Microsoft cloud outages continue as Office and Outlook customers report problems

Last week, a major Azure Active Directory authentication issue affected users worldwide. A follow-up Exchange/Outlook issue later in the week affected European and Indian Office 365/Microsoft 365 customers. This week, Microsoft's cloud services issues are continuing, affecting a number of Exchange, Outlook, Teams and SharePoint users.
Microsoft was still warning some Office 365/Microsoft 365 customers as this week kicked off of some possible residual Exchange/Outlook issues, including problems accessing the admin center and syncing issues between Outlook mobile and desktop. I asked Microsoft if these issues were related to last week's Azure Active Directory authentication problems, but was told the company had no comment. (I am hearing the issues were likely not interrelated, for what it's worth.)
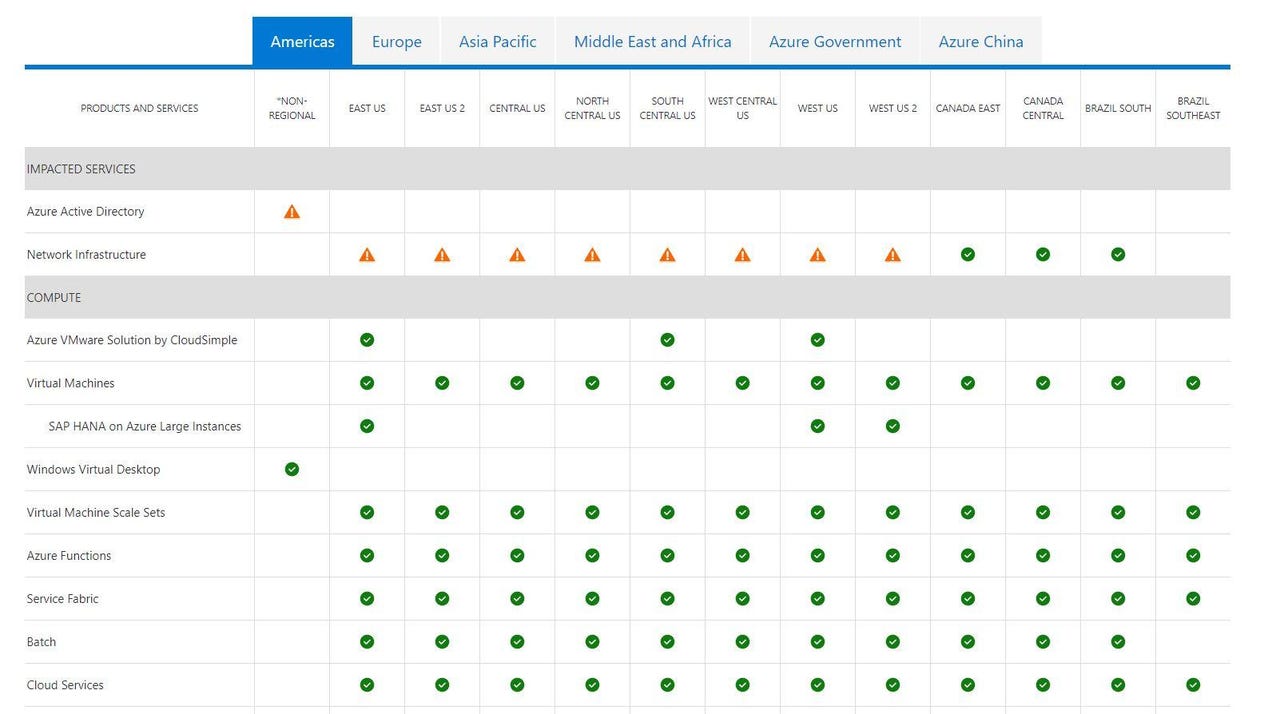
On October 7, users, primarily in the U.S., began reporting in the afternoon ET they were having issues accessing their admin center dashboards. Around 2:30 p.m. ET, users took to Twitter and other social channels to report they were unable to access Microsoft 365 services, including Teams, Exchange Online, Outlook.com, SharePoint Online and OneDrive for Business. At the same time, warnings of issues with Azure Active Directory and Azure Networking services popped up on the Azure status page.
Around 4:00 p.m. ET, some Office 365/Microsoft 365 customers began reporting their services were recovering. (For my part, I still cannot access my M365 Admin Center, even as of 5:00 p.m. ET.)
The Azure team also posted a preliminary root cause analysis around the same time on the issues users experienced accessing Microsoft or Azure services. In that report, Microsoft said between roughly 2 p.m. ET and 3:40 p.m. ET a subset of customers encountered issues connecting to resources that leveraged the Azure network infrastructure across regions. ("Resources with local dependencies in the same region should not have been impacted," according to company officials.)
Microsoft identified "a recent change (that) was applied to WAN (wide-area-networking) resources causing connectivity latency or failures between regions" as the cause. To mitigate, the Azure team rolled back the recent change to a healthy configuration.
On October 7, the Azure team also noted that some subset of customers experienced traffic routing to "unhealthy backends" with Azure Front Door. Microsoft attributed that issue to a "configuration change (which) was deployed causing the incorrect routing of traffic" and reverted the change to fix the issue.
The Microsoft 365 team, for its part, attributed the inability to access services to a "network infrastructure change" which may have impacted multiple Microsoft 365 services, including Teams, Outlook, SharePoint, OneDrive for Business and Outlook.com. That same team also said it added this afternoon additional capacity to handle "an observed spike in admin center traffic caused by actions to mitigate a prior incident with similar impact."
After last week's Azure AD issue -- caused by the faulty testing of a change, coupled with a rollback failure -- this week's outage is not a good look for the Microsoft cloud.
Update (October 12): Microsoft has published a root cause analysis on the Azure status page for the October 7 outage.
As officials acknowledged last week, the culprit of this outage was an update of a component controlling WAN network traffic routing between Azure regions. For those wondering why this wasn't caught during testing, Microsoft's report says the main parameters of the new code (which was defective) were invoked only at production scale.
While the WAN SDN controller automatically recovered after a "transient issue," only some affected Azure services auto-migrated, including Azure Active Directory. But some other services "had to undergo manual intervention to recover," which resulted in the outage continuing for multiple hours. To see reports on some of the services affected by this outage, admins/users can go to their Microsoft 365 admin dashboards and look under Service Health History.
From my own dashboard:
"While the total duration of this WAN outage was 22 minutes of packet loss, wider impact was experienced through cascading services that leveraged the WAN.
Following the WAN coming back online, some services would have auto-mitigated, however, other services had to undergo manual intervention to recover. This could have led to varying times of impact across multiple Microsoft 365 services."
Among the services affected, according to my dashboard: SharePoint Online, OneDrive for Business, Exchange Online, Outlook and access to the Admin Center itself.