AI gets rigorous: Databricks announces MLflow 1.0

X Coordinate support in the MLflow user interface
One year ago yesterday, at the 2018 Spark and AI Summit in San Francisco, Matei Zaharia, Databricks' co-founder/Chief Technologist and creator of Apache Spark, presented his new development focus, an open source project called MLflow. Today, the project has reached a major maturity milestone, with the release of a full version 1.0 to general availability.
Order from entropy
The data science workflow which, to this day, is chock full of ad hoc tasks in siloed development environments. While things are slowly changing, it's all too common for data scientists to tinker on their laptops, with algorithms and hyperparameter values, until they have a trained ML model that they like, and then manually deploy to production.
MLflow aims to impose rigor on this process, allowing each training iteration to be logged and model deployment, to any number of cloud or private environments, to be automated. This allows the work to be discoverable by other data scientists (which hopefully will avoid them redoing the same work) and for automation of retraining and subsequent redeployment of the model.
V1 nails it down
MLflow allows this work to be done at the command line, through a user interface, or via an application programming interface (API). All three of these interfaces were subject to significant change during MLflow's first year of development, but with this 1.0 release, developers can rely on these interfaces being stable from here on.
In addition, MLflow 1.0 offers several new features. Although some of these are pretty technically granular, I'll try to summarize them:
- Support for the Hadoop Distributed File System (HDFS) as an "Artifact Store", allowing MLFlow to store its files in on-premises Hadoop clusters, in addition to cloud storage, local disks, Network File System (NFS) storage and Secure FTP
- Support for the ONNX (the Open Neural Network eXchange) machine learning model format -- originally backed (and used) by Microsoft, Amazon and Facebook -- as an MLflow model "flavor"
- Improved search features, allowing a SQL-like syntax to be used for filter expressions based on attributes and tags, in addition to metrics and parameters
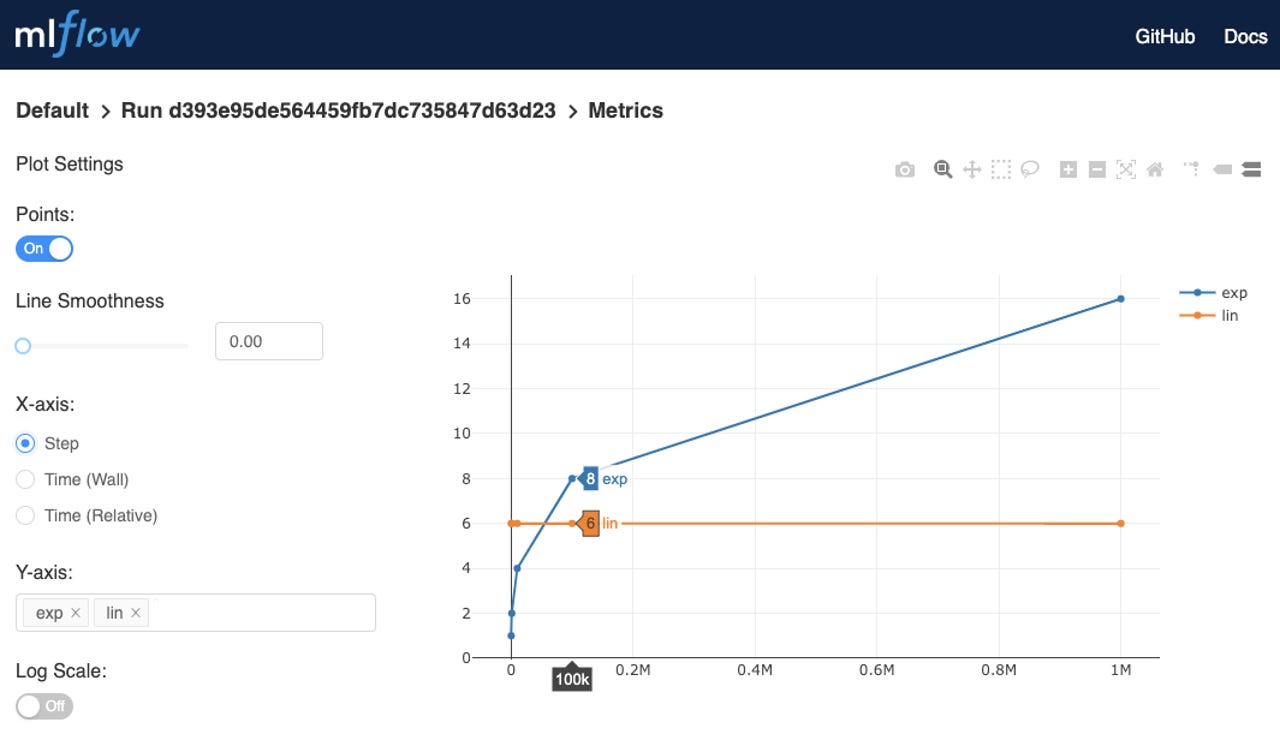
- Support for tracking metric values based on progressions other than time (officially this is referred to as "Support for X Coordinates in the Tracking API"). This is illustrated in the figure at the top of this post, showing how the MLflow UI allows the X axis of its Metrics visualization to be set to Step, in addition to two variants of Time.
- Multiple metrics can be logged in "batch," meaning they can be recorded via a single API call, instead of call per metric-value pair.
Respect as a standard, with more in the pipeline
That's a nice set of features, and there's more to come. The MLflow roadmap includes a model registry that can facilitate continuous integration/deployment (CI/CD), model check/code review, as well as insight into the usage and effectiveness of different model versions. There are plans for multi-step workflow support as well.
Databricks says MLflow now has over 100 contributors, and has been deployed at thousands of organizations. Add to that participation from Microsoft and support for MLflow in its Azure Machine Learning platform, and this project looks to have achieved the status of a standard, in a discipline strongly in need of them.
Also read: Microsoft to join MLflow project, add native support to Azure Machine Learning