Teradata Puts Aster On Hadoop, Adds 'Listener' For IoT
Teradata puts Aster database on Hadoop to support 'multi-genre' analytics. New 'Listener' software collects and delivers high-volume, high-velocity data for IoT and other streaming scenarios.
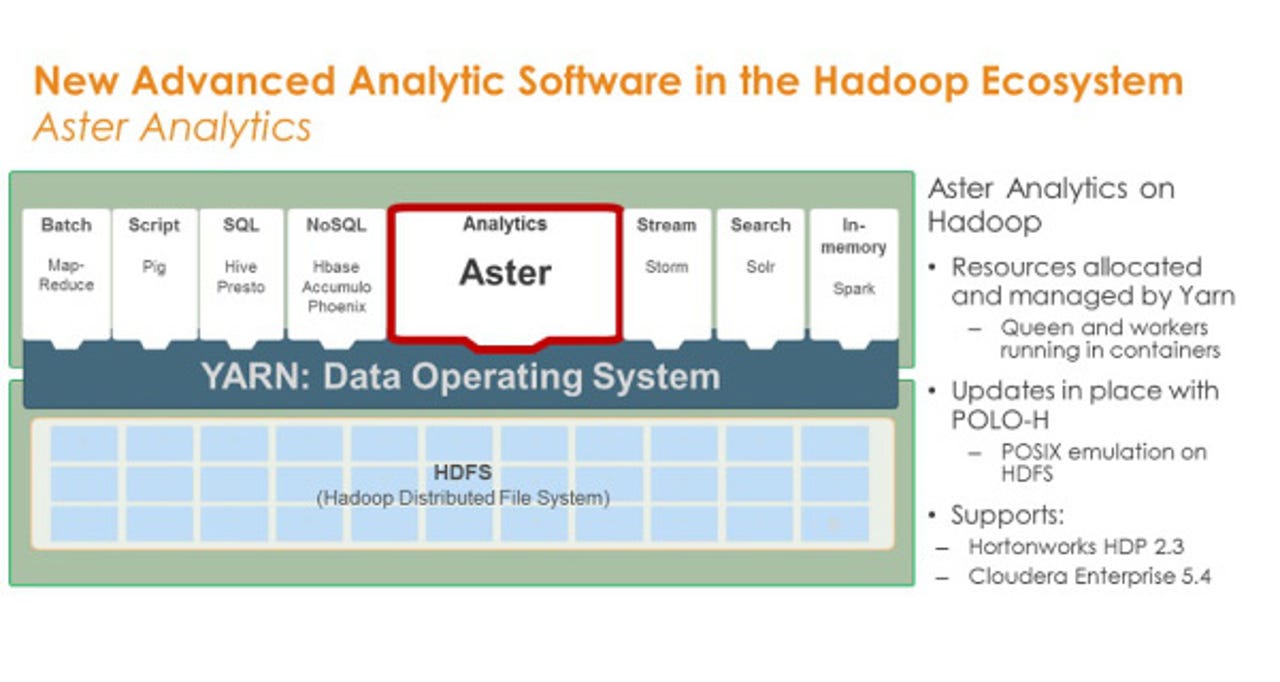
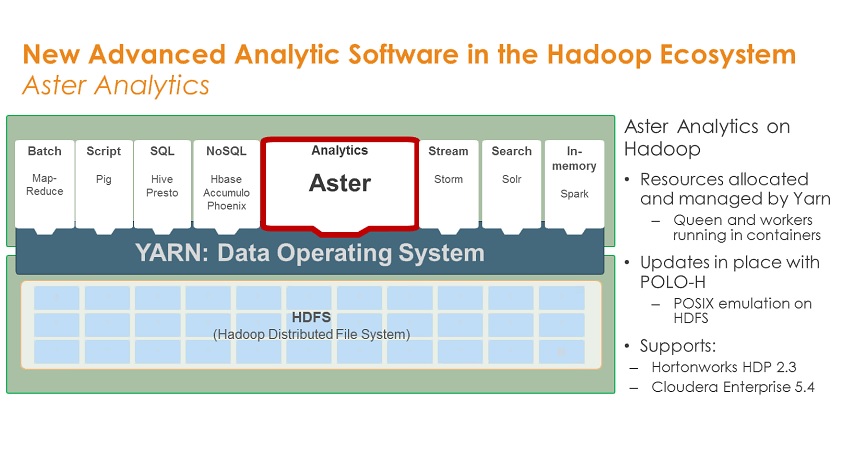
Teradata made a slew of announcements at this week's Teradata Partners conference in Anaheim, CA, but none is more significant than the news that the Teradata Aster database will soon be available to run on Hadoop.
Teradata acquired Aster back in 2011 for its ability to handle newer, variable data types, such as clickstreams, log files and social feeds with unconventional analyses (for a database) including MapReduce and pattern and path analysis. Teradata subsequently extended Aster's repertoire, adding support for graph analysis an in-database analytics based on the R language. Aster handles all of these analyses, as well as conventional querying, with SQL and SQL-like expressions, making it accessible to non-data scientists.
With Teradata Aster soon available to run on Hadoop, customers won't need separate infrastructure to gain Aster's diverse analytical capabilities.