Domino Data Lab's new release pushes the envelope on MLOps

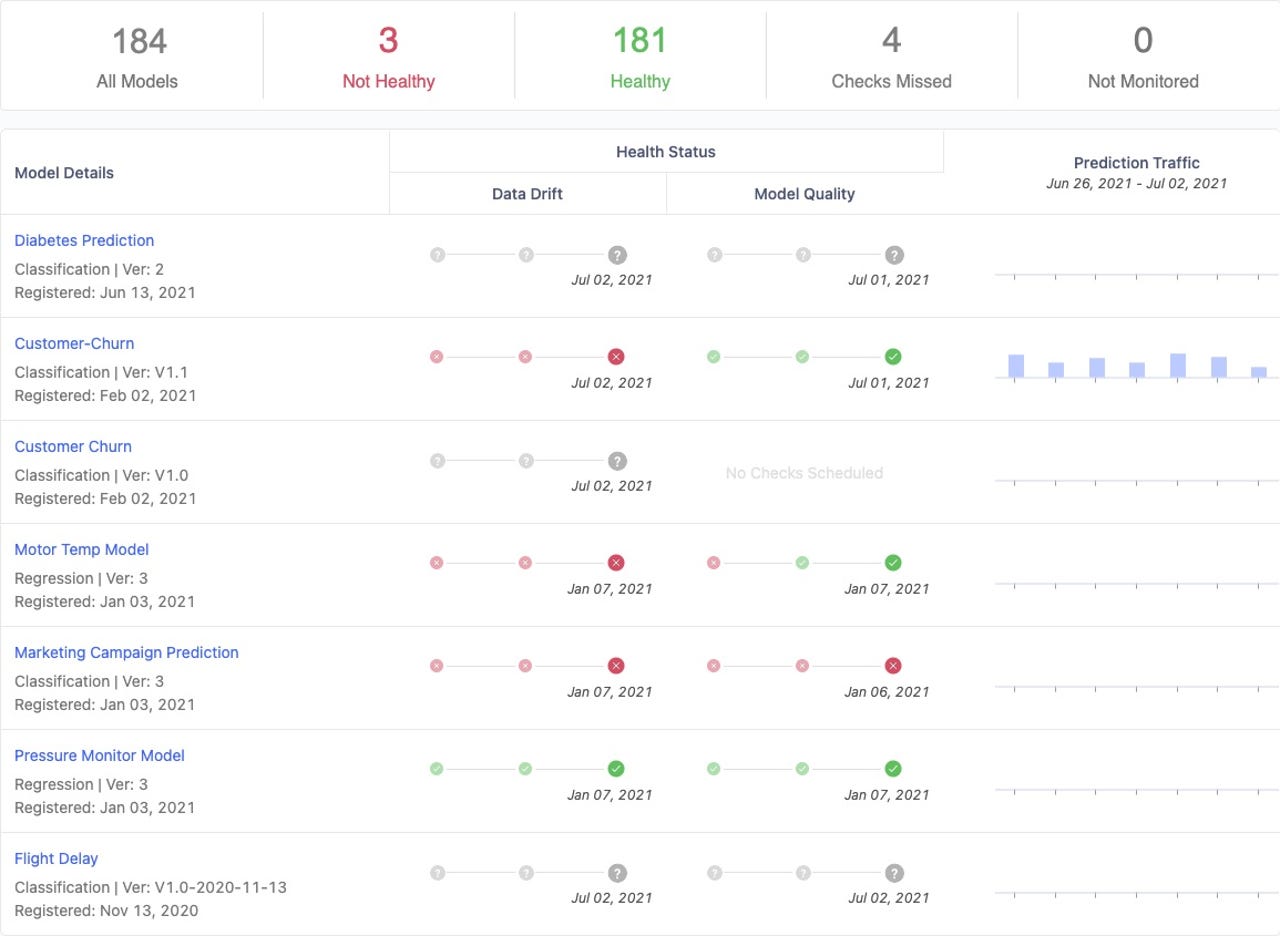
The Domino Model Monitor interface in Domino 4.6
MLOps is the machine learning operations counterpart to DevOps and DataOps. But, across the industry, definitions for MLOps can vary. Some see MLOps as focusing on ML experiment management. Others see the crux of MLOps as setting up CI/CD (continuous integration/continuous delivery) pipelines for models and data the same way DevOps does for code. Other vendors and customers believe MLOps should be focused on so-called feature engineering -- the specialized transformation process for the data used to train ML models. For others, MLOps is about everything after model development, including maintaining models in a repository, deploying them, and monitoring their operational health, performance and accuracy.
Dominoes, from end to end
A few vendors see MLOps as encompassing all of the above. One such vendor is Domino Data Lab, which is today announcing a new release -- Domino 4.6 -- of its end-to-end MLOps platform. And because Domino focuses on all facets of machine learning operations, it hasn't added new ones, but has instead significantly improved a few of them: model monitoring, cloud deployment and supported distributed computing environments for model development and training.
The monitoring improvements tell the tale of two MLOps cities. In one, live customers who are still phasing ML into their businesses or even just kicking ML's tires. For them, the mere presence of monitoring is sufficient. On the other side live customers who have graduated to doing ML at scale, with hundreds or even thousands of deployed models. For this cohort, monitoring needs to scale.
Monitoring and cloud and compute, oh my
ZDNet spoke with Domino Data Lab co-founder and CEO Nick Elprin, who gave us the details on Domino 4.6. He first explained, for that group needing high-performance model monitoring, that Domino Model Monitor (DMM - pictured in the screenshot above) has been enhanced to be elastic and scalable. In fact, Elprin says, users will enjoy up to 100x scale improvement in the performance of Domino's data drift and model drift detection. Drift detection is critical to keeping models accurate and fair. In marketing applications, that can make for higher customer satisfaction. Other scenarios include more responsible approval of benefits and claims, or more accurate fraud detection.
Domino 4.6 also supports cloud deployment to Microsoft Azure and Google Cloud, as opposed to just Amazon Web Services. Specifically, connection to data in Azure Data Lake Storage (ADLS) and Google Cloud Storage (GCS) is now supported in addition to data in Amazon S3. Moreover, monitoring extends to models deployed to all three cloud providers' Infrastructure as a Service (Iaas) and Kubernetes layers. Elprin explained these capabilities have been added in direct response to demand from customers with multi-cloud strategies, looking to avoid lock-in to any specific cloud provider.
Finally, in response to the ever-greater need for compute power in order to train more models, more quickly, Domino is extending compute support to include Ray and Dask, rather than just Apache Spark. Ray is a distributed execution framework that can parallelize workloads across CPUs and cores on a single machine, across cloud infrastructure, or on Kubernetes clusters. Dask is a Python parallel computing library that implements scaled, parallelized versions of common Python data science libraries like NumPy, Pandas, and scikit-learn. Ray and Dask can be used individually or, using the aptly named Dask on Ray, can be combined.
Breaking the code
In his discussion with ZDNet, Elprin explicated some of the major differences, as he sees them, between DevOps and MLOps. I'll do my best to summarize that explication here.
To begin with, ML models are not mere code; they use more data and need much more intensive compute than typical application and server-based code do. In addition, data science is like research -- data scientists need to experiment, trying lots Python (or R) libraries, various algorithms and, more generally, different approaches or ideas, before getting something that works. This is comparable to the way natural scientists need to test various hypotheses in their own work. Also, with models, you can't just write unit tests, as models are more probabilistic than deterministic.
With all this in mind, Domino's move to enhance its monitoring capabilities, and support numerous cloud and compute environments, makes perfect sense. Data scientists don't just need to debug their code and make sure it's running. They need to experiment with it, track it, deploy it and continually evaluate its efficacy. That's why MLOps is its own category, and ostensibly why Domino takes a scorecard approach to MLOps capabilities, rather than a checklist approach.
Domino says existing customers can upgrade to the 4.6 release immediately.