Dremio 3.0 adds catalog, containers, enterprise features

Santa Clara, CA-based Dremio, which offers a data virtualization platform the company calls Data-as-a-Service, has today announced its 3.0 release. This comes only six months after its 2.0 release and 15 months since the company emerged from stealth.
Also read: Startup Dremio emerges from stealth, launches memory-based BI query engine
Also read: Dremio 2.0 adds Data Reflections improvements, support for Looker and connectivity to Azure Data Lake Store
Dremio's technology is based on an open source project called Apache Arrow, for which the company is also the major driving force and contributor. Arrow provides a standard for representing columnar data in memory, much as Apache Parquet does file-based storage. Dremio's platform optimizes performance by building Arrow-based structures called Reflections.
Also read: Apache Arrow unifies in-memory Big Data systems
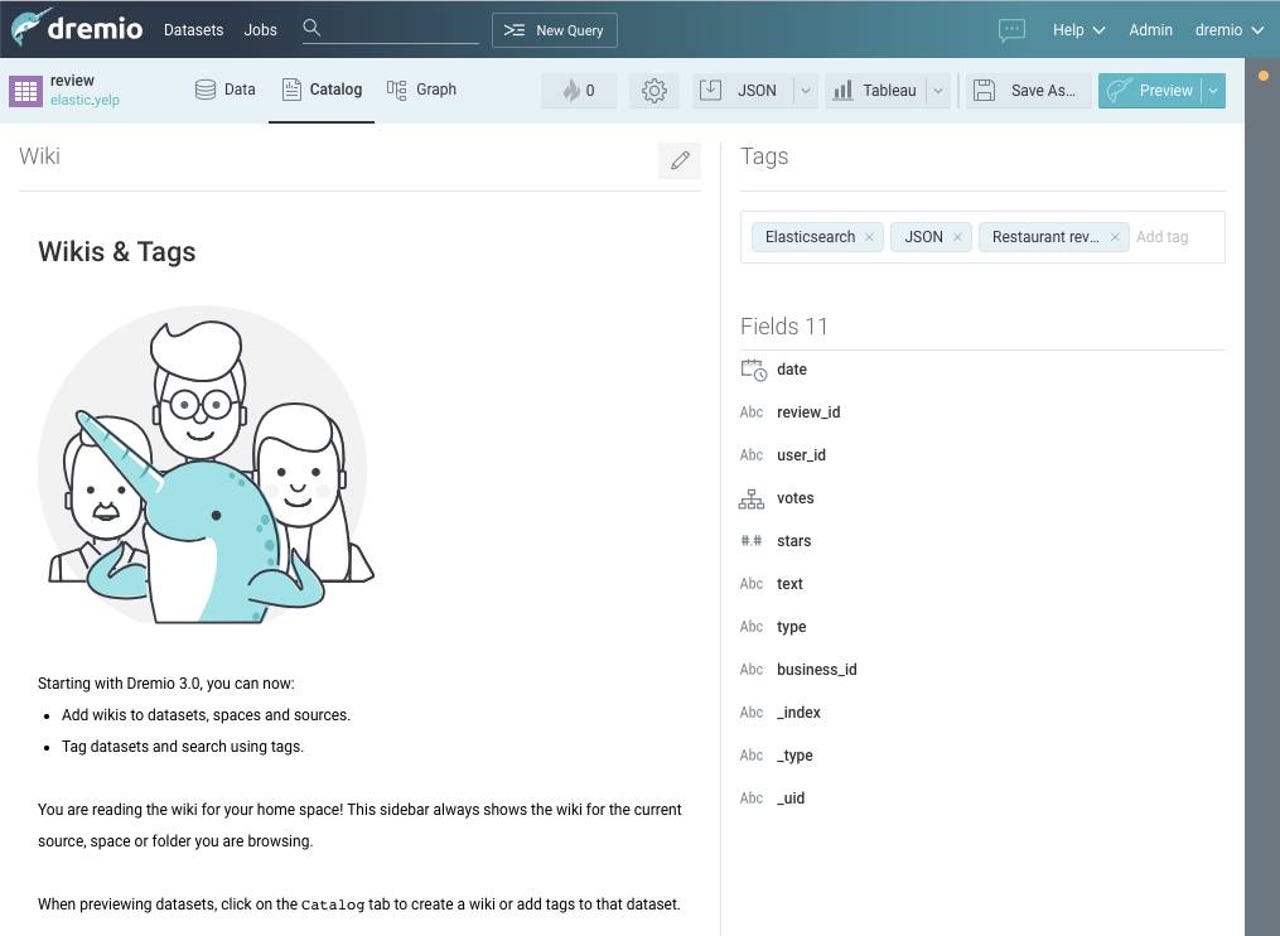
A screenshot of Dremio's new data catalog feature, detailed below
Fit and finish and Taming the sprawl
Like most 3.0 releases, this one marks a real maturation of Dremio and its product. Starting with fact that for perhaps the first time, I was briefed not by Dremio's CTO and co-founder Jacques Nadeau, but instead by CMO & VP Strategy, Kelly Stirman.
The maturation extends to the technology too, of course. While Dremio's Arrow-based technology has largely been its claim to fame up until now, this release adds a lot of enterprise fit and finish to that innovative core.
Companies have data everywhere. It's in OLTP relational, NoSQL, and data warehouse warehouse repositories as well as Hadoop, Spark and cloud storage. Dremio can tie all that data together and make it consumable by self-service BI tools like Tableau or Power BI.
What's on deck
Stirman explained to me how in this release, Dremio is taking that value proposition and giving it enterprise strength, through the addition of several new features:
- A new, integrated data catalog. As an outgrowth of Dremio's tracking the metadata for each of the data sources it connects to, the feature supports wiki-based description of data, as well as tagging, search, and indexing of it for data stewards and consumers. While it's not meant to compete with stand-alone data catalog offerings, this feature is meant to help customers who have little in the way of data governance to be more disciplined, and make their data landscape more discoverable.
- Container-based deployment, through support for Kubernetes, Helm charts and, of course, Docker images for each of Dremio's node types. This support works for on-premises Kubernetes clusters as well as across Amazon Elastic Container Service for Kubernetes (EKS), Azure Kubernetes Service (AKS) and Google's Kubernetes Engine (GKE).
- Workload governance (which Dremio refers to as multi-tenant workload controls), which provides policy-based control of resource allocation and performance based on user, group membership, time of day and query type.
- New security features, including support for Active Directory (and, more generally, LDAP); integration with Apache Ranger; granular security principal control for Amazon EC2-based deployments; and the use of TLS (transport layer security) over ODBC, JDBC and REST, to encrypt connections between Dremio and all of its data sources.
- Connectivity advances: A new unified framework and code base for connecting with relational databases, reducing the amount of work required to on-board new platforms. The company says that eventually all Dremio connectors to RDBMS sources will be based on this framework. A new connector for Teradata is the first such specimen. New connectors for Amazon GovCloud, Azure Data Lake Store (Gen 1) and ElasticSearch 6.x have been added to the product as well.
- Significant performance optimizations through integration of the Gandiva Initiative for Apache Arrow, which compiles data expressions into CPU-native code that processes data in batches.
Also read: Open source "Gandiva" project wants to unblock analytics
No good deed goes uncontested
As companies move toward digital transformation and regulatory compliance, they need technology that will federate all their data -- including in cloud-based data lakes -- and make it readily queryable.
Dremio is working pretty hard to make that a reality. It will need to keep up that hard work, though, as it will increasingly encounter, and compete with, the likes of Denodo, TIBCO, Databricks and others.