IBM Research unveils framework for scaling AI workflows across the hybrid cloud

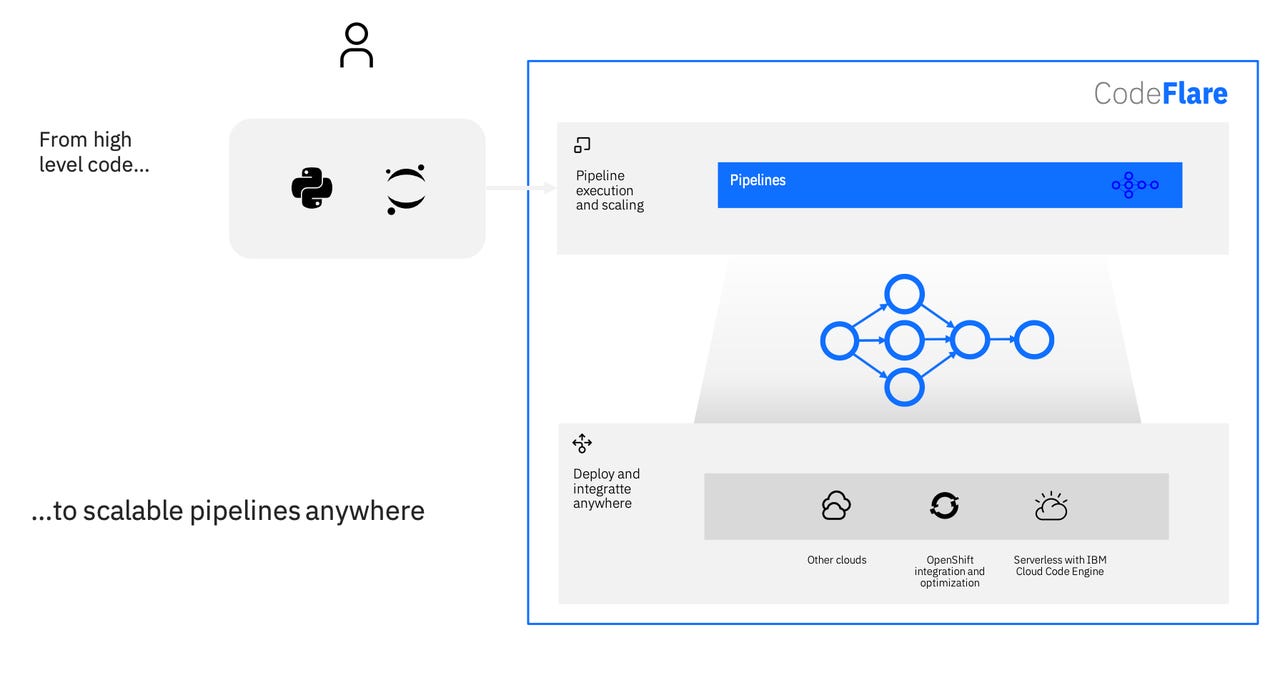
IBM Research on Wednesday unveiled CodeFlare, a new framework for integrating and scaling big data and AIworkflows in a hybrid cloud environment. The open-source framework aims to help developers cut back the time they spend creating pipelines to train and optimize machine learning models.
CodeFlare was built on Ray, an open-source technology from UC Berkeley. It builds on Ray with specific elements that make it easier to scale workflows. Using a Python-based interface for pipelines, CodeFlare makes it easier to integrate, parallelize and share data. This helps unify pipeline workflows across multiple platforms without requiring data scientists to learn a new workflow language.
While IBM says CodeFlare pipelines run easily on its new serverless platform IBM Cloud Code Engine and Red Hat OpenShift, developers can deploy it just about anywhere. CloudFlare also helps developers integrate and bridge pipelines with other cloud-native ecosystems by providing adapters to event triggers (such as the arrival of a new file). It also provides load and partition data from a variety of sources, including cloud object storage, data lakes and distributed filesystems.
CodeFlare is available on GitHub, and IBM is sharing examples that run on IBM Cloud and Red Hat Operate First. Developers already using CodeFlare, IBM said, have cut back their work by months.
Hybrid cloud is a critical part of IBM's growth strategy. In the fiscal year 2020, IBM's total cloud revenue went up by 20%, in large part thanks to hybrid cloud programs offered by IBM-owned Red Hat.
Prior and related coverage:
- With Whitehurst stepping down, where do IBM and Red Hat go from here?
- Hybrid cloud, on-premises workloads get their day in the sun, but the forecast is still cloudy.
- Where is IBM's hybrid cloud launchpad?
- AWS, DeepLearning.ai aim to bridge the scaling gap with machine learning models via Coursera specialization.