OpenAI’s gigantic GPT-3 hints at the limits of language models for AI

A little over a year ago, OpenAI, an artificial intelligence company based in San Francisco, stunned the world by showing a dramatic leap in what appeared to be the power of computers to form natural-language sentences, and even to solve questions, such as completing a sentence, and formulating long passages of text people found fairly human.
The latest work from that team shows how OpenAI's thinking has matured in some respects. GPT-3, as the newest creation is called, emerged last week, with more bells and whistles, created by some of the same authors as the last version, including Alec Radford and Ilya Sutskever, along with several additional collaborators, including scientists from Johns Hopkins University.
It is now a truly monster language model, as it's called, gobbling two orders of magnitude more text than its predecessor.
But within that bigger-is-better stunt, the OpenAI team seem to be approaching some deeper truths, much the way Dr. David Bowman approached the limits of the known at the end of the movie 2001.
Buried in the concluding section of the 72-page paper, Language Models are Few-Shot Learners, posted last week on the arXiv pre-print server, is a rather striking recognition.
"A more fundamental limitation of the general approach described in this paper – scaling up any LM-like model, whether autoregressive or bidirectional – is that it may eventually run into (or could already be running into) the limits of the pretraining objective," write the authors.
What the authors are saying is that building a neural network that just predicts probabilities of the next word in any sentence or phrase may have its limits. Just making it ever-more-powerful and stuffing it with ever-more-text may not yield better results. That's a significant acknowledgement within a paper that is mostly celebrating the achievement of throwing more computing horsepower at a problem.
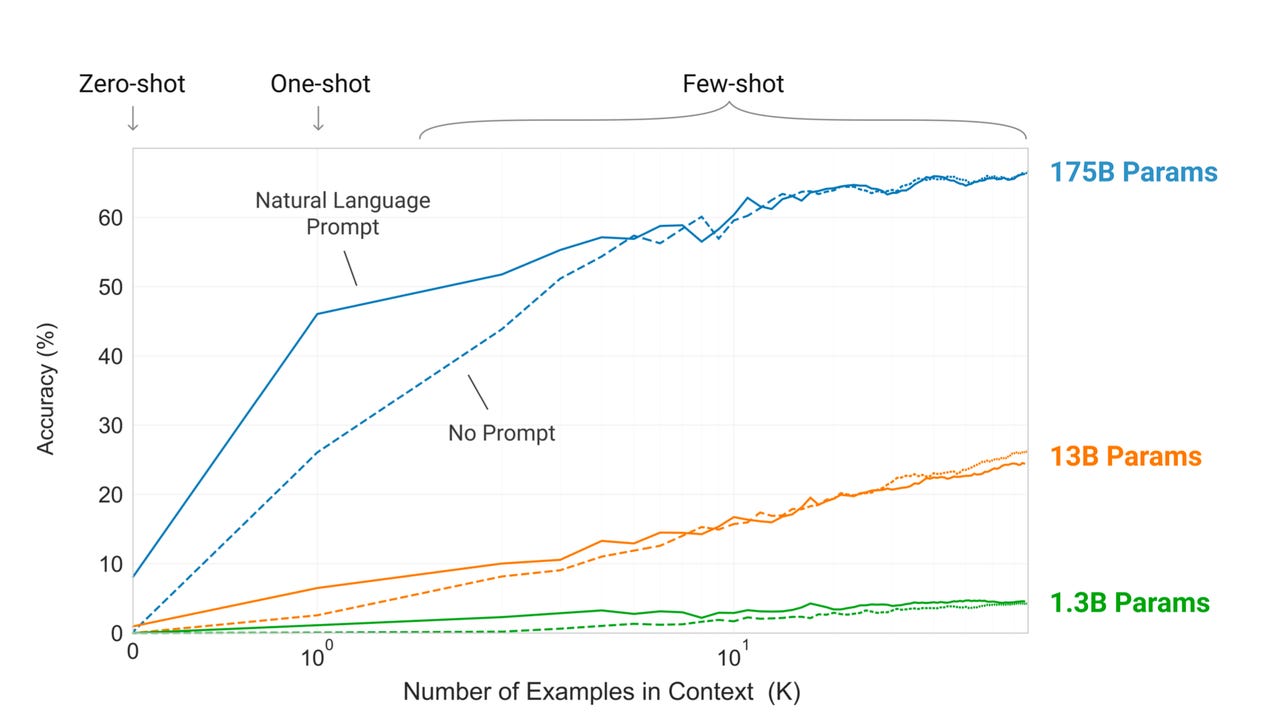
GPT-3 using 175 billion parameters rises to a level of accuracy faster than versions of it that use fewer parameters.
To understand why the authors' conclusion is so significant, consider how we got here. The history of OpenAI's work on language has been part of the history of a steady progression of one kind of approach, with increasing success as the technology was made bigger and bigger and bigger.
The original GPT, and GPT-2, are both adaptations of what's known as a Transformer, an invention pioneered at Google in 2017. The Transformer uses a function called attention to calculate the probability that a word will appear given surrounding words. OpenAI caused controversy a year ago when it said it would not release the source code to the biggest version of GPT-2, because, it said, that code could fall into the wrong hands and be abused to mislead people with things such as fake news.
The new paper takes GPT to the next level by making it even bigger. GPT-2's largest version, the one that was not posted in source form, was 1.5 billion parameters. GPT-3 is 175 billion parameters. A parameter is a calculation in a neural network that applies a great or lesser weighting to some aspect of the data, to give that aspect greater or lesser prominence in the overall calculation of the data. It is these weights that give shape to the data, and give the neural network a learned perspective on the data.
Increasing weights over time has led to amazIng benchmark test results by the GPT family of programs, and by other large Transformer derivatives, such as Google's BERT, results that have been consistently quite impressive.
Never mind that plenty of people have pointed out that none of these language models really seemed to be understanding language in any meaningful way. They're ace'ing tests, and that counts for something.
The latest version again shows quantitative progress. Like GPT-2 and other Transformer-based programs, GPT-3 is trained on the Common Crawl data set, a corpus of almost a trillion words of texts scraped from the Web. "The dataset and model size are about two orders of magnitude larger than those used for GPT-2," the authors write.
GPT-3 with 175 billion parameters is able to achieve what the authors describe as "meta-learning." Meta-learning means that the GPT neural net is not re-trained to perform a task such as sentence completion. Given an example of a task, such as an incomplete sentence, and then the completed sentence, GPT-3 will proceed to complete any incomplete sentence it's given.
GPT-3 is able to learn how to do a task with a single prompt, better, in some cases, than versions of Transformer that have been fine-tuned, as it were, to specifically perform only that task. Hence, GPT-3 is the triumph of an over-arching generality. Just feed it an enormous amount of text till its weights are ideal, and it can go on to perform pretty well on a number of specific tasks with no further development.
That's where the story comes to a striking denouement in the new paper. After listing off the impressive results of GPT-3 on language tasks ranging from completing sentences to inferring the logical entailment of statements to translating between languages, the authors note the shortcomings.
"Despite the strong quantitative and qualitative improvements of GPT-3, particularly compared to its direct predecessor GPT-2, it still has notable weaknesses."
Those weaknesses include an inability to achieve significant accuracy on what's called Adversarial NLI. NLI, or natural language inference, is a test where the program must determine the relationship between two sentences. Researchers from Facebook and University of North Carolina have introduced an adversarial version, where humans create sentence pairs that are hard for the computer to solve.
GPT-3 does "little better than chance" on things like Adversarial NLI, the authors write. Worse, having amped up the processing power of their system to 175 billion weights, the authors are not exactly sure why they've come up short in some tasks.
That's when they come to the conclusion, cited above, that perhaps simply feeding an enormous corpus of text to a gigantic machine is not the ultimate answer.
Even more startling is the next observation. The whole practice of trying to predict what's going to happen with language may be the wrong approach, the authors write. They may be aiming in the wrong place.
"With self-supervised objectives, task specification relies on forcing the desired task into a prediction problem," they write, "whereas ultimately, useful language systems (for example virtual assistants) might be better thought of as taking goal-directed actions rather than just making predictions."
The authors leave it for another time to specify how they'll take on this rather fascinating potential new direction.
Despite the reaiization that bigger may not ultimately be best, the improved results of GPT-3 on many tasks are likely to fuel, not abate, the desire for bigger and bigger neural networks. At 175 billion parameters, GPT-3 is the king of large neural networks, for the moment. A presentation in April by AI chip company Tenstorrent described future neural networks with over one trillion parameters.
For a good part of the machine learning community, bigger and bigger language modeling is going to remain the state of the art.