KVM creators open-source fast Cassandra drop-in replacement Scylla

Two key figures behind popular open-source hypervisor KVM are today unveiling a new NoSQL database that they describe as a far faster drop-in replacement for Apache Cassandra.
The Scylla database, from KVM inventor Avi Kivity and the man who oversaw the hypervisor's development, Dor Laor, offers what they say is 10 times better throughput and latency than wide column store Cassandra, while maintaining complete compatibility.
Laor, who is now founder and CEO at commercial firm ScyllaDB, where Kivity is CTO, argues that column-store databases like Cassandra aim to provide good scale-out performance, high availability and disaster recovery.
"But the main problem with Cassandra, which actually leads this very large segment, is performance. It doesn't live up to its promise in terms of throughput. Sometimes there's a requirement to use hundreds of servers, sometimes thousands of servers, to meet the performance goals of the business," Laor said.
"Apple runs 75,000 Cassandra servers. So it's a huge capacity that's designed to cope with the limited performance Cassandra gets you. There's also a latency hurdle because Cassandra is implemented as a regular application and - even worse - as a JVM one, which often suffers from Java caveats like garbage-collection stall. Java is an awesome language but for management applications, not for I/O-intensive ones."
To create Scylla, named after the classical Greek sea monster, its creators took the best aspects of Cassandra and rebuilt them from the bottom up, Laor said, using a design that automatically maximises the use of hardware resources.
"It's a drop-in replacement for the Cassandra cluster and the server side. We've implemented them from scratch, so there's no need to use any components from the Cassandra system to run the server side," he said.
"Application writers do need Cassandra client code to connect to the server and we specifically emphasise that so they won't experience any change in their environment.
"The code runs as before. You administer the code in the same way, using the same storage format Cassandra uses. So you can shut down your Cassandra installation, bring up a Scylla infrastructure and that's it - you'll get automatically 10x performance improvements."
To achieve those claimed gains, the various components that make up Scylla have been engineered to squeeze every bit of performance out of modern hardware, Laor said, and include new caching, task scheduler, and a better storage engine.
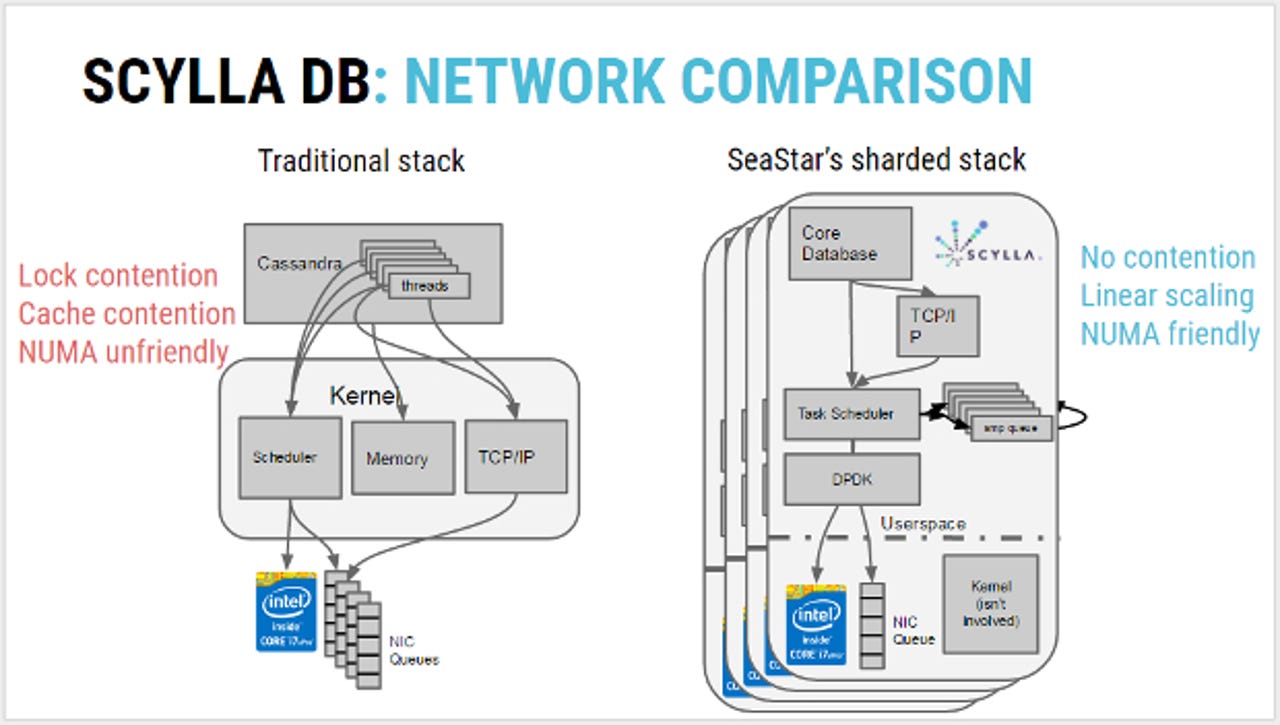
But the central design concept is shard per core - sharding is the way databases are partitioned to make them faster and more manageable.
"Everybody does sharding in a cluster but usually the granularity is per server. In our case we build it per core. The result is each of the shards within the server is fully independent, so there's no need to lock, there are no regular threads that you need to protect your data structures," he said.
"Locking is very costly, and data structures don't need to undergo copies. So when we copy, when we send data out to the network or read data from the disk, there's no need to copy - everything is local to these shards. Those shards per core are transparent to the user, so users don't see them."
The independence of the shard means there is no contention, with each one managing its own resources, whether that is a networking card, memory or the CPU itself.
"Each core has its own CPU, its own memory - it's local to that node so it's multi-socket friendly - that's NUMA-friendly [non-uniform memory access]. It's expensive to access memory between one core and one socket with memory that belongs to another socket," Laor said.
"Within a server we have lots of such shards - exactly the amount of the x86 cores that exists in that server. The bigger the server grows with the newer CPUs that Intel produces, the better for us because we scale up linearly. In the relations between the cores, everything is independent."
Scylla has been written in C++ 14 - together with the project's Seastar programming model. The Seastar C++ application framework is designed for high concurrency server applications and described on GitHub as "an event-driven framework allowing you to write non-blocking, asynchronous code in a relatively straightforward manner".
According to Laor, another major difference from Cassandra lies in the way Scylla handles caching.
"Usually regular databases - every database except for Oracle - don't have a sophisticated block cache and rely on the Linux page cache instead. Now Linux page cache does a great job. But if you need just a 100-byte object then the Linux page cache will host that in a full 4,000-byte page - just for 100 bytes. So we have our very own cache and a renovated storage engine," he said.
Users have a number of ways to tap into Scylla's projected performance improvements.
"If you pay Amazon for 500 virtual machines running Cassandra, then you'll be able to carry out the workload with 50 and have huge savings. Another option is just to have huge margins to handle traffic spikes," Laor said.
"Usually with Cassandra it's really hard to model the data correctly and small mistakes mean you suffer a lot. Because data modelling is hard, some users choose to use Cassandra as a key-value implementation, which is a pity. So in our case, it'll be much easier to model data, and wrong data modelling won't bring disastrous performance as it does with Cassandra."
To solve Cassandra bottlenecks, some users apply caches in front of the database, either Memcached or Redis.
"In our case, the database itself is as fast as Redis, so there's no need - and no need to manage a Redis installation. You can just utilise all the memory from those Redis machines and apply it to the database and get even better performance than you had before with Redis," he said.
Given Kivity and Laor's backgrounds, it is unsurprising that Scylla is going to be an entirely open-source project, available under a GNU Affero General Public License, or AGPL.
Although the immediate focus is on Cassandra, plans include applying the technology behind Scylla in other areas.
"We're starting with Cassandra and not the other NoSQL stores such as Redis or HBase or even traditional SQL databases. But up next we intend to expand to other places because we have a terrific throughput machine here, which is highly available and can do disaster recovery," Laor said.
"With this machine of ours we'll be able to go in other directions, either vertical and integrate really well with analytics engines like Spark or go horizontal and add protocols. We have great infrastructure with gossip [comms protocol] and a really flexible replication model. But of course first we'll be 100 percent focused on the core database. There's much to improve and a lot of users to attract."
More on databases
- Engineering out of Oracle: how SaaS threatens Oracle's database core
- Amazon's MySQL database challenger Aurora exits preview
- IBM acquiring Database-as-a-Service provider Compose
- Couchbase NoSQL Database gets the SQL Religion
- Oracle and Mirantis put Database 12c on OpenStack private clouds
- Google's Bigtable goes public as a cloud managed NoSQL database
- The NoSQL database glut: What's the real price of the current boom?