Hortonworks adds GUI for streaming data, "Flex Support" for hybrid cloud

With Hortonworks' DataWorks Summit (formerly Hadoop Summit) kicking off on Tuesday, the company is coming out of the gate a day early, with twin product announcements. Specifically, Hortonworks is announcing the general availability (GA) of v3.0 of Hortonworks DataFlow (HDF), its product for streaming data management. It's also launching a new "Flex Support" subscription for its Hortonworks Data Platform (HDP) Hadoop distribution, that supports customers running HDP on-premises, in the public cloud or a combination of the two.
Streaming success
The HDF 3.0 news is interesting. The product is based on Apache NiFi, which itself issued its 0.7.4 release last week. Hortonworks acquired Onyara, the company behind Apache NiFi, back in 2015, soon after NiFi was first announced. Hortonworks did the deal to get into the streaming data game and broaden its product portfolio. Meanwhile, much of the momentum behind streaming hovers around Apache Storm and Kafka -- both of which Hortonworks already supports in HDP.
Also read: Hortonworks introduces DataFlow, acquires Apache NiFi-backer Onyara
Also read: IBM, Cloudera, Amazon announcements: Big Data news roundup
So the pressure has been on for HDF to add value to existing streaming platforms, and not just try to standardize on a new one. HDF may do this yet, as it adds two components, Streaming Analytics Manager (SAM) and Schema Registry, both of which work across Storm, Kafka and NiFi. SAM adds a graphical user interface (GUI) environment for building streaming data flows without code; the Schema Registry adds a catalog of sorts for data streams so that they become discoverable within the organization, and can be reused, rather than duplicated, when other teams want access to the same data.
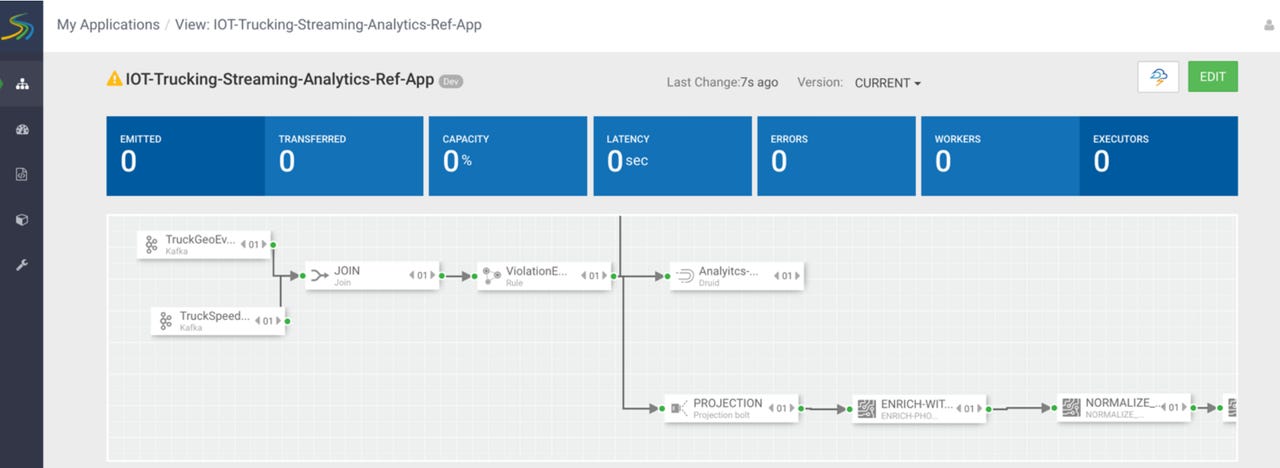
Streaming Analytics Manager (SAM) in HDF 3.0
Freedom of movement
Adding a GUI over streaming data is worthwhile, especially if it adds a layer of abstraction on top of multiple streaming engines. This removes the need for code, allowing data engineers to focus on logic and business problems. It also makes that logic more portable across different streaming technologies, including ones that haven't been introduced yet. For the record, Hortonworks isn't the first to this game. StreamAnalytix has been in-market for several years, with a similar product that works across Apache Storm, Kafka and Spark Streaming.
Also read: StreamAnalytix 2.0 adds support for Spark
The Schema Registry adds to the portability, allowing the logic to be used by business units other than the one that set up the stream in the first place. But since this is really a facet of data governance, it begs the question of whether such functionality should be part of a broader governance tool, for example Apache Atlas, a project driven by Hortonworks. Atlas really focuses on data lineage and audit, though, rather than data catalog functionality. And while both SAM and Schema Registry are open source projects, neither one is an Apache Software Foundation project, at least not yet.
Ambidexterity
Sticking with the concept of portability, the Hortonworks' Flex Support idea just makes sense; it's 2017, and having separate subscriptions for on-prem and cloud customers is starting to make about as much sense as having distinct contracts for customers who use one hardware vendor over another. What's nice about Flex Support, though, is that it's also portable across customers' own Infrastructure as a Service (IaaS) public cloud setups as well as those using Platform as a Service (PaaS) implementations on Hortonworks Data Cloud for AWS.
So, for Hortonworks, it's all about portability, across streaming platforms, across customer business units, and across on-premises, IaaS and PaaS clusters. At a time of transition, that's what customers need. Now Hortonworks just needs a by-the-job product too, for customers who don't want to deal with discrete clusters at all.
My guess is it won't be long.