they can find functions for a problem with just random parameters, rather than fancy features.
While such works are valuable, the authors formulate theorems showing that actually, the utility of such large networks is limited. They can't account for many types of problems, and in fact, they can't capture what is known as "representation learning," the most productive part of deep learning. In fact, they "cannot efficiently approximate even a single ReLU neuron," write Yehudai and Shamir.
The upshot of the paper is that "we are still quite far from a satisfying general explanation for the empirical success of neural networks."
And what would a conference be without "meta" papers that reflect on the quality of the field itself?
Edward Raff, who is senior lead scientist at Booz Allen Hamilton, looks into reproducibility of work in the modestly titled work, "A Step Toward Quantifying Independently Reproducible Machine Learning Research."
Raff spent six months trying to reproduce the results of 255 papers in AI published from 1984 to 2017. He didn't look at the authors' code, instead he developed new code based on the algorithm descriptions in the papers. He found that 162 papers, or 63.5% were reproducible, which was actually better than had been predicted by studies that didn't do the experiments and merely hypothesized about what makes things reproducible. Raff than rated individual features of papers for how much they affected reproducibility. The single biggest feature he found that affected whether a paper could be reproduced was "readability," which "corresponds to how many reads through the paper were necessary to get to a mostly complete implementation."
"As expected, the fewer attempts to read through a paper, the more likely it was to be reproduced," writes Raff.
Something to keep in mind as you consume tons of papers this week!
Are you at the conference this week? Did you come across some mind-blowing research? If so, please let us know in the comments section.