Will Google’s more-efficient ‘Reformer’ mitigate or accelerate the arms race in AI?

The promise of technology is always more for less — faster processors at lower prices, thanks to more circuits crammed into the same silicon area.
And artificial intelligence has an analogue, it turns out, based on recent work by engineers at Google, who have found a way to take the "Transformer" language model and make a version of it run in a single graphics processing unit, or GPU, rather than the multiple graphics processing units it normally requires to operate.
That presents users with an interesting choice. If you could choose between getting the top technology in AI in a more easy-to-use fashion, would you opt for that, or would you instead want to stretch the power of your existing computer budget to do more?
It's like asking, Would you like to pay less for a PC or get even more power for what you have been paying? It's a classic dilemma for buyers.
The intent, at least, of Google scientists Nikita Kitaev (who also holds a position at U.C. Berkeley, Łukasz Kaiser, and Anselm Levskaya, is to make the power of Transformer available on a budget, an invention they christen "Reformer."
"We believe that this will help large, richly-parameterized Transformer models become more widespread and accessible," they write in the formal paper, posted on the arXiv pre-print server this week. (There's also a blog post Google has published on the work.)
Here's the situation they're addressing. The Transformer approach to modeling sequential data was introduced in 2017 by Google's Ashish Vaswani and colleagues, and became a sensation. The approach of using "attention" to predict elements of a sequence based on other elements near to it became the basis for numerous language models, including Google's BERT and OpenAI's "GPT2."
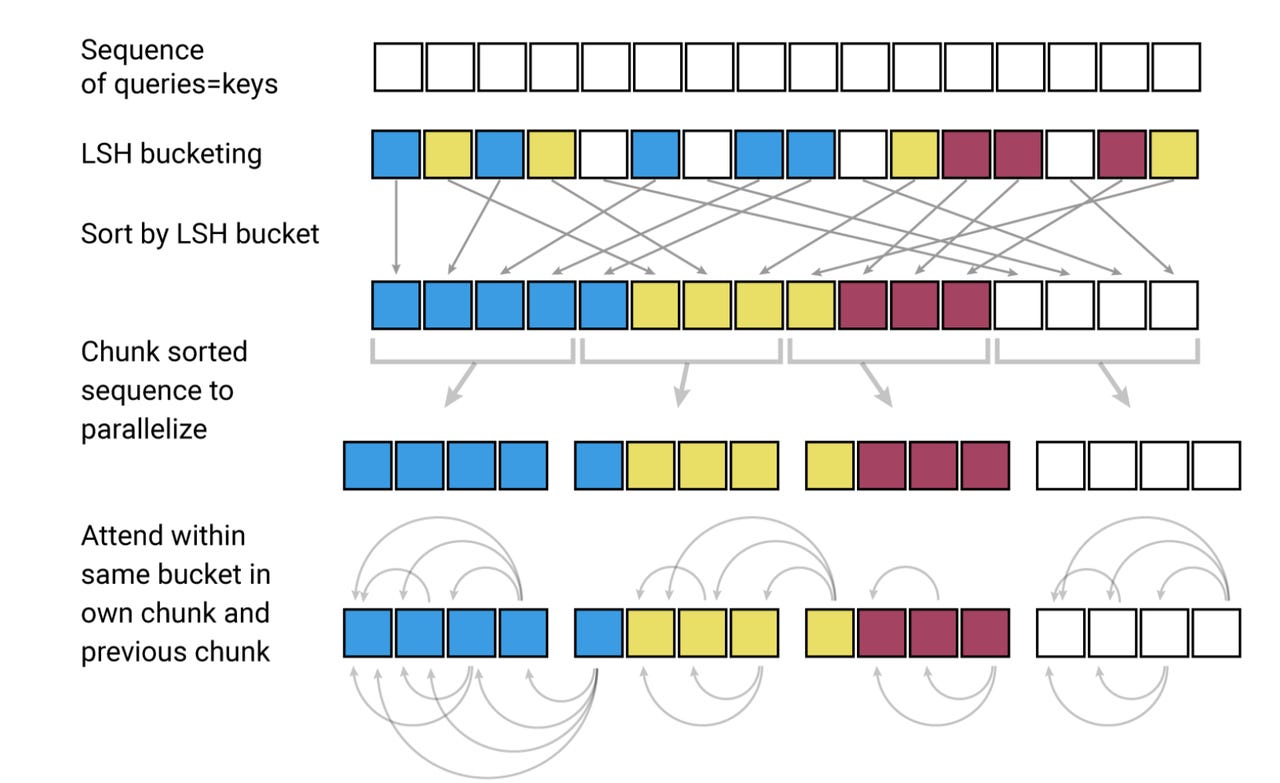
An illustration of the "locality sensitive" hashing function used in Google's Reformer to cut down on the number of activations that need to be stored in memory. The colors denote vectors close in value that can be grouped together to consolidate storage.
The problem is these mega-models take tons of GPUs to run, mostly because of memory issues, not compute issues. GPUs used for training deep neural networks like Transformer, chips such as Nvidia's V100, tend to come with sixteen or thirty-two gigabytes of memory, and that's not enough to hold all of the parameters of neural nets with dozens of layers of neurons, as well as the matrix of activations of each neuron as the network tries in parallel various pairings of symbols looking for the right matches.
Take for example "XLNet," last year's big leap forward in Transformer capability. Authors Zhilin Yang and colleagues write in their implementation notes that they did all their work on Google's TPU chip, "which generally have more RAM than common GPUs." They do the math as to what fit would take to move it to GPUs: "[I]t is currently very difficult (costly) to re-produce most of the XLNet-Large SOTA results in the paper using GPUs." It would take 32 to 128 GPUs to equal their TPU work, they write.
Also: Google says 'exponential' growth of AI is changing nature of compute
The problem is not just that people are getting locked out of using some forms of deep learning. A deeper concern is that claims about which deep learning neural networks may be making breakthroughs are being clouded by massive engineering resources. Cloud giants like Google may be beefing up resources rather than truly making breakthroughs in AI science. That concern is articulated nicely by Anna Rogers in an article on Thinking Semantics cited by Kitaev.
To make Transformer more accessible, Kitaev and colleagues implement a couple tricks to reduce the memory footprint, such as hashing. Hashing, where a code turns a bit sequence into a different bit sequence, can be a way to reduce the total size of data. In this case, "locality-sensitive hashing" groups vectors that are close to one another in terms of values. These are the "key" vectors used by Transformer to store the words it is going to search through for the attention mechanism.
"For example, if K is of length 64K, for each qi we could only consider a small subset of, say, the 32 or 64 closest keys," write Kitaev and colleagues. ["K" is the matrix of keys and "q" refers to the queries that access those keys.) That eliminates the usual N-squared problem that explodes the number of vectors to store in memory.
The second big thing they do is to reduce the total number of neuron activations that need to be stored. Usually, all of them need to be stored, in order to facilitate the backward pass of backpropogation that computes the gradient of a neural network's solution by traversing the layer activations. That activation storage balloons memory as the number of layers of neurons scales. But Kitaev and team adopt something called a "reversible residual network," developed in 2017 by Aidan Gomez and colleagues at the University of Toronto. Gomez and team adapted the traditional ResNet so each layer's activations can be reconstructed from the stored value of the layer coming after it, so most activations don't need to be stored at all.
Also: AI is changing the entire nature of compute
"The reversible Transformer does not need to store activations in each layer and so gets rid of the nl term," write Kitaev and colleagues, referring to the N layers of a network.
With these efficiencies, they are able to cram a twenty-layer Transformer into a single GPU, they write. They can't directly compare its performance to a full sixty-four-layer Transformer, of course, because the Transformer can't fit in the same single GPU. But they show results that appear competitive.
But now comes the question: Reformer can also operate much faster than Transformer running in the traditional computer footprint, in this case, eight GPUs running in parallel, with the same sixty-four layers as the full Transformer. "Reformer matches the results obtained with full Transformer but runs much faster, especially on the text task, and with orders of magnitude better memory efficiency."
That means that with Reformer running on big iron, you can process potentially millions of "tokens," meaning, the individual characters of a written work. The authors refer to processing all of the text of Dostoevsky's "Crime and Punishment," 513,812 tokens, with one Reformer on one machine's worth with eight gigabytes of memory. You can imagine that if Reformer is multiplied across machines, it could operate on data at a greatly increased scale.
If you can get even more performance out of Reformer in this way, it raises the question: will you take a Reformer that can run on a single machine and get good results, or will you run it on multiple GPUs to get even more power? Will Reformer reduce some of the arms race aspect of hardware in AI, or will it only provide a new aspect to that arms race?
Too soon to tell, maybe a mix of both. At least, the breadth of choices is now greater.