Facebook open-sources NetNORAD, network trouble-shooter programs

You think your network has problems? Try managing Facebook's networking infrastructure with its billion plus daily users and data centers throughout the world. At this size, equipment failures occur every day. To try to find interruptions and automatically mitigate them within seconds, Facebook created NetNORAD.
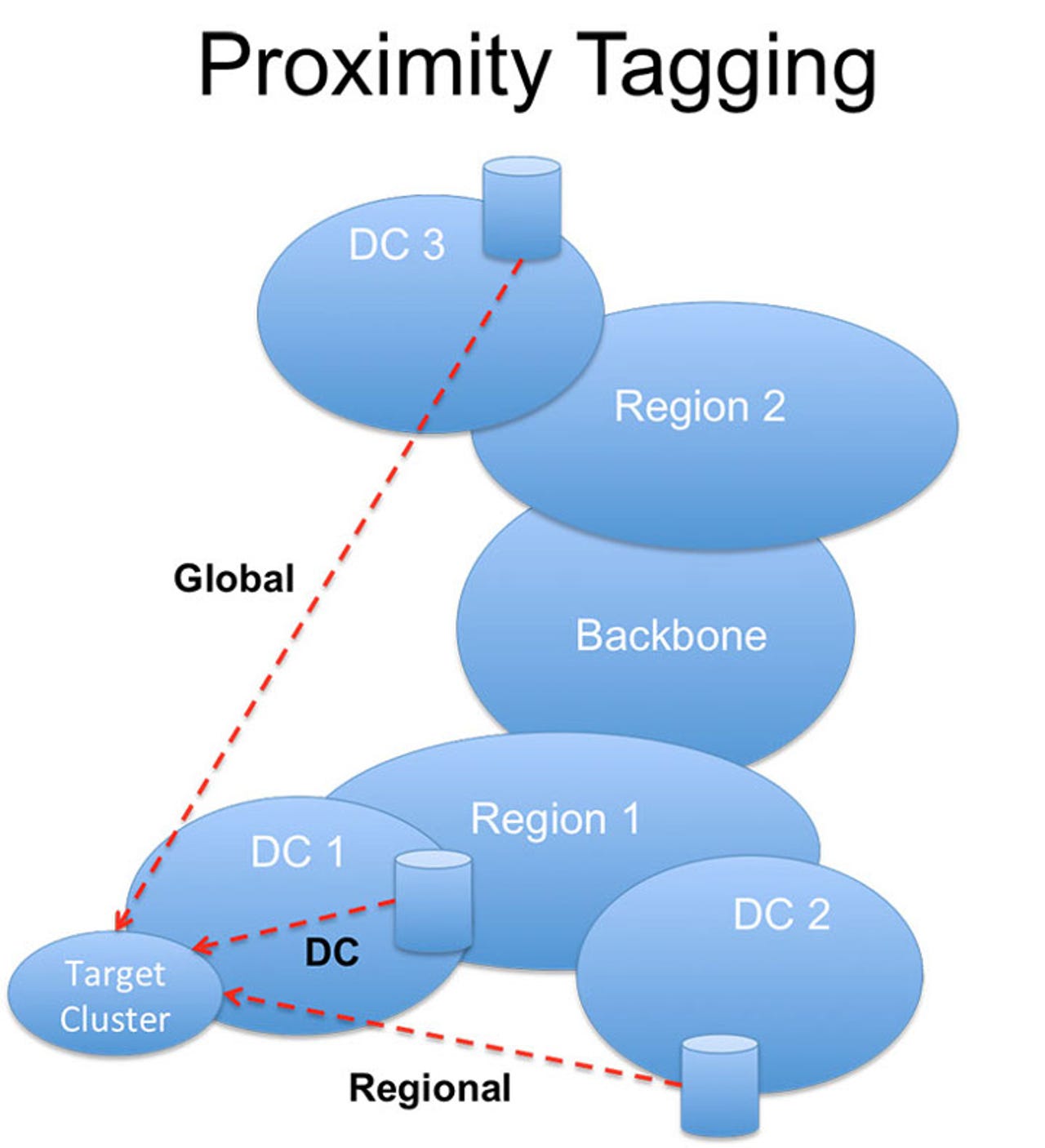
NetNORAD proximity tracking.
NetNORAD looks for the same kind of problems that you probably use Simple Network Management Protocol (SNMP) to hunt down. These approaches take at least minutes and sometimes they give "gray failures" where either the problem is not detectable by traditional metrics, or the device cannot properly report its own malfunctioning.
Facebook's answer to this is NetNORAD. This is a system that "treats the network as a 'black box' and troubleshoots network problems independently of device polling."
So how does it do that? Facebook has chosen to do it by measuring its network's packet loss ratio and latency. As any network administrator knows when those start going wrong, something bad's happening on the network. So NetNORAD runs UDP pingers and responders on each of its services. Whenever the packet loss and latency starts going up between these simple programs, NetNORAD knows to start looking deeper into the network for trouble.
Oh, why UDP instead of TCP? Because Facebook stateless TCP probing (SYN-RST) creates too much network noise and confuses application monitoring systems. Other methods, such as stateful probing with TCP (SYN-SYN/ACK), is too server resource-intensive. Facebook ruled out Internet Control Message Protocol (ICMP) because it can result in equal-cost multi-path routing (ECMP) problems.
Besides, Facebook found that most of the time, UDP and TCP share the same network forwarding behavior. At the same time, UDP is simpler and allows for direct measurement of underlying packet loss and network latency. UDP also enabled Facebook to embed information in the probes, such as multiple time-stamps to better measure the network's packet round-trip time (RTT).
In practice, Facebook follows the usual hierarchical network structure. At the lowest level there are servers mounted in racks, which are organized in clusters. A collection of clusters housed in the same building and serviced by a common network form a data center (DC). The data centers in turn are aggregated via a network that interconnects them within the same region and attaches to the Facebook global backbone network. So far, so ordinary.
Across this network, Facebook deploys at least two pingers in rack and responders on all machines. All pingers share a single global target list, which consists of at least two machines in every rack. The pingers can send packets quite fast, up to 1 maximum packets per second (mpps), The total aggregate probing rate can climb as high as hundreds of Gbps.
The network data is then aggregated to measure the average packet loss, loss variance, and percentiles of RTT. This data is then time-stamped and written to Scribe. The Scribe program is Facebook's own open-source distributed real-time logging system. Now the data is fed to Scuba. Scuba is Facebook's distributed in-memory store for doing human-readable, real-time, ad-hoc analysis of arbitrary data-sets.
Armed with the data NetNORAD constantly runs a dedicated alarming process. This tracks packet loss for each cluster from three different viewpoints, Data-Center, Region, and Global, every ten-minutes. The end result of this level of tracking is that NetNORAD can typically sound an alarm with 20-30 seconds of the start of a network problem.
False positives are weeded out by pingers implementing outlier detection logic. This checks to see if the targets are reporting packet loss at too high a volume relative to the general population. NetNORAD also double-checks by selecting targets from known healthy machine sets.
Using proximity tagging, NetNORAD uses a basic form of fault isolation by running alarm correlation analysis. Essentially:
- If loss is reported to cluster at DC, Region, and Global proximity tags, then the fault is likely localized in the data center. This is the rule of root cause isolation.
- If all clusters within a data center report packet loss, then the issue is likely to be a layer above the clusters. This is the rule of downstream suppression.
We're still a long way from pinpointing the exact fault location. So next NetNORAD automatically runs fbtracert.This is another Facebook open-source program. Likethe popular Linux traceroute networking tool, it explores multiple paths between two endpoints in the network in parallel. In addition, it can analyze the packet loss at every hop and correlate the resulting path data to find the common failure point.
Fbtracert's not perfect. It doesn't find all the failures. Then Facebook network administrators start mining Scuba for end-to-end packet loss and other network analysis tools such as WireShark.
To get pass that last bit, where network trouble-shooting goes from taking half-a-minute to half-an-hour, Facebook wants your help. The company is open-sourcing both to promote the concepts of end-to-end fault detection and to help engineers operate their networks more effectively.
The first components to be open-sourced are the pinger and responder. These are written in C++ under the BSD license. Facebook is also open-sourcing the fbtracert utility, which is written in Go with the BSD license. This isn't a complete fault-detection system, but it's a good start.
As networks grow ever larger and downtime grows ever more unacceptable, I see this move as being a major step forward for network trouble-shooting. Besides being useful for network administrators I can also see developers creating new network administration tools around these programs to compete with such network administration mainstays as Nagios, OpenNMS, and Zenoss Core.
Related Stories: