Alluxio releases unified data catalog and transformation services

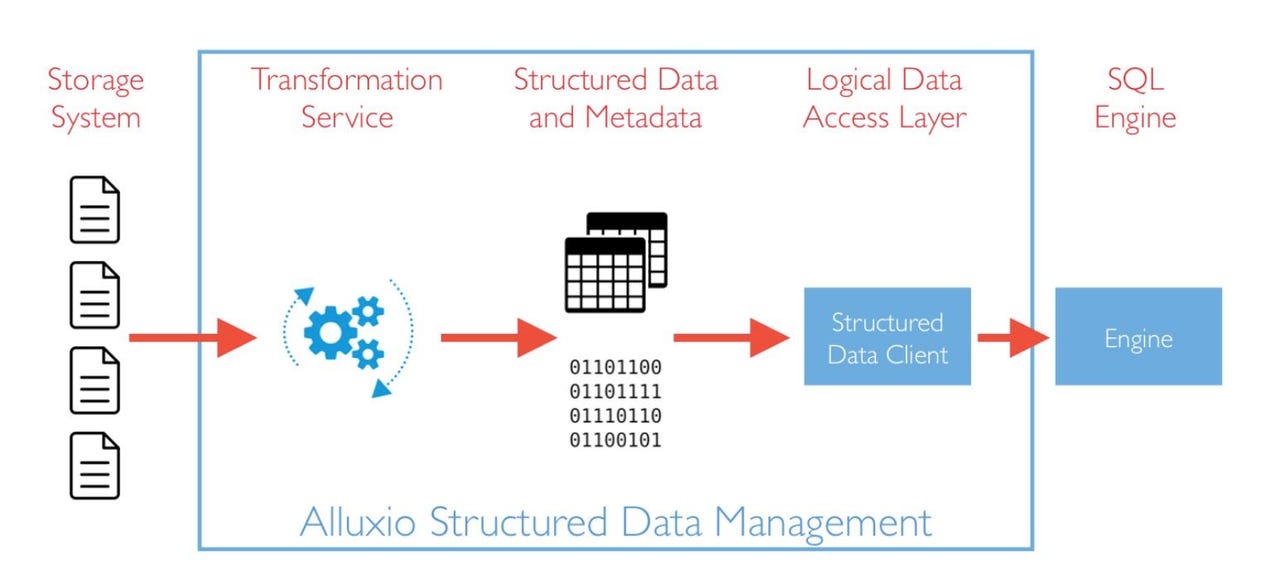
Alluxio Structured Data Management high-level architecture
Alluxio offers a data orchestration layer, based on open source in-memory file system technology of the same name. Back in July of last year, I covered the then new release of Alluxio 2.0 and went into detail on the platform's functionality. Today, Alluxio is announcing its version 2.2 release (in both Enterprise and Community editions), with some very interesting new functionality for data management.
Also read: Alluxio 2.0 seeks to unify fragmented data ecosystem
What Alluxio already did was provide unified access to data across different databases and stores, via an in-memory cache that is addressable through a file system API (application programming interface). While that unified data access is a nice way to break down data silos, it begs the question of how to break down other silos, like each remote platform's metabase. And while the in-memory cache is a great way to boost performance, it also begs a question: how to optimize the physical storage of data -- specifically for compute -- before it's even loaded into the cache. Alluxio 2.2's Structured Data Service (SDS) addresses both of these questions.
Cycle of silo-busting
Alluxio CEO Steven Mih expounded the new capabilities to ZDNet in a telephone briefing. Mih explained that while it's great to unify siloed data, each of the unified platforms may have their own metadata management layer. For example, Apache Hive has its own metabase, which both Presto and Spark SQL also take advantage of. Meanwhile, various data and analytics services on Amazon Web Services (AWS) may instead use AWS Glue's data catalog. If Alluxio is going to provide a unified data access layer for those environments, shouldn't it unify the metabases as well? SDS' Catalog Service in Alluxio 2.2 does just that.
Another facet of working with data lakes: the way they manage the physical storage of data can be sub-optimal for fast performance. To begin with, a lot of data is stored in CSV format (simple text files with comma-delimited rows of data), access to which can be slow. Additionally, for both CSV-formatted data as well as data stored in more analysis-friendly formats like Apache Parquet, individual data sets may be stored over collections of numerous small files. SDS' Transformation Service tackles both of these concerns.
Services, at your service
Catalog Service provides a unified view of the underlying set of metastores in the remote platforms orchestrated by Alluxio. Developers thereby have a single interface and API with which to interrogate the schema of the data sets they're querying. Transformation Service offers a Coalesce sub-service, for combining multiple small files into single larger ones; a Format Conversion sub-service for transforming CSV data into Parquet format; and a Sort service for sorting the data on specific keys, thus speeding up access and simplifying aggregation in a fashion comparable to indexes in a database.
In fact, the metaphor of a traditional database characterizes well what Alluxio with SDS brings to the data lake world overall. While lakes are mostly based on physical files in object storage systems, optimized for economical storage, SDS provides an interface featuring consolidated, sorted tables and formal schemas, optimized for compute and query performance. Essentially, Alluxio is offering a structured data abstraction over the less structured world of data lakes, which makes the Structured Data Service name quite apropos.
No lines, no waiting
In addition to the Catalog Service and Transformation Service, SDS includes a new connector for Presto, allowing that SQL engine to take full advantage of the unified access layer Alluxio provides. Best of all, the functionality I've discussed here is being released today, not just announced: Alluxio 2.2 Community and Enterprise Editions, which each include SDS, are generally available for download today.