MIT lets AI "synthesize" computer programs to aid data scientists

How to make artificial intelligence more approachable for ordinary mortals — that is, people who are neither programmers nor IT admins nor machine learning scientists — is a topic very much in vogue these days.
One approach is to abstract all the complexity by stuffing it in cloud computing operations, as was proposed by one AI startup described recently by ZDNet, Petuum, which aims to "industrialize" AI.
Another approach, presented this week by MIT, is to make machine learning do more of the work itself, to invent its own programs to crunch data in specific applications such as time series analysis. This is a hot area of AI in itself, having machines build the models that in turn perform the induction of answers from data.
Also: AI startup Petuum aims to industrialize machine learning
The researchers describe a way to automate the creation of programs that infer patterns in data, which means that a data scientist doesn't need to figure out the "model" that fits the data being studied.
The work is described in a paper posted at the Web site of the Association for Computing Machinery, available for free, titled "Bayesian Synthesis of Probabilistic Programs for Automatic Data Modeling." It is authored by Feras A. Saad, Marco F. Cusumano-Towner, Ulrich Schaechtle, Martin C. Rinard, and Vikash K. Mansinghka of MIT.
The problem Saad and colleagues are attacking is all the work that has to go into finding the right kind of program to analyze a given set of data. As they write, obstacles include "the need for users to manually select the model or program structure, the need for significant modeling expertise, limited modeling capacity, and the potential for missing important aspects of the data if users do not explore a wide enough range of model or program structures."
Also: MIT ups the ante in getting one AI to teach another
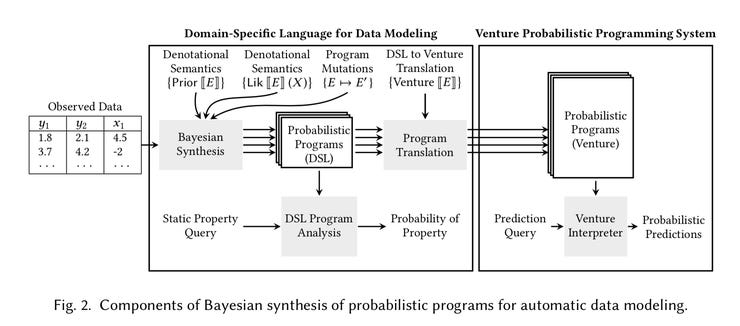
MIT researchers describe the process by which their Bayesian inference approach searches over the expressions within domain-specific languages to assemble a collection of algorithms that can analyze particular types of data.
To address that, they intend to let the the computer decide. Saad and colleagues carry on the tradition of recent years of "synthesizing" computer programs, having one program build another program. There have been lots of noteworthy examples of this, such as the 2014 effort by Google DeepMind scientists to build a "Neural Turing Machine." That project used what's called "recurrent neural networks" to discover simple computer algorithms, such as for copying and pasting text.
The authors colleagues distinguish themselves by designing programs that are "probabilistic," rather than classic "deterministic" programs. That means that the programs don't necessarily produce a predictable output given a certain input. Rather, the program's output will reflect the noise and uncertainty of the data put into them, exactly what you want if you're trying to asses probabilities in data. MIT has been focusing a lot on the probabilistic programming angle, hosting a conference on the matter last October.
To achieve this, the authors used the Bayesian approach to statistics. They sample a bunch of computer programs and rate the likelihood of each program as a possible solution for handling the data one wants to study. As the authors put it, among all the approaches to automating the design of computer programs, theirs is "the first Bayesian synthesis of probabilistic programs."
Also: Google Brain, Microsoft plumb the mysteries of networks with AI
What helped the researchers achieve that feat is a key choice they made: they set out to build, or "synthesize," not just any general sort of computer program, but instead programs that are built out of "domain-specific languages." DSLs are languages that match in some way the data they process. For example, there are "data modeling" languages that help one represent the relationships in data. Yang is the name of one such data modeling language, for modeling computer networks. Unified Modeling Language, designed in the 1990s, lets one describe object-oriented computer programs.
By restricting their approach to DSLs, the authors narrow the "search space" for appropriate computer programs, thus improving their odds of finding a solution versus the more general approach of the Neural Turing Machine.
Also: Should AI researchers trust AI to vet their work?
Once the Bayesian inference procedure assembles some winning programs, these programs are then able to perform inference on the data. For example, the authors describe programs that suit an analysis of airline miles traveled over the years. This is a problem in time-series analysis for which the so-called Gaussian process of statistics is appropriate. So, their Bayesian inference synthesizes algorithms that incorporate Gaussian process operations to find a combination of those algorithms that has a likelihood of appropriately fitting the data.
A big benefit claimed by this approach is that unlike some general machine learning models, such as "convolutional neural networks," the programs assembled by this approach are in a sense interpretable, they are not the feared "black boxes" of AI. That's because the programs are domain-specific, so their very operations give away what they're finding in data. As the authors describe it, "The synthesized programs in the domain-specific language provide a compact model of the data that make qualitative properties apparent in the surface syntax of the program."
Must read
- 'AI is very, very stupid,' says Google's AI leader CNET
- Baidu creates Kunlun silicon for AI
- Unified Google AI division a clear signal of AI's future TechRepublic
At the same time, the authors show how to make these DSL programs able to generalize to new data. They use an interpreter program to convert the individual algorithms into something called Venture, a probabilistic programming language that is much more broad and general. Venture is then able to make inferences about data over a wider swath of applications.
There are tantalizing further directions for this work. In particular, the researchers note that their work could in future incorporate specific requirements by users as to how the data should be handled or analyzed. That suggests a kind of fusing of human intelligence about data with machine skills, perhaps an ideal union of person and AI.
Scary smart tech: 9 real times AI has given us the creeps
Previous and related coverage:
What is AI? Everything you need to know
An executive guide to artificial intelligence, from machine learning and general AI to neural networks.
What is deep learning? Everything you need to know
The lowdown on deep learning: from how it relates to the wider field of machine learning through to how to get started with it.
What is machine learning? Everything you need to know
This guide explains what machine learning is, how it is related to artificial intelligence, how it works and why it matters.
What is cloud computing? Everything you need to know about
An introduction to cloud computing right from the basics up to IaaS and PaaS, hybrid, public, and private cloud.