Cloudera Data Platform launches with multi/hybrid cloud savvy and mitigated Hadoop complexity

The Cloudera Data Platform (CDP) architecture
Cloudera Data Platform (CDP) is launching today. It's a watershed release and brings existential changes to Hadoop and Big Data overall. It's the culmination of several developments, including Cloudera's merger with its erstwhile rival, Hortonworks. And the pressure to deliver it has been intense.
Also read: Cloudera, Hortonworks merge in deal valued at $5.2 billion
Also read: Cloudera and Hortonworks: Prodigal sons reunite
Also read: Cloudera and Hortonworks' merger closes; quo vadis Big Data?
Backstory
When Cloudera announced its first post-Hortonworks-merger quarterly results this past March, the market balked. Cloudera disclosed results for FY19 Q4 and outlook for FY20 Q1 that were disappointing relative to Wall Street estimates. It then discussed how customers were postponing renewal agreements ahead of the release of CDP, which would merge CDH and HDP, the respective Cloudera and Hortonworks legacy Hadoop/Spark distributions.
Essentially, Cloudera imposed the Osborne effect on itself and from there, the race was on to ship CDP in order to stop the apparent bleeding. Not long after, CEO Tom Reilly and founder/Chief Strategy Officer Mike Olson both retired. Over-eager industry observers started writing their Cloudera obits. At the time, ZDNet editor in chief Lawrence Dignan gave a more empirical analysis: "Now the challenge for Cloudera is clear: It can't afford any delays with the Cloudera Data Platform."
Also read: Cloudera eyes Cloudera Data Platform launch over next two quarters as AWS competition looms
Also read: Cloudera customers hit brakes on renewals ahead of Cloudera Data Platform, CEO Reilly to retire
As if that weren't enough intrigue, last month, activist investor Carl Icahn and his affiliates took an 18%+ stake in Cloudera and won two seats on the Cloudera Board. But now Cloudera can perhaps exhale. The company announced upbeat FY20 Q2 results earlier this month, and today, as the annual Strata Data New York conference (which Cloudera presents with O'Reilly) starts up, Cloudera is indeed launching CDP.
Also read: Cloudera beats Q2 estimates as subscription revenues rise
Executive overview
Cloudera's interim CEO, Martin Cole, and Chief Marketing Officer, Mick Hollison briefed me on the corporate direction and the CDP strategy. Cole explained to me that it embraced activist investor Carl Icahn's intervention because Icahn recognized Cloudera was undervalued. And Hollison explained to me that CDP was unabashedly focused on the enterprise customers that bear out that assessment, given that Cloudera has 140 customers that spend $1M+ per year with them and a broader population of over 950 customers (including the aforementioned 140) that spend over $100K/year.
Product deets
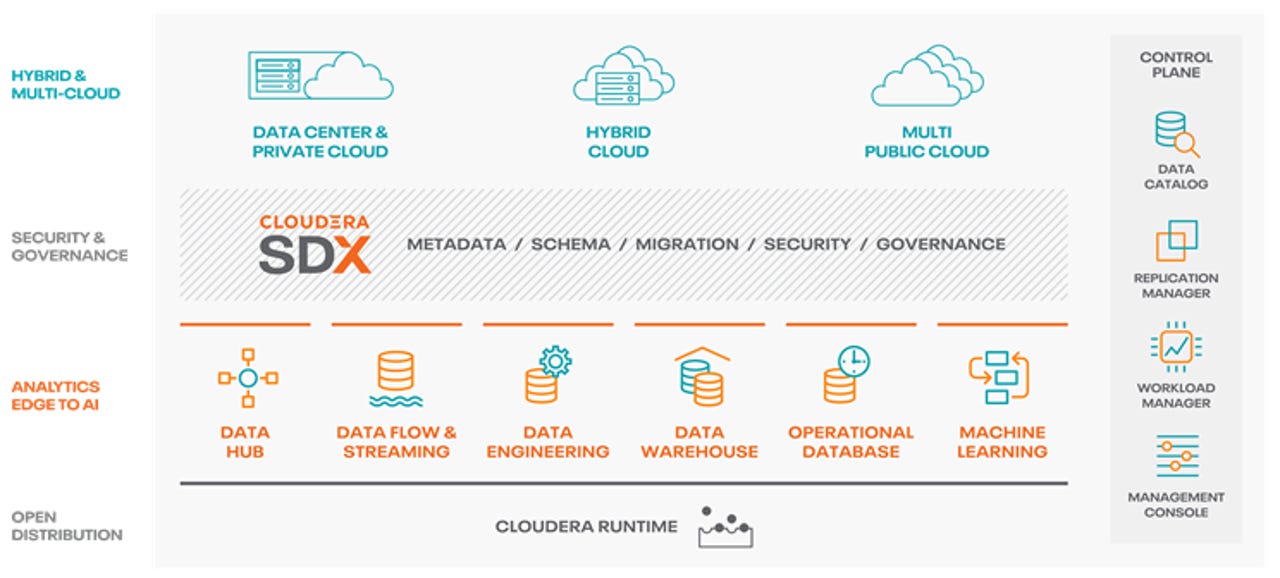
Cloudera Chief Product Officer, Hortonworks co-founder and Hadoop committer Arun Murthy personally briefed me and demoed CDP. As he peeled off layers of the onion, it became clear to me that CDP = CDH + HDP is not the correct equation. CDP is a total remake of the Hadoop/Spark stack. While that may sound like marketing hyperbole, it appears to be genuinely the case. CDP is a virtualized platform that can manage data and data workloads, spin or scale the necessary cluster infrastructure and software up and down on-demand, and do that on-premises as well as across the three major public clouds.
In fact, the combined CDH/HDP distro is almost an implementation detail and the raw guts of it have been renamed and re-categorized as the "Cloudera Runtime." It's not that the core distro is unimportant; it's absolutely foundational. But, as with a building, the foundation isn't something you see, manage, interact with or even think about. It's infrastructure. Exactly as Hadoop (and Spark) always should have been.
The platform is managed through an enhanced version of Cloudera's Shared Data Experience (SDX) and surfaces the Cloudera Runtime capabilities through a component called Cloudera Data Hub, which Murthy described to me as the equivalent of Amazon's Elastic MapReduce (EMR). But there's much more than the runtime, SDX and the Data Hub; CDP includes numerous other services, including:
- Cloudera Machine Learning (CML), providing AI capabilities that are an enhancement to the former Cloudera Data Science Workbench (CDSW)
- Cloudera Data Warehouse (CDW), a data warehouse platform that can leverage either Apache Hive or Impala
- Cloudera Data Flow (CDF), based on the former Hortonworks Data Flow and Apache NiFi
- Cloudera Data Engineering
- Cloudera Operational Database (based on Apache HBase)
Control, plain and simple
The whole is much more than the sum of the parts though, because of Cloudera's control plane, consisting of its Management Console, Workload Manager, Replication Manager and Data Catalog (with traces its lineage to the former Hortonworks Data Steward Studio and Apache Atlas). Together, these components allow unified management and deployment across on-premises environments and all three major public clouds. Murthy also explained to me that the on-prem experience has the identical Software as a Service feel to it that the cloud-deployed CDP does and it can be set up in under an hour. For anything related to on-premises Hadoop, that kind of expedited setup time is beyond unprecedented.
In fact, the control plane lets an existing on-prem implementation "burst to the cloud" and will even provide an estimate of what it will cost to run there. Assuming the customer's happy with the answer, she'll be able to deploy the data (along with the policy that maintains proper governance of it), the stack components, and all dependencies, to the cloud of her choice.
Technical details
This is all made possible by rearchitecting the older distributions to separate compute and storage, replacing Hadoop's Distributed File System (HDFS) with Ozone (an on-premises object store) or cloud object stores, and Hadoop's YARN with Kubernetes (K8s), the suddenly ubiquitous open source container orchestration technology. Cloudera utilizes RedHat's OpenShift-based K8s clusters on-premises or, in the cloud, will deploy to Azure Kuberenetes Service (AKS), Google Kubernetes Engine (GKE) or Amazon Web Services' (AWS') Elastic Kubernetes Service (EKS). K8s makes all this portability and just-in-time instantiation possible for two reasons: (1) it provides an abstraction over the on-premises data center and all three major public clouds and (2) K8s nodes spin up much more quickly than do the public clouds' Infrastructure as a Service (IaaS) platforms' virtual machines (VMs).
The scriptable, dynamic nature of Docker containers and K8s clusters makes Hadoop/Spark clusters portable, elastically scalable and disposable. Add in CDP's ability to leverage AWS Simple Storage Service (S3), Azure Data Lake Storage (ADLS) or Google Cloud Storage (GCS) in the cloud, and Okta/SAML for single sign on, and the package is complete. The clusters are so dynamic, in fact, that according to Murthy, authorized access from BI tools can cause Cloudera Data Warehouse clusters to spin up on demand, just by connecting to them over JDBC.
Enlightened direction and clear choices
I haven't been hands-on with CDP, but Murthy assured me that everything he was demoing to me was based on the released bits. And, while controlled demos can always be used to obfuscate instabilities or as yet unimplemented features, even if CDP's functionality were just a roadmap, you'd have to find it impressive and enlightened. With Cloudera's avowed focus on Enterprise customers, though, I'd be surprised if what I saw was mere smoke and mirrors. The company and its leadership know their stuff has to be real if the company is going to cast off the stigma of its previous quarterly results.
With Cloudera and Hortonworks merged, and MapR's business assets now receded into HPE, customers' choices are clear: use the cloud providers' "house brand" Hadoop services (AWS' EMR, Azure's HDInsight or Google Cloud Dataproc) for commoditized Hadoop and Spark, where the old Cloudera was losing ground, or go with a value-added specialist that provides abstraction, management and multi/hybrid cloud capabilities, embodied in the new Cloudera.