What's in that photo? Google open-sources caption tool in TensorFlow that can tell you

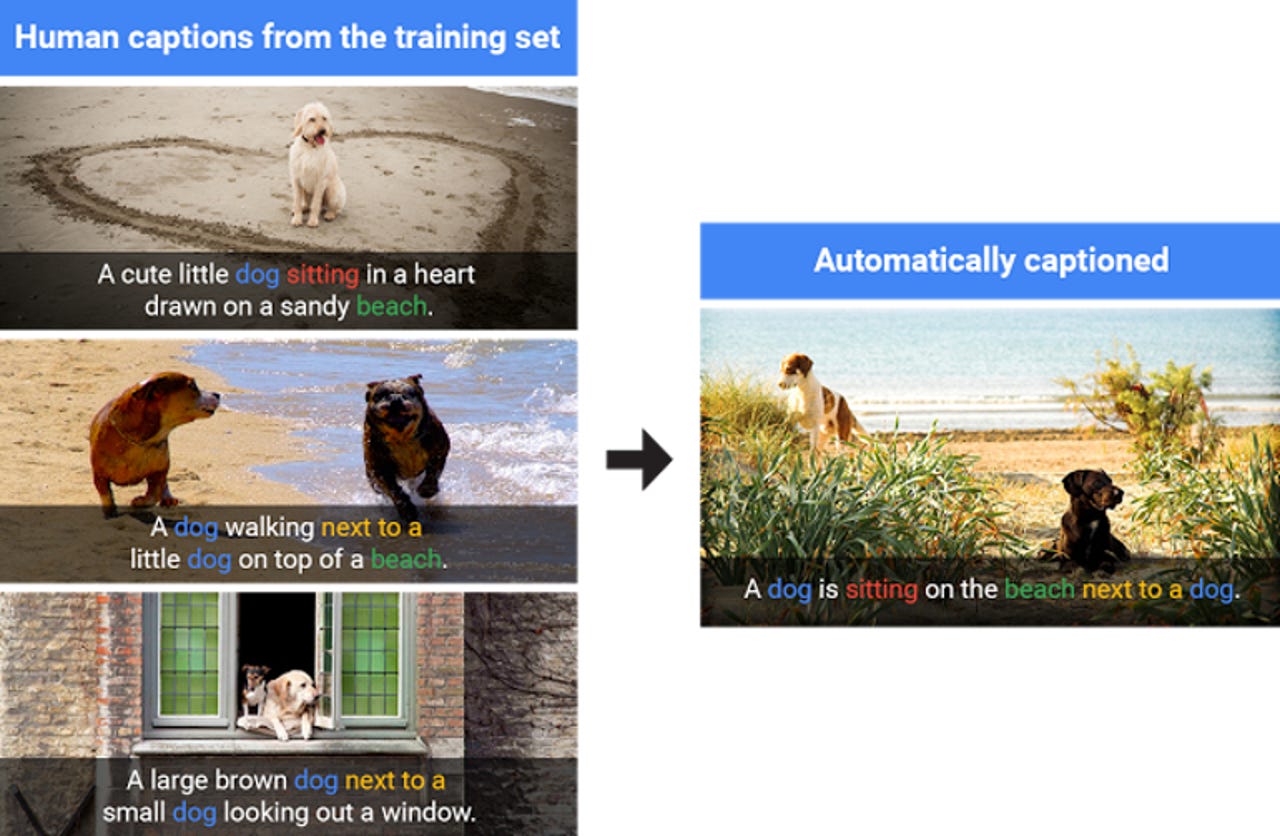
Google's model creates new captions using concepts learned from similar scenes in training.
Google has open-sourced a model for its machine-learning system, called Show and Tell, which can view an image and generate accurate and original captions.
The model it's released is faster to train and better at captioning images than the versions that previously helped it secure a tied first place with Microsoft Research in Microsoft's COCO 2015 image-captioning contest.
The image-captioning system is available for use with TensorFlow, Google's open machine-learning framework, and boasts a 93.9 percent accuracy rate on the ImageNet classification task, inching up from previous iterations.
The code includes an improved vision model, allowing the image-captioning system to recognize different objects in images and hence generate better descriptions.
An improved image model meanwhile aids the captioning system's powers of description, so that it not only identifies a dog, grass and frisbee in an image, but describes the color of grass and more contextual detail.
The improvements, detailed in a new paper, apply recent advances in computer vision and machine translation to image-captioning challenges. Google researchers see potential for it as an accessibility tool for visually-impaired people when viewing images on the web.
That approach is similar to Facebook's use of computer-vision techniques to describe images for the blind.
Google's switch from its previous implementation in DistBelief to TensorFlow has produced an impressive reduction in training speed times.
"The TensorFlow implementation released today achieves the same level of accuracy with significantly faster performance: time per training step is just 0.7 seconds in TensorFlow compared to three seconds in DistBelief on an Nvidia K20 GPU, meaning that total training time is just 25 percent of the time previously required," wrote Chris Shallue, a software engineer from the Google Brain Team.
According to Shallue, its captioning system doesn't just repeat descriptions for similar scenes that it learned from training on images that were already captioned by humans.
It does produce the same captions sometimes, but it can also create entirely new captions when presented with new scenes and expresses them in natural-sounding English phrases.
Read more on machine learning
- Open Mind: Microsoft's Visual Studio-like suite for machine learning
- Is machine learning icing on the cake for data scientists?
- Intel to acquire machine learning startup Nervana Systems
- Google buys French startup Moodstocks to boost machine learning muscle
- TechRepublic: Machine learning: The smart person's guide
- CNET: Google digs deeper on machine learning with new European research lab