Apache Cassandra finally gets an enterprise-grade index

A key part of DataStax's to-do list has been to make Cassandra more usable. And given its strategy to align closely with the open source community, that means Apache Cassandra. Today, DataStax is releasing a long-awaited secondary index that will, in practice, make accessing data stored in Cassandra a more painless experienced.
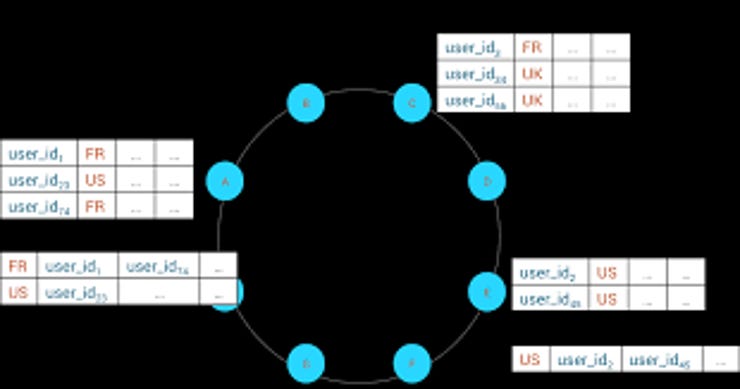
The feature, Storage-Attached Indexing is a geeky name for a customizable index that, unlike predecessors, runs directly inside the Cassandra storage engine. It was developed as part of the Apache Cassandra project, so the index will become available, not only to DataStax Enterprise or Astra cloud users, but anyone using the open source distribution.
The obvious benefit is much better performance compared to predecessors that were add-ons (this is not the first stab at a secondary index for Cassandra) and required full scans of the database to populate. It is written natively into the Cassandra database, meaning that it uses the same core database libraries for memory and resource management, and it resides in the same nodes that store Cassandra tables – ergo the name, "Storage-Attached."
More to the point, because it is part of the core Cassandra database engine, the new index stays current as the database is updated; no external syncing operations are necessary. And the indexing scheme is far more intuitive; instead of indexing columns by physical partition, the new indexing is partition-agnostic.
In fact, the original secondary index for Cassandra was so hard to use that, in practice, most customers use search as a workaround. DataStax Enterprise still offers search, but now it can be used for the keyword retrieval that it was meant for.
The new secondary index is another step in trying to make Apache Cassandra more business-friendly. The database has long been known for its ability to scale thanks to its "masterless" (multi-master) support for local reads and writes anywhere. While it shared some common lineage with what eventually became Amazon DynamoDB, Apache Cassandra was known as the highly performant, highly scalable distributed NoSQL database that provided flexibility, for instance with consistency levels, that endeared it to highly skilled practitioners.
But that power and flexibility was also the rub – Apache Cassandra was not known as an easy database to deploy and manage. As Steven J. Vaughan-Nichols reported back in June, the release of Cassandra 4.0 became an important watershed for feature-completeness. The broader context is that, while Cassandra was known as the fast, highly scalable, distributed database that could handle petabytes of data, AWS has been working to level the playing field with DynamoDB, which for instance, offered more simplicity out of the gate as a managed cloud service, was first to deliver usable secondary indexes, but played catchup Cassandra with its ability to run tables across regions.
Recognizing that if you can't beat them, join them, AWS earlier this year launched Amazon Keyspaces, which provides a managed Cassandra-compatible cloud implementation on its own storage engine. And DataStax followed through on its own cloud blueprint with Astra.
So, storage-attached indexing may sound at first like a minor geeky feature, but the emergence of a secondary index that could actually reflect business terms rather than physical partitions is a key step in making Cassandra enterprise-ready.