Facebook open sources tower of Babel, Klingon not supported

Like the fabled tower of Babel, AI researchers have for years sought a mathematical representation that would encapsulate all natural language. They're getting closer
Tuesday, Facebook announced it is open-sourcing "LASER," a PyTorch tool for "Language-Agnostic SEntence Representations."
The code underlies a stunning research report Facebook unleashed in December, titled, "Massively Multilingual Sentence Embeddings for Zero-Shot Cross-Lingual Transfer and Beyond." The work showed how Facebook were able to train a single neural network model to represent the structure of 93 different languages in 34 different alphabets.
That research was able to develop a single "representation," a mathematical transformation of sentences, in the form of vectors, that encapsulates structural similarities across the 93 languages. That single mathematical vector model common to the 93 languages was then used to train the computer on multiple tasks where it had to match sentences between pairs of languages it had never seen before, such as Russian to Swahili, a feat known in the trade as "zero-shot" language learning.
Also: China's AI scientists teach a neural net to train itself
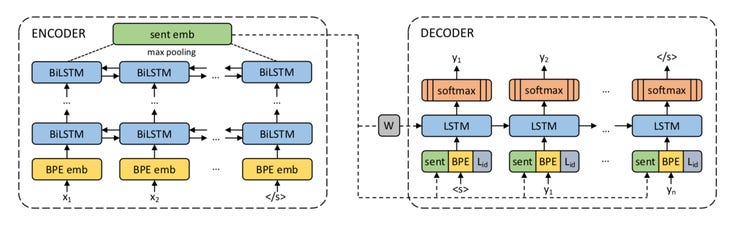
The neural network model of encoder and decoder, using LSTM circuits.
"Semantically similar sentences in different languages are close in the resulting embedding space," is the technical way to describe the representation.
As they explain it, a big motivation for the work is "the hope that languages with limited resources benefit from joint training over many languages."
That said, there are still limitations here: Klingon is explicitly not supported, for example. And Yiddish, while being included for test purposes in a supplementary step, has too few texts to achieve any noteworthy results with these tools.
With the code, posted on GitHub, you get what's called an "encoder-decoder" neural network, constructed out of so-called Long Short-Term Memory (LSTM) neural nets, a workhorse of speech and text processing.
As the authors, Michael Artetxe and Holger Schwenk, with Facebook AI Research, detailed in their December article (posted on the arXiv pre-print server), they built upon previous approaches that seek to find a sentence "embedding," a representation of the sentence in vector terms.
A sentence in one of the 93 "source" languages is fed into one batch of the LSTMs. They turn the sentence into a vector of fixed length. A corresponding LSTM called a decoder tries to pick out the sentence in either English or Spanish that corresponds in meaning to the source sentence. By training on numerous bilingual texts, such as "OpenSubtitles2018," a collection of movie subtitles in 57 languages, the encoder gets better and better at creating a single mathematical embedding, or representation, that helps the decoder find the right matching English or Spanish phrase.
Also: MIT ups the ante in getting one AI to teach another
Once this training phase is completed, the decoder is thrown away and the encoder exists as a single pristine LSTM into which languages can be poured to be output in another language on a variety of tests.
For example, using a data set of bilingual phrases supporting English and 14 languages, developed by Facebook in 2017, called "XNLI," tests whether the system can compare sentences across new language pairs, such as French to Chinese. Even though there's been no explicit training between French and Chinese, the universal encoder is able to train the a classifier neural net to say whether the sentence in French entails a given sentence in Chinese, or contradicts it.
The LASER system "maps" languages into a common "embedding."
Across these and a variety of other tests, Artetxe and Schwenk report that they've topped not only Facebook's previous efforts but also those of Google's AI team, which in October reported their benchmark results for an encoder called "BERT."
(A blog post announcing the code release has further details about the work.)
Artetxe and Schwenk are carrying on the tradition of encoder-decoder work that's been going on for years now. Some of those models have been widely adopted for language processing, such as Ilya Sutsekever's "seq2seq" network developed in 2014 at Google.
Also: Google suggests all software could use a little robot AI
And the overall goal of trying for a single common representation of all languages has a rich history in recent years. The ethos of "deep learning" is that a representation of any kind of information is richer if there are "constraints" applied to that representation. Making one neural net lift 93 languages is a pretty serious constraint.
Google's "Neural Machine Translation" system, introduced in 2016, was also seeking to prove a kind of universal representation. Researchers who constructed that system wrote in 2017 that their work suggested "evidence for an interlingua," a "shared representation" between languages.
But Google used encoder-decoders for common translation pairs, such as English and French. The LASER approach, creating one single encoder for 93 languages, moves well beyond what has been done thus far.
The encoder can match sentences between language pairs for which it was not trained.
Must read
- 'AI is very, very stupid,' says Google's AI leader CNET
- Baidu creates Kunlun silicon for AI
- Unified Google AI division a clear signal of AI's future TechRepublic
Bear in mind a couple limitations before you download the code and get started. One is that only some of the 93 languages have sufficient training and test data to make possible real evaluations, such as the 14 languages in the XLNI benchmark suite. The authors have come up with their own corpus of 1,000 sentence pairs for 29 extra languages not included in the 93. They include Yiddish, the Frisian language of the Netherlands, Mongolian, and Old English, but the results fall short of the other languages. Hence, paucity of data, in the form of written texts, is still a challenge for many languages.
The other thing to keep in mind is that LASER won't remain the same neural net code base that's on GitHub today. In the conclusion to their paper, Artetxe and Schwenk write that they plan to replace the encoder-decoder system they've developed with something called a "Transformer" used by Google's BERT.
"Moreover," they write, "we would like to explore possible strategies to exploit monolingual training data in addition to parallel corpora, such as using pre-trained word embeddings, backtranslation, or other ideas from unsupervised machine translation."
Scary smart tech: 9 real times AI has given us the creeps
Previous and related coverage:
What is AI? Everything you need to know
An executive guide to artificial intelligence, from machine learning and general AI to neural networks.
What is deep learning? Everything you need to know
The lowdown on deep learning: from how it relates to the wider field of machine learning through to how to get started with it.
What is machine learning? Everything you need to know
This guide explains what machine learning is, how it is related to artificial intelligence, how it works and why it matters.
What is cloud computing? Everything you need to know about
An introduction to cloud computing right from the basics up to IaaS and PaaS, hybrid, public, and private cloud.