AI industry’s performance benchmark, MLPerf, for the first time also measures the energy that machine learning consumes

Every few months, the artificial intelligence industry has a bake-off of the latest machine learning computer systems.
The meet-up, which has been going on for several years, is typically focused on the best performance in multi-processor computers put together by chip vendors such as Nvidia and Qualcomm and their partners such as Dell, measured against a set of benchmark tasks such as object detection and image classification.
This year, the bake-off has a novel twist: An examination of how much energy such massively parallel computer systems cost, as a kind of proxy for how energy-efficient the products are.
The test, MLPerf, has now added industry standard measures of how much electricity in either watts our joules is drawn for a given task.
The work is the result of roughly a year and a half of effort spearheaded by David Kanter, the executive director of MLCommons, the industry consortium that oversees MLPerf,
"One of the things I'm really excited about is the MLPerf Power Project, which is how do we do full-system power measurement," Kanter, in a press briefing to discuss the MLPerf results, which were announced via press on release Wednesday.
The Power Project measures "average AC power (and implicitly energy) consumed by the entire system while executing a performance benchmark," as the group states.
So, a given computer composed of a certain number of chips will be specified to "average" a given amount of watts on a task, or joules, at a given performance rate of queries per second for a given task.
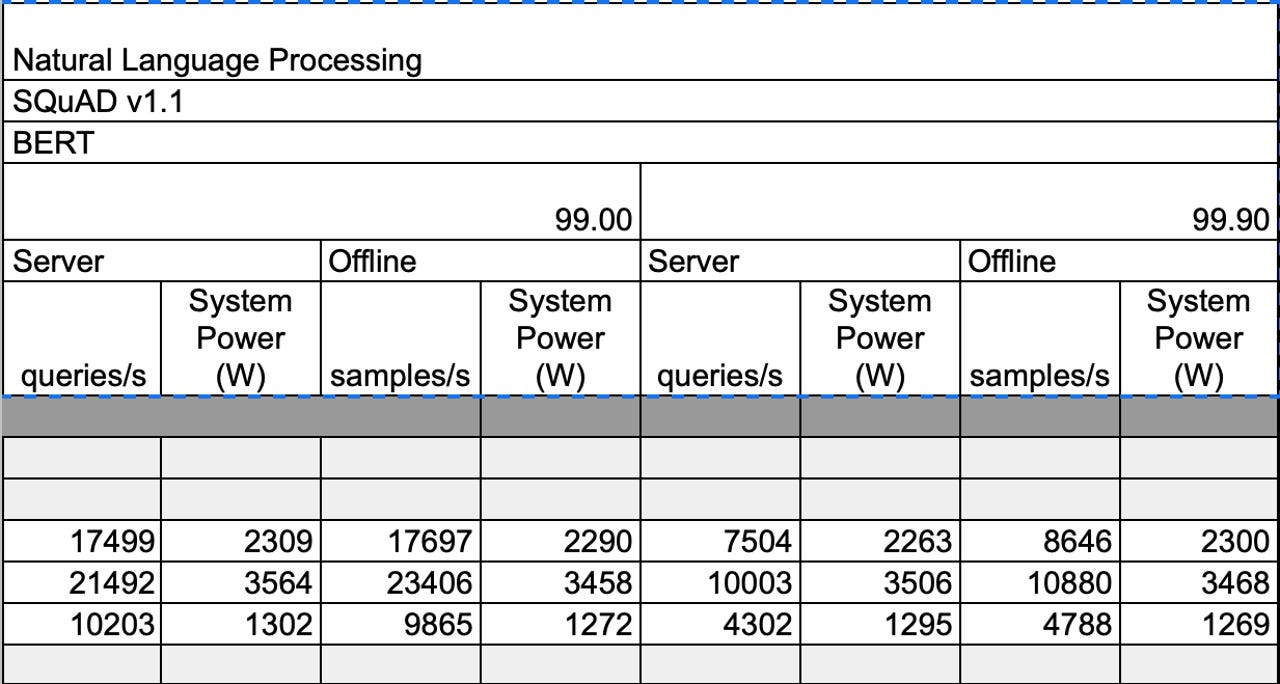
A section of MLPerf's reported submissions for the BERT question answering task, showing query speed and also total system power for three different systems. The submitters offer measurements for both streaming and batch/offline mode.
The systems measured are server computers or edge computers. A server computer would include systems such as a Dell PowerEdge server with two Intel Xeon processors accompanied by four Nvidia T4 accelerators that run the bulk of the AI work.
An edge computer, by contrast, could be a Raspberry Pi machine with one ARM-based Cortex-A72 processor, and no accelerator, or, alternatively, an Nvidia Jetson AGX Xavier server with one Nvidia "Carmel" accelerator chip.
The MLPerf numbers never report superiority of the submissions, instead offering a spreadsheet with results and letting others draw their own conclusions.
MLPerf had sixteen submitters this time around, including Nvidia, Qualcomm, Dell, startup Krai, and Fujitsu. Not every submission offered power measurements, but in total, the MLCommons was able to obtain 850 different measurement results.
Some arithmetic is required to draw conclusions about the energy efficiency of machines, based on reported wattage and performance.
For example, in the category of machines that used ResNet to process the fifteen-million ImageNet dataset, dividing the number of queries per second by the total wattage reveals that a Qualcomm system, using two 16-core AMD Epyc processors and five of Qualcomm's Cloud AI 100 processors, had the lowest wattage per query, 0.0068 watts per query. A system from Dell, a PowerEdge with Intel processors and Nvidia T4 chips, took 0.036 watts per query.
Energy consumed and performance in terms of speed are typically trade-offs: one can optimize one and detract from the other. System makers have to take into account both factors in building computers, keeping in mind how energy-hungry a system can be allowed to be, and how fast it should get work done.
In practice, computers are usually tuned to optimize one or the other, performance or energy efficiency, not really to balance the two.
"In general, if you look at most silicon technology, there is a trade-off between voltage and frequency," is how Kanter described the matter in the press briefing. "The general rule of thumb is that as your voltage goes up or down, that will tend to drive power up or down by the square of the change in voltage." Voltage is typically boosted to goose performance in clock frequency.
The tests allow companies that submit to both use their own version of a neural network algorithm, or to use a standard model, the same as everyone else. So, for example, in the first case, called "Open," a vendor might submit results running Mobilenet, a resource-efficient network convolutional neural network introduced in 2017 by Andrew G. Howard and colleagues at Google. In the "Closed" division, everyone would use the standard ResNet convolutional neural network that has been in use for years.
As a consequence, the power numbers offered by the report reflect not just an energy efficiency of a machine but also energy efficiency of a given neural network algorithm.
Individual contributors offered caveats to the energy measurement. For one thing, how much a chip is used versus how much it stays idle, what's known as total utilization, can effect how energy-efficient it is.
"When doing inference at the edge, where you have streaming data, you are not using even 10% of the peak TOPS [trillions of operations per second] while you are burning a lot of static power," said Hamid Reza Zohouri, head of product for accelerator chip startup EdgeCortix. "So utilization, how well you utilize your chip, can play a big role, that can potentially get better practical power efficiency because you're not wasting idle power on used resources."
Some vendors cautioned that getting work done as quickly as possible is still paramount.
"A lot of times, if there is a certain amount of work to get done, getting that work done faster is generally a good thing," Dave Salvator, the senior manager for product marketing in NVIDIA's Accelerated Computing Group, remarked.
"In the case of real-time applications, it's a matter of being able to serve your customers in real time and hit your SLAs and deliver great user experiences."
For the time being, the reported power numbers may be more useful for providing perspective on the general energy consumption habits of some of the biggest neural networks.
For example, to use Google's BERT language model to answer questions from the The Standford Question Answering Dataset, or SQuAD, version 1.1, a crowd-sourced question/answer set based on data from Wikipedia, the average speed of all systems was about 16,398 queries answered per second, which cost 2.4 kilowatts to process. Hence, a couple of kilowatts a second is one way to regard the energy cost of constantly answer questions.
Such data, measured regularly, could conceivably put a finer point on future discussions of AI's energy cost.
The benchmarks this month are also the first time that MLPerf is being issued as part of MLCommons, which debuted in December.
The MLCommons bills itself as an industry-academic partnership that has a broad mandate to "advance development of, and access to, the latest AI and Machine Learning datasets and models, best practices, benchmarks and metrics."
The MLCommons has a founding board with representatives from Alibaba, Facebook AI, Google, Intel, and NVIDIA, and Vijay Janapa Reddi, an associate professor running the Edge Computing Lab at Harvard University.