Microsoft's March 3 Azure East US outage: What went wrong (or right)?

Cloud
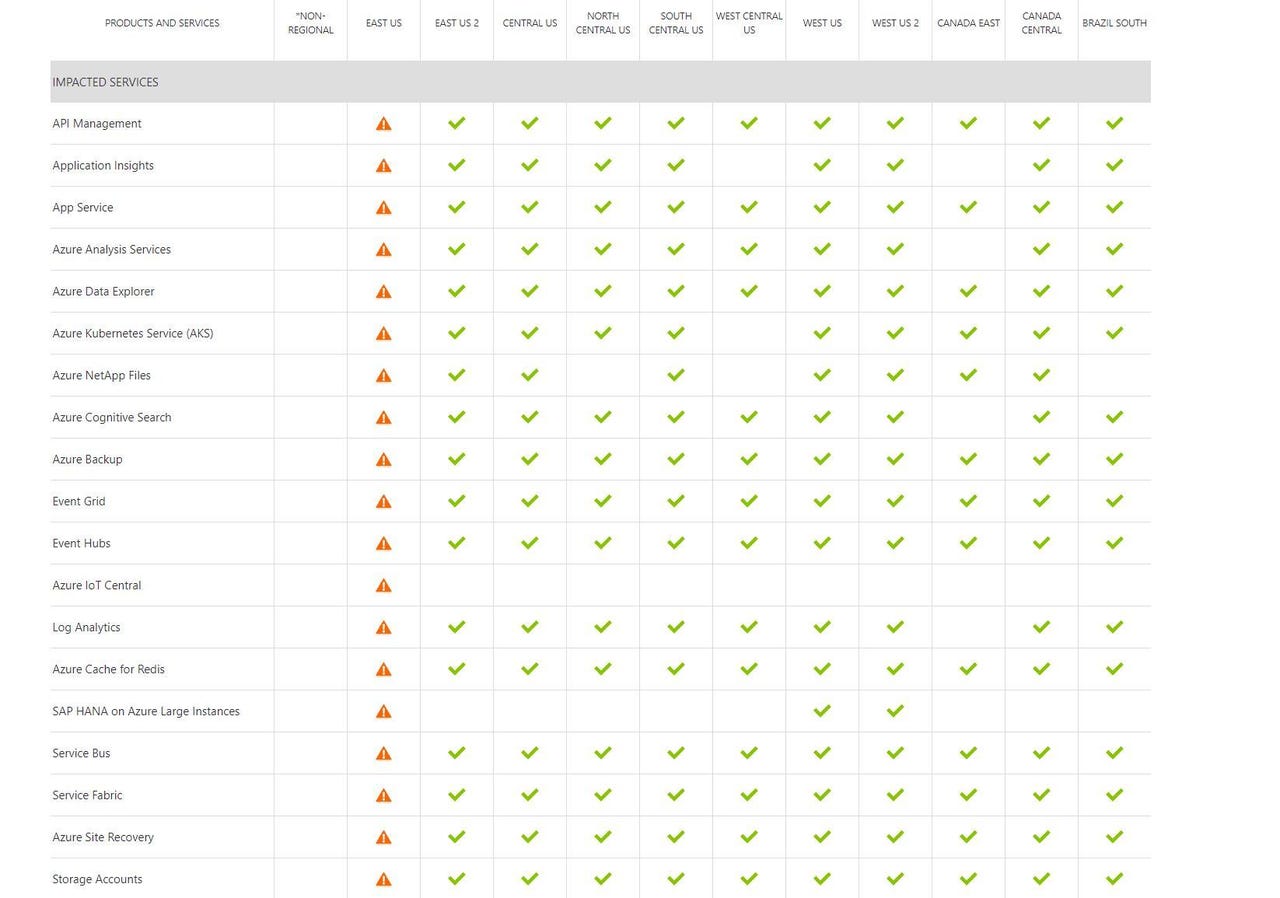
For more than six hours on March 3, almost all Azure services in Microsoft's East US region were encountering storage/connectivity problems, according to the company's Azure status page. (Screen capture by me of part of the March 3 status page is above.) On March 6, Microsoft provided a root cause analysis of what happened. As a number of customers thought, a temperature spike was at the heart of the issue.
Starting around 9:30 a.m ET and lasting until 3:50 p.m. ET, "a subset of East US customers may have experienced issues connecting to resources in this region," Microsoft's analysis notes. Microsoft says a malfunction in building automation control caused temperatures in multiple rooms of a datacenter in that region to spike, which affected Storage, Compute, Networking and dependent services.
The cooling system had N+1 redundancy, yet the failure caused "significant reduction" in cooling airflow, resulting in network devices becoming unresponsive, VMs shutting down and some storage hardware to go offline.
Microsoft had to reset the cooling system controllers, according to its root-cause report. After things cooled down, engineers had to power cycle and restore failed server hardware in groups, and then manually recover hardware and compute virtual machines that didn't automatically recover.
Microsoft says it is reviewing the building automation control system responsible for the incident, as well as the mechanical cooling system. Any issues they discover will be applied to other data centers in the same control and cooling systems.
Sounds pretty dire, doesn't it? Yet, surprisingly -- to me, at least -- there was very little outcry on Twitter about this. Usually my timeline lights up with complaints when any big Microsoft service goes down, even for a short period. On March 3, I saw a few individuals pinging the Azure Support account on Twitter and a few mentions of the East US situation on March 3, but compared to other Azure and Office 365 outages over recent years, this one barely registered a blip on the social media outrage scale.
I asked a couple of my contacts about this and them seemed mostly unaffected in spite of East US being one of Microsoft's most important and popular cloud regions. Maybe redundancy and failover plans actually worked? Maybe Twitter isn't the way cloud users are voicing their outage issues as much anymore?
Anyone got any information or theories about why this didn't seemingly affect more customers? I'm all ears.