Microsoft and Nvidia create 105-layer, 530 billion parameter language model that needs 280 A100 GPUs, but it's still biased

Nvidia and Microsoft have teamed up to create the Megatron-Turing Natural Language Generation model, which the duo claims is the "most powerful monolithic transformer language model trained to date".
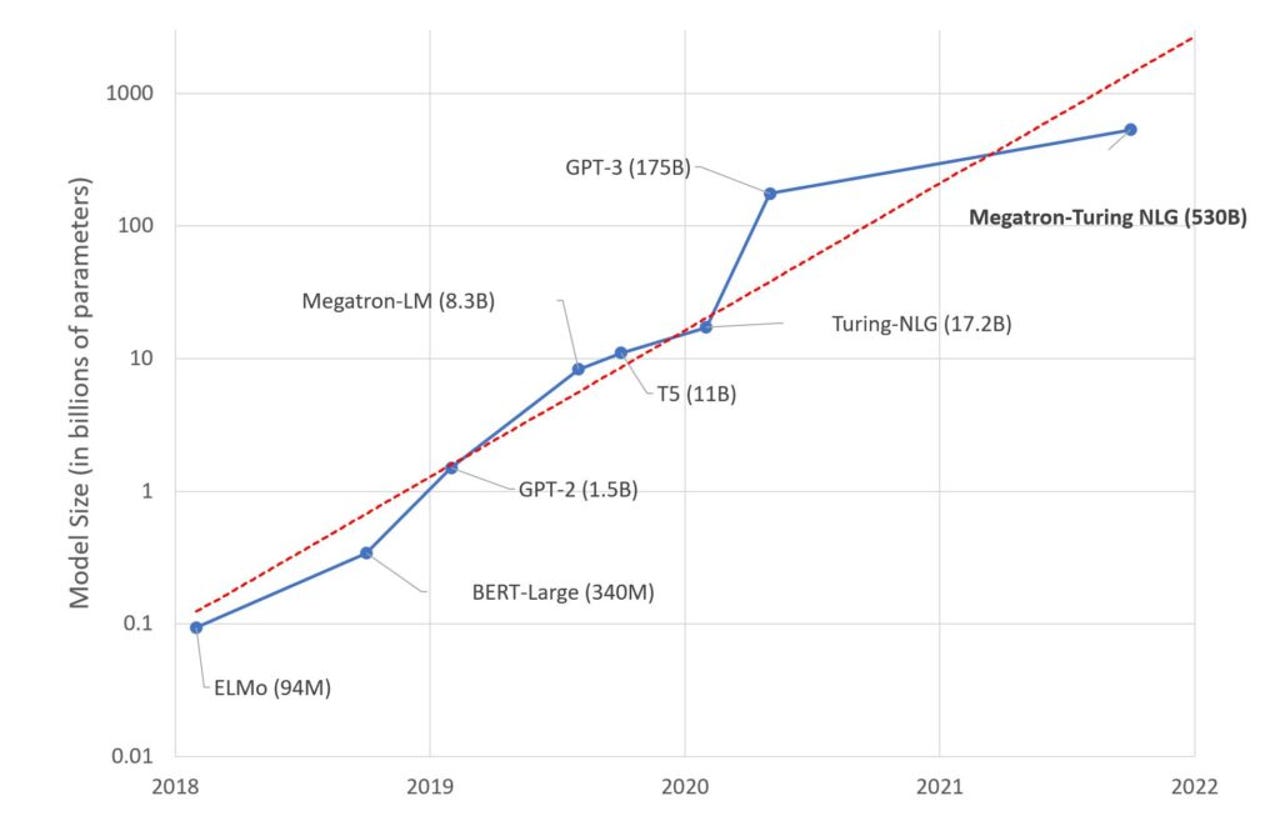
The AI model has 105 layers, 530 billion parameters, and operates on chunky supercomputer hardware like Selene.
By comparison, the vaunted GPT-3 has 175 billion parameters.
"Each model replica spans 280 NVIDIA A100 GPUs, with 8-way tensor-slicing within a node, and 35-way pipeline parallelism across nodes," the pair said in a blog post.
The model was trained on 15 datasets that contained 339 billion tokens, and was capable of showing how larger models need less training to operate well.
However, the need to operate with languages and samples from the real world meant an old problem with AI reappeared: Bias.
"While giant language models are advancing the state of the art on language generation, they also suffer from issues such as bias and toxicity," the duo said.
"Our observations with MT-NLG are that the model picks up stereotypes and biases from the data on which it is trained. Microsoft and Nvidia are committed to working on addressing this problem.
"Our observations with MT-NLG are that the model picks up stereotypes and biases from the data on which it is trained. Microsoft and Nvidia are committed to working on addressing this problem."
It wasn't so long ago that Microsoft had its chatbot Tay turn full Nazi in a matter of hours by interacting on the internet.
Related Coverage
- AI-fueled app Natural offers new interface for consumer transactions
- Watch out, GPT-3, here comes AI21's 'Jurassic' language model
- OpenAI proposes open-source Triton language as an alternative to Nvidia's CUDA
- How AI and 5G will power the next wave of innovation
- AI industry, obsessed with speed, is loathe to consider the energy cost in latest MLPerf benchmark
- OpenAI says 'Hello, World!' with private beta for Codex code generation tool