Google's DeepMind claims major milestone in making machines talk like humans

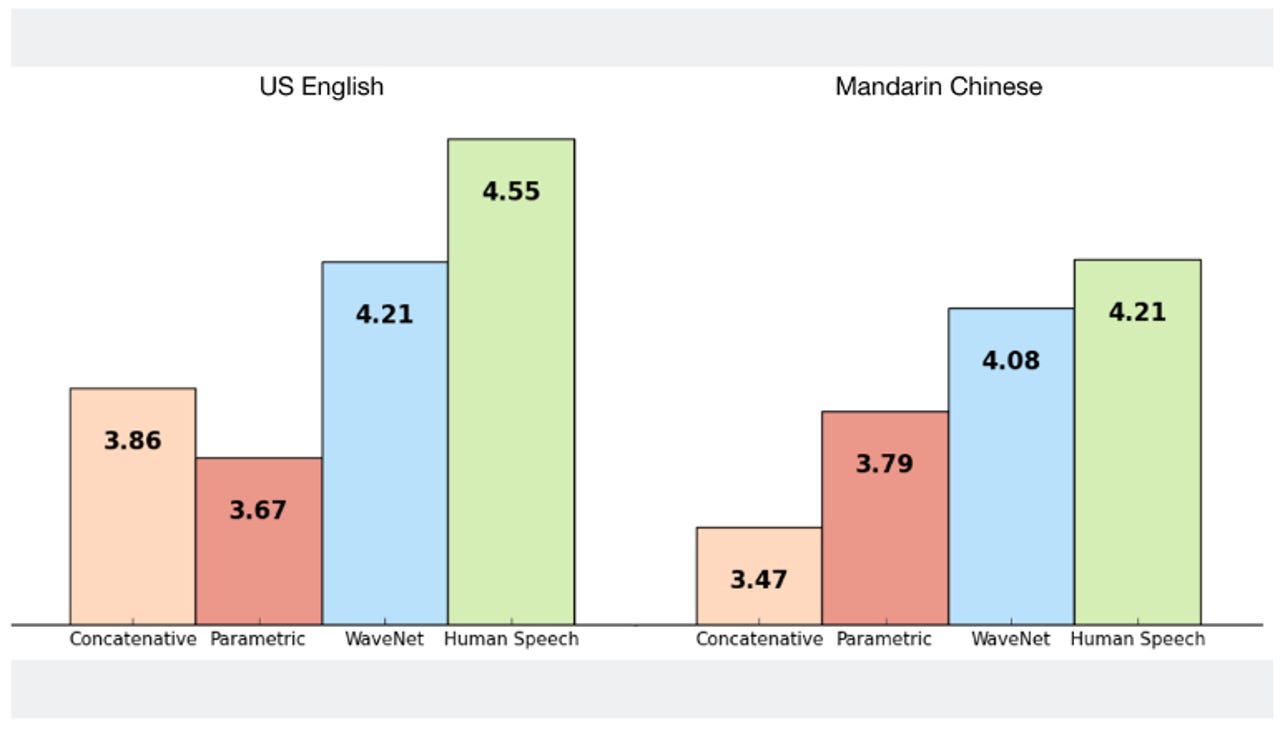
On a scale from 1 to 5, WaveNet's quality of voice outstrips Google's current best parametric and concatenative systems.
Google's UK artificial intelligence lab, DeepMind, has developed a deep neural network that produces more human-like speech than Google's previous text-to-speech (TTS) systems.
DeepMind has published a new paper describing WaveNet, a convolutional neural network it says has closed the gap between machine-generated and human speech by 50 percent in both US English and Mandarin Chinese.
Not only this, but the network can also seamlessly switch between different voices and generate realistic music fragments.
The researchers note that today's best TTS systems, generally considered to be powered by Google, are built on "speech fragments" recorded from a single speaker. Those fragments are then reconstructed to create utterances.
While this approach, known as concatenative TTS, has produced natural-sounding speech, it is generally limited to a single voice unless a new database is provided.
Another technique called parametric TTS, which relies on voice codec synthesizers, may be more flexible, but this hasn't achieved as natural-sounding speech.
WaveNet differs by being trained on raw audio waveform from multiple speakers and then using the network to model these signals to generate synthetic utterances. Each sample it creates is fed back into the network to generate another sample.
"As well as yielding more natural-sounding speech, using raw waveforms means that WaveNet can model any kind of audio, including music," DeepMind researchers note in a blogpost.
WaveNet is also capable of learning the characteristics of multiple voices, from both male and female speakers, including breathing and mouth movements.
The company provides samples in the post in which WaveNet can be heard saying the same thing in several different voices, both in English and Mandarin.
"To make sure [WaveNet] knew which voice to use for any given utterance, we conditioned the network on the identity of the speaker. Interestingly, we found that training on many speakers made it better at modelling a single speaker than training on that speaker alone, suggesting a form of transfer learning," the researchers note.
One factor that may limit WaveNet's application to Google's products is that the approach requires vast amounts of data and computing power. According to DeepMind, modelling raw audio typically requires the processing of at least 16,000 samples per second, but this approach was necessary to create realistic speech sounds.
DeepMind also said WaveNet can easily be reapplied to music audio modelling and speech recognition.
MORE ON ARTIFICIAL INTELLIGENCE
- Intel snaps up Movidius to create future computer vision, VR tech
- LG investing in AI for smart appliances, autonomous driving
- IBM Watson: Here's what a movie trailer crafted by an AI looks like
- Deakin Uni, Ytek kick off machine learning algorithm research for simulation training
- Google adds AI-powered insights stream into Analytics mobile app
- IBM to use AI to tame big data in its second African research lab
- Automated drones navigate and inspect cell towers without GPS
- TechRepublic: New IBM Linux servers could boost AI and big data efforts
- CNET: Facebook's Zuckerberg is almost ready to show off his AI