Hadoop's growing enterprise presence demonstrated by three innovative use cases

It has been nearly six years since I attended my first Hadoop World conference in 2009, and, oh my, how the platform has progressed.
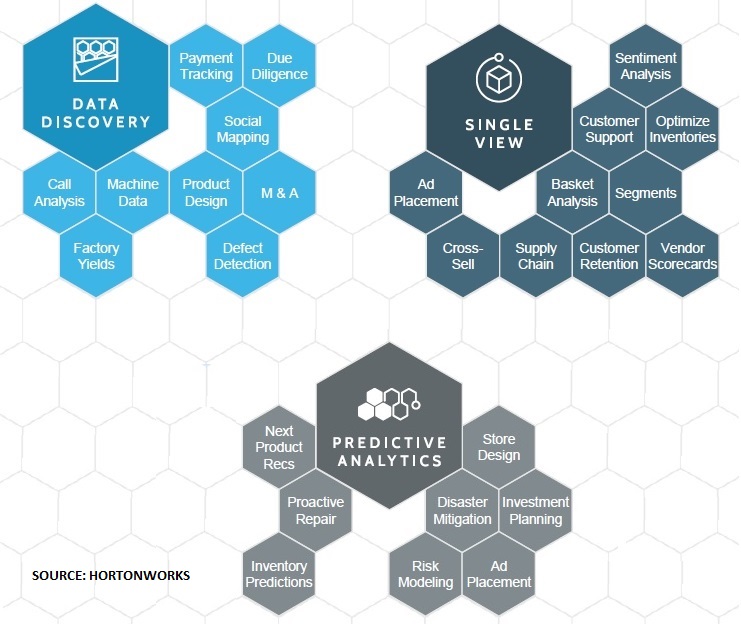
What I'm most excited about, as Strata-Hadoop World 2015 approaches, is growing adoption and rapidly maturing use of the platform. Hortonworks, for one, recently described "transformational, next-generation" data-discovery, single-view-of the-customer and predictive-analytics uses of Hadoop, as depicted below.
Back then, Internet giants including Facebook, Yahoo and Amazon accounted for the vast majority of Hadoop adoption while enterprises like JP Morgan Chase were in the minority. Today, Hadoop is routinely showing up in the enterprise, and it's a given at big banks, big retailers, big telecommunications companies and other data-intensive organizations.
Hortonworks became the first Hadoop software distributor to go public late last year, so now we get regular updates on the growth of the Hadoop market as the company reports its quarterly results. In August, for example, the company reported second quarter revenues of $30.7 million, up 154 percent from $12.1 a year earlier. That performance put Hortonworks on track to exceed $100 million in annual revenue, a milestone privately held Cloudera says it surpassed last year on the strength of 100 percent year-over-year growth.
In the scheme of the software business, $100 million doesn't sound like much compared to the $38 billion in revenue Oracle recorded last year. But keep in mind that we're talking about open source software here, so the bulk of subscription fees go toward support.
In the case of Hortonworks it's 100percent open source software, and the subscription costs sound quite modest. Support costs for an entry-level deployment, for example, are in the mid-five-figure range, according to Hortonworks. Hardward costs are additional, but keep in mind that a modest, four-node starter cluster typically offers tens of terabytes of usable capacity (allowing for Hadoop's triple replication of data). Hadoop offers linear scalability, so the larger the deployment, the bigger the cost advantage over traditional (relational database) infrastructure.
In the early days of Hadoop, there was much more talk about cost savings related to data warehouse optimization. Data warehouses aren't going away, but there's an opportunity to move data out of the comparatively expensive relational database environment and into a Hadoop-based data lake/hub for things like archival storage and ETL processing. Independent data-integration vendors like Informatica,Syncsort and Talend have jumped all over this opportunity, porting their software to run inside Hadoop so it can handle data-parsing and data-transformation workloads.
A second wave of the optimization story started breaking last year with the SQL-on-Hadoop movement. Started by Pivotal with HAWQ and Cloudera with its Impala engine, the wave grew larger as database vendors and Hadoop distributors alike joined in. In the database category, Actian offers its Vortex engine, HP runs Vertica on Hadoop, Oracle introduced Oracle Big Data SQL, and Teradata backs the Presto engine. Among Hadoop distributors, MapR backs open-source Apache Drill and Hortonworks is focused on improving the performance of Hive, which is the original and still-most-widely used SQL-on-Hadoop option.
Familiarity with SQL and compatibility with existing BI and analysis tools have fueled interest in SQL-on-Hadoop options. Executives at Tableau Software, for one, tell me many of that company's joint customers with Cloudera are getting snappy query performance from Impala, which is used in combination with Tableau's SQL-savvy software.
MyPOV on next-gen use of Hadoop
Based developments in the market, SQL-on-Hadoop is more of an incremental optimization play. It lowers the cost of querying at scale with the added advantage of having more data accessible all in one place. But SQL has been around a long time, and it was never terribly effective at cracking high-scale data types like clickstreams, log files, sensor data, mobile app data, social data and so on. These data types aren't really new; it's Hadoop's ability to handle myriad, multi-structured data types that has changed the game.
But what's really driving these new big-data-discovery, single-customer-view, and predictive-analytics breakthroughs is the ability to find correlations across data sets using Hadoop and various analytical frameworks that run on top of the platform. Merck, for example, uses time-series analysis, clustering and other non-SQL analytic techniques to look across dozens of disparate sources and years' worth of data from its manufacturing plants stored in a Hortonworks cloud deployment. This data-discovery application has enabled Merck to optimize production yields of vaccines that are incredibly expensive to produce, lowering drug costs, broadening distribution and literally saving lives.
In a single-customer-view application, St. Louis-based Mercy, the fifth largest Catholic health care system in the U.S., captures electronic health record (EHR) data, sensor data, transactional ERP data, third-party enrichment data and even social data in a Hortonworks-based data lake. Mercy now stores 900 times more detailed data from intensive care units, ingesting patient vital signs every second rather than every 15 minutes, according to Paul Boal, Director of Data Management & Analytics at Mercy. Patient queries across disparate sources that previously took two weeks now take half a day. And finally, Mercy Labs research can now search through terabytes of free-text lab notes that were previously inaccessible.
A third Hortonworks customer, Progressive Insurance, is pursuing the predictive analytics use case, capturing high-scale driving data using its in-car snapshot devices. It uses that data to better predict risk and offer more competitive policies. The company is also analyzing claims to spot potentially fraudulent ones as well as larger patterns of insurance fraud.
These three examples scratch the surface, but other recent customer wins speak volumes about Hadoop acceptance in the enterprise. Cloudera's recent wins include BT (British Telecom), wealth-management firm Northern Trust, and a predictive analytics deployment at retailer Marks & Spencer. At MapR the list of namable enterprise customers includes Cisco, Harte Hanks, Machine Zone (the outfit behind Game of War), and Zion's Bank.
The long story short on Hadoop's progress in the enterprise is that it's here to stay. Yes, it's also going through teenage growing pains in the area of security and data governance, as I wrote earlier this year. But this phase will pass, adoption will continue to grow, and all users will be able to focus on the sorts of business-driving, transformational outcomes that the few pioneers are proving today.
Resources
HP Trafodion: Solving the Operational and Transactional Challenges of Hadoop