DeepMind's 'Gato' is mediocre, so why did they build it?

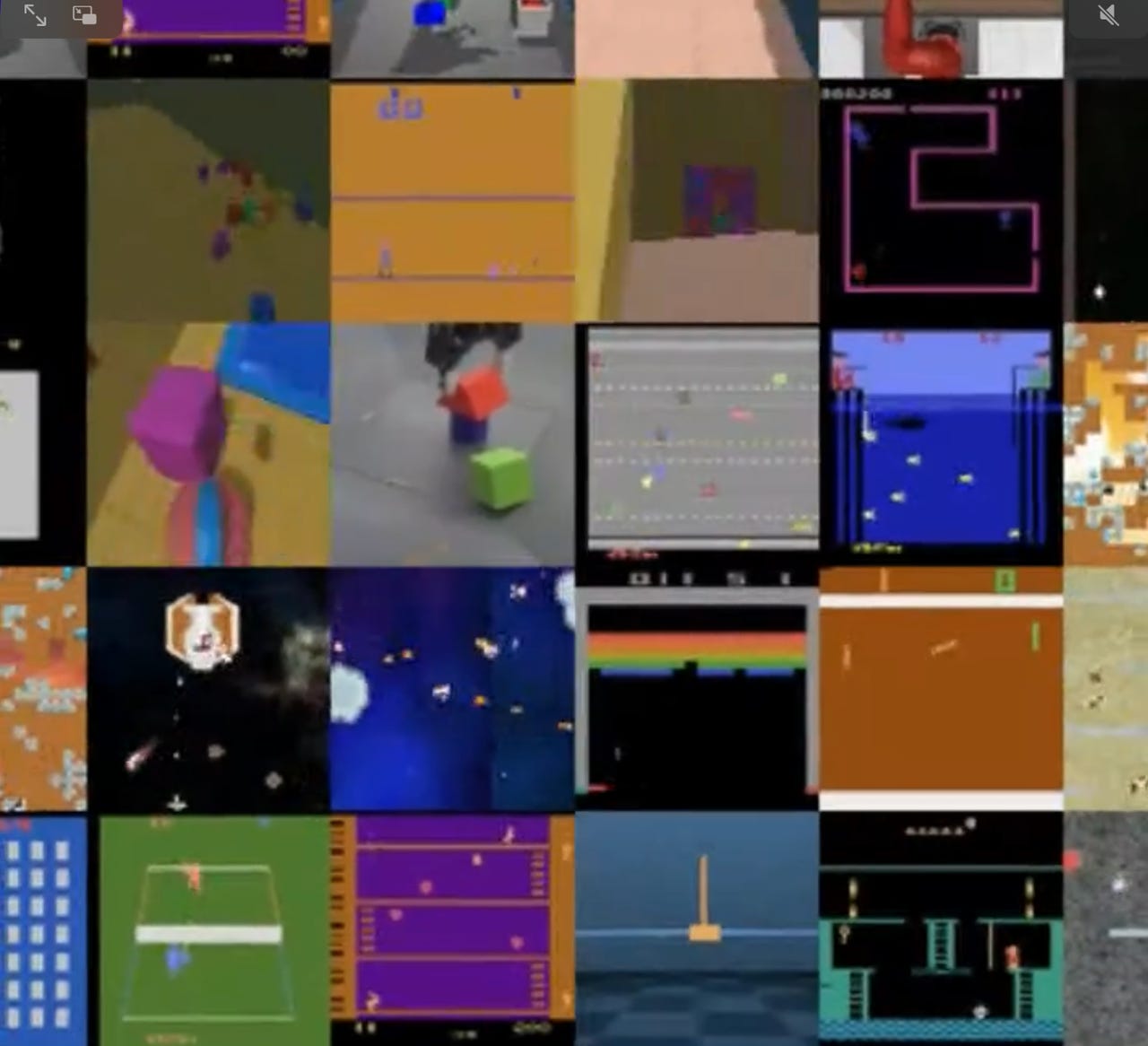
DeepMind's "Gato" neural network excels at numerous tasks including controlling robotic arms that stack blocks, playing Atari 2600 games, and captioning images.
The world is used to seeing headlines about the latest breakthrough by deep learning forms of artificial intelligence. The latest achievement of the DeepMind division of Google, however, might be summarized as, "One AI program that does a so-so job at a lot of things."
Gato, as DeepMind's program is called, was unveiled this week as a so-called multimodal program, one that can play video games, chat, write compositions, caption pictures, and control a robotic arm stacking blocks. It is one neural network that can work with multiple kinds of data to perform multiple kinds of tasks.
"With a single set of weights, Gato can engage in dialogue, caption images, stack blocks with a real robot arm, outperform humans at playing Atari games, navigate in simulated 3D environments, follow instructions, and more," write lead author Scott Reed and colleagues in their paper, "A Generalist Agent," posted on the Arxiv preprint server.
DeepMind co-founder Demis Hassabis cheered on the team, exclaiming in a tweet, "Our most general agent yet!! Fantastic work from the team!"
Also: A new experiment: Does AI really know cats or dogs -- or anything?
The only catch is that Gato is actually not so great on several tasks.
On the one hand, the program is able to do better than a dedicated machine learning program at controlling a robotic Sawyer arm that stacks blocks. On the other hand, it produces captions for images that in many cases are quite poor. Its ability at standard chat dialogue with a human interlocutor is similarly mediocre, sometimes eliciting contradictory and nonsensical utterances.
And its playing of Atari 2600 video games falls below that of most dedicated ML programs designed to compete in the benchmark Arcade Learning Environment.
Why would you make a program that does some stuff pretty well and a bunch of other things not so well? Precedent, and expectation, according to the authors.
There is precedent for more general kinds of programs becoming the state of the art in AI, and there is an expectation that increasing amounts of computing power will in future make up for shortcomings.
Generality can tend to triumph in AI. As the authors note, citing AI scholar Richard Sutton, "Historically, generic models that are better at leveraging computation have also tended to overtake more specialized domain-specific approaches eventually."
As Sutton wrote in his own blog post, "The biggest lesson that can be read from 70 years of AI research is that general methods that leverage computation are ultimately the most effective, and by a large margin."
Put into a formal thesis, Reed and team write that "we here test the hypothesis that training an agent which is generally capable on a large number of tasks is possible; and that this general agent can be adapted with little extra data to succeed at an even larger number of tasks."
Also: Meta's AI luminary LeCun explores deep learning's energy frontier
The model, in this case, is, indeed, very general. It is a version of the Transformer, the dominant kind of attention-based model that has become the basis of numerous programs including GPT-3. A transformer models the probability of some element given the elements that surround it such as words in a sentence.
In the case of Gato, the DeepMind scientists are able to use the same conditional probability search on numerous data types.
As Reed and colleagues describe the task of training Gato,
During the training phase of Gato, data from different tasks and modalities are serialised into a flat sequence of tokens, batched, and processed by a transformer neural network similar to a large language model. The loss is masked so that Gato only predicts action and text targets.
Gato, in other words, doesn't treat tokens differently whether they are words in a chat or movement vectors in a block-stacking exercise. It's all the same.
Gato training scenario.
Buried within Reed and team's hypothesis is a corollary, namely that more and more computing power will win, eventually. Right now, Gato is limited by the response time of a Sawyer robot arm that does the block stacking. At 1.18 billion network parameters, Gato is vastly smaller than very large AI models such as GPT-3. As deep learning models get bigger, performing inference leads to latency that can fail in the non-deterministic world of a real-world robot.
But, Reed and colleagues expect that limit to be surpassed as AI hardware gets faster at processing.
"We focus our training at the operating point of model scale that allows real-time control of real-world robots, currently around 1.2B parameters in the case of Gato," they wrote. "As hardware and model architectures improve, this operating point will naturally increase the feasible model size, pushing generalist models higher up the scaling law curve."
Hence, Gato is really a model for how scale of compute will continue to be the main vector of machine learning development, by making general models larger and larger. Bigger is better, in other words.
Gato gets better as the size of the neural network in parameters increases.
And the authors have some evidence for this. Gato does seem to get better as it gets bigger. They compare averaged scores across all the benchmark tasks for three sizes of model according to parameters, 79 million, 364 million, and the main model, 1.18 billion. "We can see that for an equivalent token count, there is a significant performance improvement with increased scale," the authors write.
An interesting future question is whether a program that is a generalist is more dangerous than other kinds of AI programs. The authors spend a bunch of time in the paper discussing the fact that there are potential dangers not yet well understood.
The idea of a program that handles multiple tasks suggests to the layperson a kind of human adaptability, but that may be a dangerous misperception. "For example, physical embodiment could lead to users anthropomorphizing the agent, leading to misplaced trust in the case of a malfunctioning system, or be exploitable by bad actors," Reed and team write.
"Additionally, while cross-domain knowledge transfer is often a goal in ML research, it could create unexpected and undesired outcomes if certain behaviors (e.g. arcade game fighting) are transferred to the wrong context."
Hence, they write, "The ethics and safety considerations of knowledge transfer may require substantial new research as generalist systems advance."
(As an interesting side note, the Gato paper employs a scheme to describe risk devised by former Google AI researcher Margaret Michell and colleagues, called Model Cards. Model Cards give a concise summary of what an AI program is, what it does, and what factors affect how it operates. Michell wrote last year that she was forced out of Google for supporting her former colleague, Timnit Gebru, whose ethical concerns over AI ran afoul of Google's AI leadership.)
Gato is by no means unique in its generalizing tendency. It is part of the broad trend to generalization, and larger models that use buckets of horsepower. The world got the first taste of Google's tilt in this direction last summer, with Google's "Perceiver" neural network that combined text Transformer tasks with images, sound, and LiDAR spatial coordinates.
Among its peers is PaLM, the Pathways Language Model, introduced this year by Google scientists, a 540-billion parameter model that makes use of a new technology for coordinating thousands of chips, known as Pathways, also invented at Google. A neural network released in January by Meta, called "data2vec," uses Transformers for image data, speech audio waveforms, and text language representations all in one.
What's new about Gato, it would seem, is the intention to take AI used for non-robotics tasks and push it into the robotics realm.
Gato's creators, noting the achievements of Pathways, and other generalist approaches, see the ultimate achievement in AI that can operate in the real world, with any kind of tasks.
"Future work should consider how to unify these text capabilities into one fully generalist agent that can also act in real time in the real world, in diverse environments and embodiments."
You could, then, consider Gato as an important step on the path to solving AI's most difficult problem, robotics.